This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data analytics has become a key driver of commercial success in recent years. The ability to turn largedata sets into actionable insights can mean the difference between a successful campaign and missed opportunities. Instead of seeing it as a prerequisite for using AI, we could use AI to improve dataquality itself.
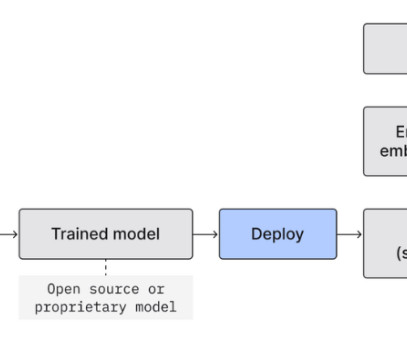
LLMOps versus MLOps Machine learning operations (MLOps) has been well-trodden, offering a structured pathway to transition machine learning (ML) models from development to production. While seemingly a variant of MLOps or DevOps, LLMOps has unique nuances catering to largelanguagemodels' demands.
To operate effectively, multimodal AI requires large amounts of high-qualitydata from multiple modalities, and inconsistent dataquality across modalities can affect the performance of these systems. 8B, that creates multiple possible interpretations of the input.
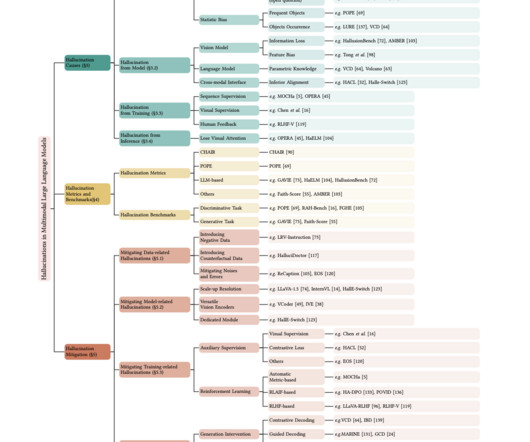
The emergence of largelanguagemodels (LLMs) such as Llama, PaLM, and GPT-4 has revolutionized natural language processing (NLP), significantly advancing text understanding and generation. Sources [link] The post Hallucination in LargeLanguageModels (LLMs) and Its Causes appeared first on MarkTechPost.
The research team introduced two model variants: Babel-9B, optimized for efficiency in inference and fine-tuning, and Babel-83B, which establishes a new benchmark in multilingual NLP. Unlike previous models, Babel includes widely spoken but often overlooked languages such as Bengali, Urdu, Swahili, and Javanese.
TL;DR Multimodal LargeLanguageModels (MLLMs) process data from different modalities like text, audio, image, and video. Compared to text-only models, MLLMs achieve richer contextual understanding and can integrate information across modalities, unlocking new areas of application.
Largelanguagemodels (LLMs) have achieved remarkable success across various domains, but training them centrally requires massive data collection and annotation efforts, making it costly for individual parties. Check out the Paper. All credit for this research goes to the researchers of this project.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. vector embedding Recent advances in largelanguagemodels (LLMs) like GPT-3 have shown impressive capabilities in few-shot learning and natural language generation.
This is doubly true for complex AI systems, such as largelanguagemodels, that process extensive datasets for tasks like language processing, image recognition, and predictive analysis. Only then can we raise the potential of AI and largelanguagemodel projects to breathtaking new heights.
The burgeoning expansion of the data landscape, propelled by the Internet of Things (IoT), presents a pressing challenge: ensuring dataquality amidst the deluge of information. However, the quality of that data is paramount, especially given the escalating reliance on Machine Learning (ML) across various industries.
These trends will elevate the role of data observability in ensuring that organizations can scale their AI initiatives while maintaining high standards for dataquality and governance. As organizations increasingly rely on AI to drive business decisions, the need for trustworthy, high-qualitydata becomes even more critical.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. What Is a LargeLanguageModel?
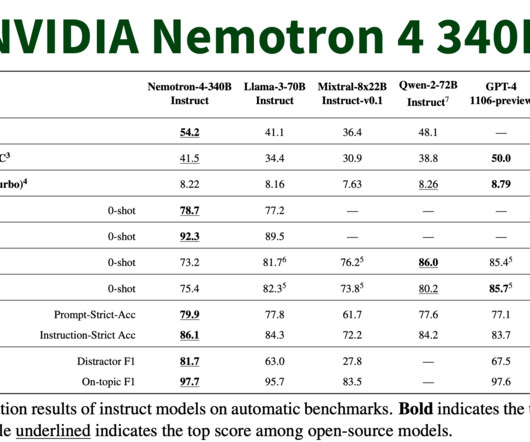
NVIDIA today announced Nemotron-4 340B, a family of open models that developers can use to generate synthetic data for training largelanguagemodels (LLMs) for commercial applications across healthcare, finance, manufacturing, retail and every other industry.
