This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
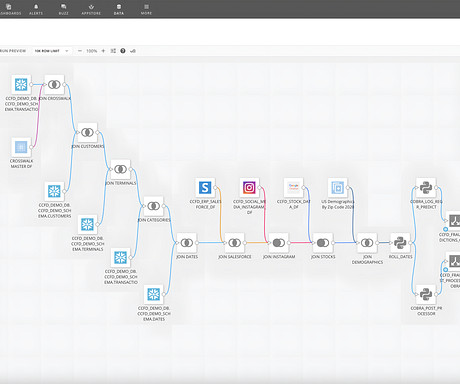
To start, get to know some key terms from the demo: Snowflake: The centralized source of truth for our initial data Magic ETL: Domo’s tool for combining and preparing data tables ERP: A supplemental data source from Salesforce Geographic: A supplemental data source (i.e., Instagram) used in the demo Why Snowflake?
The solution harnesses the capabilities of generative AI, specifically Large Language Models (LLMs), to address the challenges posed by diverse sensor data and automatically generate Python functions based on various data formats. The solution only invokes the LLM for new device data file type (code has not yet been generated).
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. All of them are written in Python. This is where feature stores come in.
Dagster Supports end-to-end data management lifecycle. Its software-defined assets (announced through Rebundling the DataPlatform ) and built-in lineage make it an appealing tool for developers. Seamless integration with many data sources and destinations. Uses secure protocols for data security.
Data Warehousing and ETL Processes What is a data warehouse, and why is it important? A data warehouse is a centralised repository that consolidates data from various sources for reporting and analysis. It is essential to provide a unified data view and enable business intelligence and analytics.
Arjuna Chala, associate vice president, HPCC Systems For those not familiar with the HPCC Systems data lake platform, can you describe your organization and the development history behind HPCC Systems? They were interested in creating a dataplatform capable of managing a sizable number of datasets.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for dataplatform Setting up the DataPlatform in the right way is key to the success of an ML Platform. In the following sections, we will discuss best practices while setting up a DataPlatform for Retail.
Stefan is a software engineer, data scientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton. You could almost think of Hamilton as DBT for Python functions. It gives a very opinionary way of writing Python.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content