This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
For example, in the bank marketing use case, the management account would be responsible for setting up the organizational structure for the bank’s data and analytics teams, provisioning separate accounts for data governance, data lakes, and datascience teams, and maintaining compliance with relevant financial regulations.
Manufacturers must adopt strict cybersecurity practices to protect their data while adhering to regulatory requirements, maintaining trust, and safeguarding their operations. DataQuality and Preprocessing The effectiveness of AI applications in manufacturing heavily depends on the quality of the data fed into the models.
Structured synthetic data types are quantitative and includes tabular data, such as numbers or values, while unstructured synthetic data types are qualitative and includes text, images, and video. How to get started with synthetic data in watsonx.ai
These organizations are shaping the future of the AI and datascience industries with their innovative products and services. Taipy brings to bear the experience of veteran datascientists and bridges the gap between data dashboards and full AI applications. Check them out below.
In the ever-expanding world of datascience, the landscape has changed dramatically over the past two decades. Once defined by statistical models and SQL queries, todays data practitioners must navigate a dynamic ecosystem that includes cloud computing, software engineering best practices, and the rise of generative AI.
Axfood has a structure with multiple decentralized datascience teams with different areas of responsibility. Together with a central data platform team, the datascience teams bring innovation and digital transformation through AI and ML solutions to the organization.
A Comprehensive DataScience Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets This member-only story is on us. In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere!
DataScience is the process in which collecting, analysing and interpreting large volumes of data helps solve complex business problems. A DataScientist is responsible for analysing and interpreting the data, ensuring it provides valuable insights that help in decision-making.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. It provides a high-level API that makes it easy to define and execute datascience workflows.
Summary: DataScience appears challenging due to its complexity, encompassing statistics, programming, and domain knowledge. However, aspiring datascientists can overcome obstacles through continuous learning, hands-on practice, and mentorship. However, many aspiring professionals wonder: Is DataScience hard?
MLOps practitioners have many options to establish an MLOps platform; one among them is cloud-based integrated platforms that scale with datascience teams. TWCo datascientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively.
The advent of big data, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in datascience across industries. However, research shows that up to 85% of datascience projects fail to move beyond proofs of concept to full-scale deployment.
Summary: The DataScience and Data Analysis life cycles are systematic processes crucial for uncovering insights from raw data. Qualitydata is foundational for accurate analysis, ensuring businesses stay competitive in the digital landscape. billion INR by 2026, with a CAGR of 27.7%. billion INR by 2027.
Learn how DataScientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of natural language processing, modeling, data analysis, data cleaning, and data visualization. It facilitates exploratory Data Analysis and provides quick insights.
Summary: The healthcare industry is undergoing a data-driven revolution. DataScience is analyzing vast amounts of patient information to predict diseases before they strike, personalize treatment plans based on individual needs, and streamline healthcare operations. quintillion bytes of data each year [source: IBM].
Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. Introduction Imagine a world where data is a messy jungle, and we need smart tools to turn it into useful insights.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. DataScientist with AWS Professional Services. Raju Patil is a Sr.
This calls for the organization to also make important decisions regarding data, talent and technology: A well-crafted strategy will provide a clear plan for managing, analyzing and leveraging data for AI initiatives. Talent and outsourcing : Assess the readiness of and skills gaps within the organization to implement AI initiatives.
Not only is LXT an AI data provider that is growing at an impressive and consistent pace, but I also saw it as at the perfect stage in terms of growth in AI know-how as well as in client size and diversity, and hence in AI and AI data types. What does your average day at LXT look like?
DataScience helps businesses uncover valuable insights and make informed decisions. Programming for DataScience enables DataScientists to analyze vast amounts of data and extract meaningful information. 8 Most Used Programming Languages for DataScience 1.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. What initially attracted you to computer science? What we have done is we have actually created this configuration where you are able to pick from a large list of options.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst.
At Astronomer, he spearheads the creation of Apache Airflow features specifically designed for ML and AI teams and oversees the internal datascience team. Can you share some information about your journey in datascience and AI, and how it has shaped your approach to leading engineering and analytics teams?
John Snow Labs Debuts Comprehensive Healthcare Data Library on Databricks Marketplace: Over 2,400 Expertly Curated, Clean, and Enriched Datasets Now Accessible, Amplifying DataScience Capabilities in Healthcare and Life Sciences.