Advancements in largelanguagemodels (LLMs) have been witnessed across various domains, such as translation, healthcare, and code generation. These models have shown exceptional capabilities in understanding and generating human-like text. Europe, and Australia. If you like our work, you will love our newsletter.
Multimodal largelanguagemodels (MLLMs) represent a cutting-edge intersection of language processing and computer vision, tasked with understanding and generating responses that consider both text and imagery. Quantitative improvements in several key performance metrics underscore the efficacy of studied models.
These results highlight the impact of training data that didnt include enough diversity in skin tones. For example, largelanguagemodels (LLMs) such as OpenAIs GPT and Googles Bard are trained on datasets that heavily rely on English-language content predominantly sourced from Western contexts.
LargeLanguageModels have shown immense growth and advancements in recent times. The field of Artificial Intelligence is booming with every new release of these models. This is because vector embeddings are the only sort of data that a vector database is intended to store and retrieve.
Dataquality is a cornerstone for integrating largelanguagemodels (LLMs) into organizations. High-qualitydata is the lifeblood that ensures the accuracy, relevance, and reliability of the model's outputs. The adage "garbage in, garbage out" holds particularly true here.
Largelanguagemodels (LLMs) have become a pivotal part of artificial intelligence, enabling systems to understand, generate, and respond to human language. These models are used across various domains, including natural language reasoning, code generation, and problem-solving.
With the incorporation of largelanguagemodels (LLMs) in almost all fields of technology, processing large datasets for languagemodels poses challenges in terms of scalability and efficiency. If you like our work, you will love our newsletter.
However, one thing is becoming increasingly clear: advanced models like DeepSeek are accelerating AI adoption across industries, unlocking previously unapproachable use cases by reducing cost barriers and improving Return on Investment (ROI). Even the most advanced models will generate suboptimal outputs without properly contextualized input.
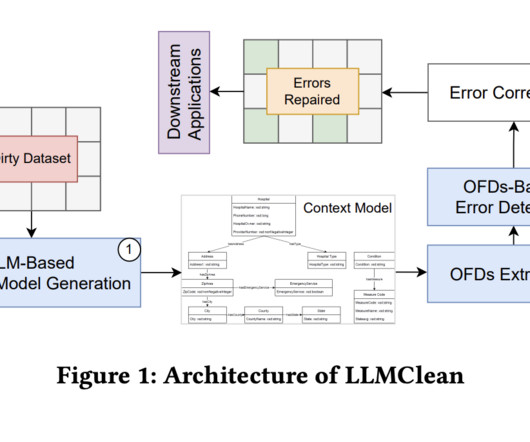
In this paper, they investigate how the dataquality might be improved along a different axis. Higher qualitydata produces better results; for instance, data cleaning is a crucial step in creating current datasets and can result in relatively smaller datasets or the ability to run the data through more iterations.
Addressing this gap will require a multi-faceted approach including grappling with issues related to dataquality and ensuring that AI systems are built on reliable, unbiased, and representative datasets. Companies have struggled with dataquality and data hygiene.
MLOps make ML models faster, safer, and more reliable in production. But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). They also need a lot of data to learn from, which can raise dataquality, privacy, and ethics issues.
Largelanguagemodels (LLMs) are central to processing vast amounts of data quickly and accurately. They depend critically on the quality of instruction tuning to enhance their reasoning capabilities. Securing high-quality, scalable instruction data remains a principal challenge in the domain.
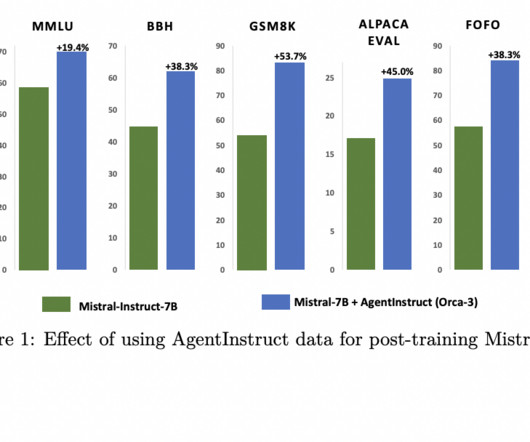
Largelanguagemodels (LLMs) have been instrumental in various applications, such as chatbots, content creation, and data analysis, due to their capability to process vast amounts of textual data efficiently. In conclusion, AgentInstruct represents a breakthrough in generating synthetic data for AI training.
