This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A lakehouse should make it easy to combine new data from a variety of different sources, with mission critical data about customers and transactions that reside in existing repositories. Also, a lakehouse can introduce definitional metadata to ensure clarity and consistency, which enables more trustworthy, governed data.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities. Later this year, it will leverage watsonx.ai
Datascientists from ML teams across different business units federate into their team’s development environment to build the model pipeline. Datascientists search and pull features from the central feature store catalog, build models through experiments, and select the best model for promotion.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
As a result, it’s easier to find problems with data quality, inconsistencies, and outliers in the dataset. Metadata analysis is the first step in establishing the association, and subsequent steps involve refining the relationships between individual database variables.
Among those algorithms, deep/neural networks are more suitable for e-commerce forecasting problems as they accept item metadata features, forward-looking features for campaign and marketing activities, and – most importantly – related time series features. He loves combining open-source projects with cloud services.
This Lambda function identifies CTR records and provides an additional processing step that outputs an enhanced transcript containing additional metadata such as queue and agent ID information, IVR identification and tagging, and how many agents (and IVRs) the customer was transferred to, all aggregated from the CTR records.
The examples focus on questions on chunk-wise business knowledge while ignoring irrelevant metadata that might be contained in a chunk. About the authors Samantha Stuart is a DataScientist with AWS Professional Services, and has delivered for customers across generative AI, MLOps, and ETL engagements.
Best-Practice Compliance and Governance: Businesses need to know that their DataScientists are delivering models that they can trust and defend over time. Broad Enterprise Ecosystem – The DataRobot AI Platform is an open system supporting key integrations to help businesses maximize value from their existing investments.
You may also like Building a Machine Learning Platform [Definitive Guide] Consideration for dataplatform Setting up the DataPlatform in the right way is key to the success of an ML Platform. In the following sections, we will discuss best practices while setting up a DataPlatform for Retail.
This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data. Regardless, the data fabric must be consistent for all its components. Data fabric needs metadata management maturity.
This is Piotr Niedźwiedź and Aurimas Griciūnas from neptune.ai , and you’re listening to ML Platform Podcast. Stefan is a software engineer, datascientist, and has been doing work as an ML engineer. He also ran the dataplatform in his previous company and is also co-creator of open-source framework, Hamilton.
So I tell people honestly, I’ve spent the last eight years working up and down the data and ML value chain effectively – a fancy way of saying “job hopping.” How to transition from data analytics to MLOps engineering Piotr: Miki, you’ve been a datascientist, right? Quite fun, quite chaotic at times.
Furthermore, a shared-data approach stems from this efficient combination. The background for the Snowflake architecture is metadata management, so customers can enjoy an additional opportunity to share cloud data among users or accounts. Superior data protection.
Spark offered a more versatile programming model, supporting not only MapReduce-like batch processing but also real-time stream processing and interactive data queries. Its ability to efficiently handle iterative algorithms and machine learning tasks made it a popular choice for datascientists and engineers.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard. Then, it applies these insights to automate and orchestrate the data lifecycle.
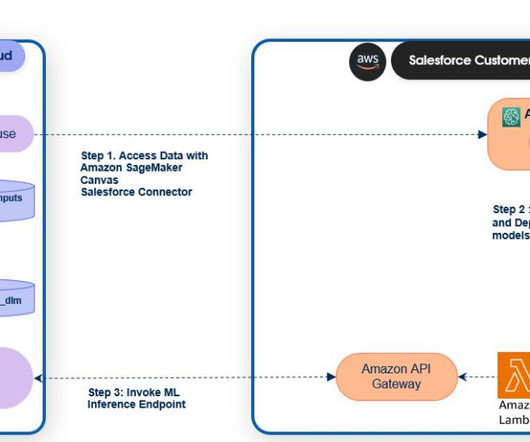
SageMaker endpoints can be registered to the Salesforce Data Cloud to activate predictions in Salesforce. Salesforce Data Cloud and Einstein Studio Salesforce Data Cloud is a dataplatform that provides businesses with real-time updates of their customer data from any touch point.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content