Summary : This article equips Data Analysts with a solid foundation of key DataScience terms, from A to Z. Introduction In the rapidly evolving field of DataScience, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
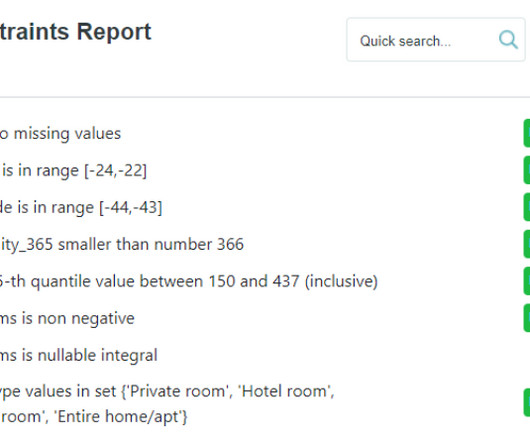
Let’s download the dataframe with: import pandas as pd df_target = pd.read_parquet("[link] /Listings/airbnb_listings_target.parquet") Let’s simulate a scenario where we want to assert the quality of a batch of production data. These constraints operate on top of statistical summaries of data, rather than on the raw data itself.
In general, machine learning engineers and datascientists use the term “last mile” to describe the process of preparing an AI solution for broad and universal use. Here are just a few: Dataquality. Ensuring dataquality and consistency is critical to maintaining model robustness. Concept drift.
Networking Always a highlight and crowd-pleasure of ODSC conferences, the networking events Monday-Wednesday were well-deserved after long days of datascience training sessions. Other Events Aside from networking events and all of our sessions, we had a few other special events.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to datascience. Data Wrangler creates the report from the sampled data.
AI and datascience are witnessing rapid growth, revolutionizing industries and creating new opportunities for innovation. As organizations increasingly rely on data-driven decision-making, the demand for skilled professionals in this field is skyrocketing. Interested in attending an ODSC event?
With SageMaker MLOps tools, teams can easily train, test, troubleshoot, deploy, and govern ML models at scale to boost productivity of datascientists and ML engineers while maintaining model performance in production. Data Management – Efficient data management is crucial for AI/ML platforms.
This blog explores their strategies, including custom chunking techniques, hybrid retrieval methods, and robust development frameworks designed for seamless collaboration between datascientists and machine learning engineers. Key Takeaways Dataquality is critical for effective RAG implementation.
This architecture design represents a multi-account strategy where ML models are built, trained, and registered in a central model registry within a datascience development account (which has more controls than a typical application development account).
In June 2024, Databricks made three significant announcements that have garnered considerable attention in the datascience and engineering communities. These announcements focus on enhancing user experience, optimizing data management, and streamlining data engineering workflows.
. ▢ [Automation] Does the existing platform helps the datascientist to quickly analyze, visualize the data and automatically detect common issues ▢ [Automation] Does the existing platform allows integrating and visualizing the relationship between datasets from multiple sources?▢ Source: Image by the author.
In contrast, data warehouses and relational databases adhere to the ‘Schema-on-Write’ model, where data must be structured and conform to predefined schemas before being loaded into the database. You can also get datascience training on-demand wherever you are with our Ai+ Training platform.
Machine learning and AI empower organizations to analyze data, discover insights, and drive decision making from troves of data. Datascientists need to understand the business problem and the project scope to assess feasibility, set expectations, define metrics, and design project blueprints. Assess the infrastructure.
You’ll explore data ingestion from multiple sources, preprocessing unstructured data into a normalized format that facilitates uniform chunking across various file types, and metadata extraction. You’ll also discuss loading processed data into destination storage. Sign me up! Are you intrigued?
Knowing them and adopting the right way to overcome these will help you become a proficient datascientist. 10 Mistakes That a Data Analyst May Make Failing to Define the Problem Identifying the problem area is significant. However, many datascientist fail to focus on this aspect.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
There’s something for any builder, from datascience projects to developing AI models. They also explore the technical aspects of chunking strategies and dataquality in RAG systems. Hayley121995 is looking for datascientists and ML enthusiasts to join their AI research projects. It is a paid opportunity.
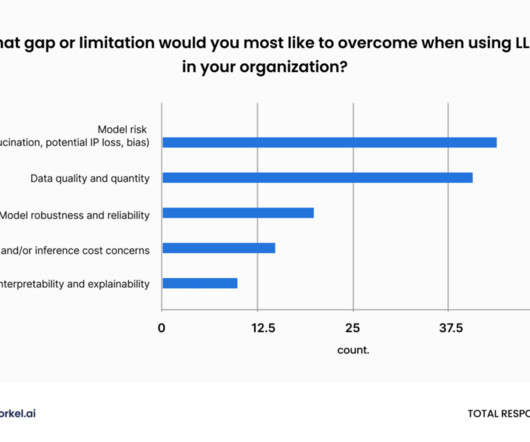
LLM distillation will become a much more common and important practice for datascience teams in 2024, according to a poll of attendees at Snorkel AI’s 2023 Enterprise LLM Virtual Summit. As datascience teams reorient around the enduring value of small, deployable models, they’re also learning how LLMs can accelerate data labeling.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content