This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Large language models (LLMs) have revolutionized natural language processing (NLP), enabling various applications, from conversational assistants to content generation and analysis. However, working with LLMs can be challenging, requiring developers to navigate complex prompting, dataintegration, and memory management tasks.
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Data ingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
Effective dataintegration is equally important. To ensure the highest degree of accuracy, we implemented rigorous validation checks, transforming raw data into actionable insights while avoiding the pitfalls of garbage in, garbage out. Random Forest Algorithms : Utilizing decision-tree models for enhanced prediction accuracy.
Intelligent insights and recommendations Using its large knowledge base and advanced natural language processing (NLP) capabilities, the LLM provides intelligent insights and recommendations based on the analyzed patient-physician interaction. These insights can include: Potential adverse event detection and reporting.
Traditional Databases : Structured Data Storage : Traditional databases, like relational databases, are designed to store structured data. This means data is organized into predefined tables, rows, and columns, ensuring dataintegrity and consistency.
co-founder says data centers will be less energy-intensive in the future as artificial intelligence makes computations more efficient. bloomberg.com CData scores $350M as dataintegration needs surge in the age of AI In the race to adopt AI and gain a competitive edge, enterprises are making substantial investments.
Synthetic data , artificially generated to mimic real data, plays a crucial role in various applications, including machine learning , data analysis , testing, and privacy protection. However, generating synthetic data for NLP is non-trivial, demanding high linguistic knowledge, creativity, and diversity.
Drawbacks: Latency: Fetching and processing external data can slow down response times. Dependency on Retrievers: Performance hinges on the quality and relevance of retrieved data. Integration Complexity: Requires seamless integration between the retriever and generator components. Citations: Lewis, P.,
Some of the leading generative AI playgrounds are: Hugging Face: Hugging Face is a leading generative AI playground, especially renowned for its natural language processing (NLP) capabilities. It offers a comprehensive library of pre-trained AI models, datasets, and tools, making it easier to create and deploy AI applications.
In Natural Language Processing (NLP) tasks, data cleaning is an essential step before tokenization, particularly when working with text data that contains unusual word separations such as underscores, slashes, or other symbols in place of spaces. The post Is There a Library for Cleaning Data before Tokenization?
NLP in particular has been a subfield that has been focussed heavily in the past few years that has resulted in the development of some top-notch LLMs like GPT and BERT. Artificial Intelligence is a very vast branch in itself with numerous subfields including deep learning, computer vision , natural language processing , and more.
Their work has set a gold standard for integrating advanced natural language processing (NLP ) into clinical settings. Measuring LLMSuccess Evaluating large language models in healthcare often startswith: Benchmark performance on standardized NLP datasets. Peer-reviewed research to validate theoretical accuracy.
Ring 3 uses the capabilities of Ring 1 and Ring 2, including the dataintegration capabilities of the platform for terminology standardization and person matching. This also supports the capabilities to insert actionable insights and care plan updates directly into the provider care flow within the Electronic Medical Record (EMR).
The agent uses natural language processing (NLP) to understand the query and uses underlying agronomy models to recommend optimal seed choices tailored to specific field conditions and agronomic needs. What corn hybrids do you suggest for my field?”.
Healthcare agents can integrate LLM models and call external functions or APIs through a series of steps: natural language input processing , self-correction, chain of thought, function or API calling through an integration layer, dataintegration and processing, and persona adoption.
In this post, we propose an end-to-end solution using Amazon Q Business to address similar enterprise data challenges, showcasing how it can streamline operations and enhance customer service across various industries. The Process Data Lambda function redacts sensitive data through Amazon Comprehend.
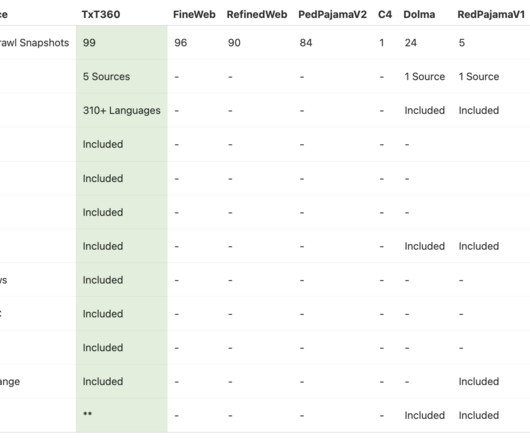
Each of these specialized sources went through tailored pipelines to preserve dataintegrity and quality, ensuring that the resulting language models can handle a wide range of topics. TxT360: A New Era for Open-Source AI The release of TxT360 marks a significant leap forward in AI and NLP research.