More crucially, they include 40+ quality annotations — the result of multiple ML classifiers on dataquality, minhash results that may be used for fuzzy deduplication, or heuristics. They assert its coverage of CommonCrawl (84 processed dumps) is unparalleled. If you like our work, you will love our newsletter.
Developing and refining LargeLanguageModels (LLMs) has become a focal point of cutting-edge research in the rapidly evolving field of artificial intelligence, particularly in natural language processing. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
This involves various tasks such as image recognition, object detection, and visual search, where the goal is to develop models that can process and analyze visual data effectively. These models are trained on large datasets, often containing noisy labels and diverse dataquality.
These models are governed by scaling laws, suggesting that increasing model size and the amount of training data enhances performance. However, this improvement depends on the dataquality used, particularly when synthetic data is included in the training process.
NVIDIA has recently unveiled the Nemotron-4 340B , a groundbreaking family of models designed to generate synthetic data for training largelanguagemodels (LLMs) across various commercial applications.
“Managing dynamic dataquality, testing and detecting for bias and inaccuracies, ensuring high standards of data privacy, and ethical use of AI systems all require human oversight,” he said.
Largelanguagemodels (LLMs) like GPT-4, PaLM, and Llama have unlocked remarkable advances in natural language generation capabilities. Heavily depend on training dataquality and external knowledge sources. Difficulty in rigorous evaluation beyond limited domains. Metrics do not capture all nuances.
Microsoft researchers have pioneered a groundbreaking approach in the realm of code languagemodels, introducing CodeOcean and WaveCoder to redefine instruction tuning.
According to Microsoft research, around 88% of the world's languages , spoken by 1.2 billion people, lack access to LargeLanguageModels (LLMs). This is because most LLMs are English-centered, i.e., they are mostly built with English data and for English speakers. Let's explore a few of them: 1.
DAOs also capture detailed descriptions of ID documents, ensuring accurate data validation and security checks at scale. Leveraging largelanguagemodels and multimodal models in conjunction with our DAO database, we can effectively generalize at scale while maintaining the necessary specificity for individual ID documents.
LLMs are one of the most exciting advancements in natural language processing (NLP). The idea behind ensembling is that by combining the outputs of multiple models, the final prediction can be more accurate and reliable than the prediction made by a single model.
The advancements in largelanguagemodels have significantly accelerated the development of natural language processing , or NLP. More recent frameworks like LLaMA and BLIP leverage tailored instruction data to devise efficient strategies that demonstrate the potent capabilities of the model.
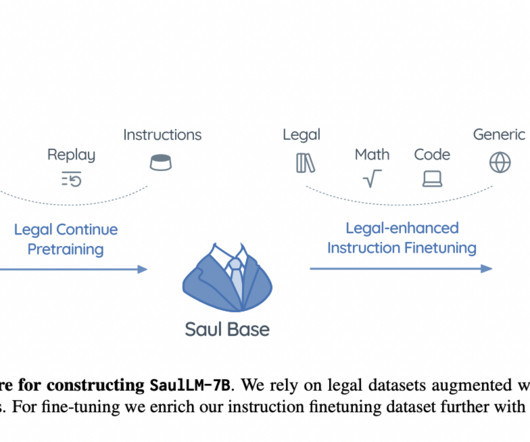
Key Insights and Best Practices on Instruction Tuning By Florian June This article provides insights and best practices for instruction tuning in largelanguagemodels (LLMs). It covers key considerations like balancing dataquality versus quantity, ensuring data diversity, and selecting the right tuning method.
Multimodal LargeLanguageModels (MLLMs) have advanced the integration of visual and textual modalities, enabling progress in tasks such as image captioning, visual question answering, and document interpretation. However, the replication and further development of these models are often hindered by a lack of transparency.
As the demand for generative AI grows, so does the hunger for high-qualitydata to train these systems. Scholarly publishers have started to monetize their research content to provide training data for largelanguagemodels (LLMs).
This data makes sure models are being trained smoothly and reliably. If failures increase, it may signal issues with dataquality, model configurations, or resource limitations that need to be addressed. Execution status – You can monitor the progress of training jobs, including completed tasks and failed runs.
Largelanguagemodels have been game-changers in artificial intelligence, but the world is much more than just text. These languagemodels are breaking boundaries, venturing into a new era of AI — Multi-Modal Learning. However, the influence of largelanguagemodels extends beyond text alone.
Companies still often accept the risk of using internal data when exploring largelanguagemodels (LLMs) because this contextual data is what enables LLMs to change from general-purpose to domain-specific knowledge. In the generative AI or traditional AI development cycle, data ingestion serves as the entry point.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content