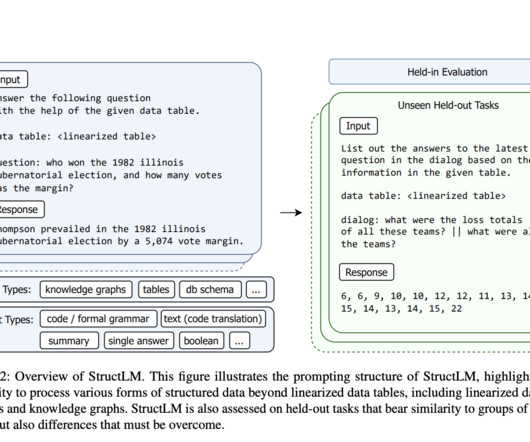
We cannot deny the significant strides made in natural language processing (NLP) through large language models (LLMs). This deficiency underscores the need for newer, more innovative approaches to enhance LLMs’ structured knowledge grounding (SKG) capabilities, enabling them to comprehend and utilize structured data more effectively.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and dataintegrity in the secure AWS environment. is the Head of Applied NLP Research at Arcee. Shamane Siri Ph.D.
Her overall work focuses on Natural Language Processing (NLP) research and developing NLP applications for AWS customers, including LLM Evaluations, RAG, and improving reasoning for LLMs. Prior to Amazon, Evangelia completed her Ph.D. at Language Technologies Institute, Carnegie Mellon University.
Exploring LangChain LangChain is a helpful framework designed to simplify AI models' development, integration, and deployment, particularly those focused on Natural Language Processing (NLP) and conversational AI.
Using Natural Language Processing (NLP) and the latest AI models, Perplexity AI moves beyond keyword matching to understand the meaning behind questions. Interact with data: Analyze uploaded files and answer questions about the data, integrating seamlessly with web searches for a complete view.
With seven years of experience in AI/ML, his expertise spans GenAI and NLP, specializing in designing and deploying agentic AI systems. With expertise in GenAI and NLP, he focuses on designing and deploying intelligent systems that enhance automation and decision-making.
By processing data closer to where it resides, SnapLogic promotes faster, more efficient operations that meet stringent regulatory requirements, ultimately delivering a superior experience for businesses relying on their dataintegration and management solutions. He currently is working on Generative AI for dataintegration.
Important Milestones Integration of Machine Learning: The adoption of machine learning enabled AI agents to identify patterns in large datasets, making them more responsive and effective in various applications. Data Quality and Bias: The effectiveness of AI agents depends on the quality of the data they are trained on.
These development platforms support collaboration between data science and engineering teams, which decreases costs by reducing redundant efforts and automating routine tasks, such as data duplication or extraction. Store operating platform : Scalable and secure foundation supports AI at the edge and dataintegration.
In this post, we demonstrate how data aggregated within the AWS CCI Post Call Analytics solution allowed Principal to gain visibility into their contact center interactions, better understand the customer journey, and improve the overall experience between contact channels while also maintaining dataintegrity and security.
Here are a few examples across various domains: Natural Language Processing (NLP) : Predictive NLP models can categorize text into predefined classes (e.g., spam vs. not spam), while generative NLP models can create new text based on a given prompt (e.g., a social media post or product description).
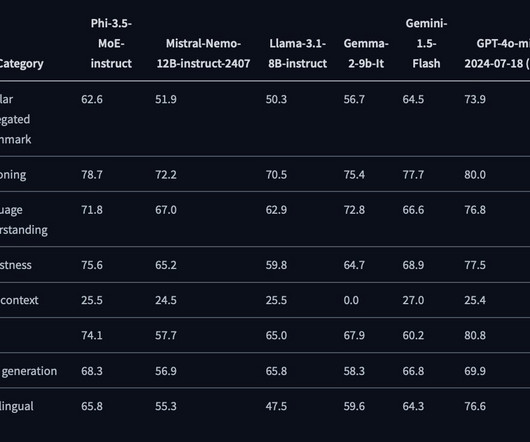
The model’s architecture also allows it to outperform larger models in reasoning tasks while maintaining competitive performance across various NLP benchmarks. Vision Instruct sets a new standard in multimodal AI, enabling advanced visual and textual dataintegration for complex tasks. Finally, Phi 3.5 MoE-instruct.
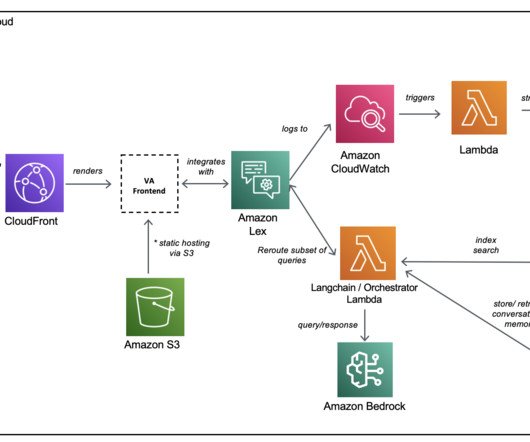
Each request/response interaction is facilitated by the AWS SDK and sends network traffic to Amazon Lex (the NLP component of the bot). As an Information Technology Leader, Jay specializes in artificial intelligence, dataintegration, business intelligence, and user interface domains.
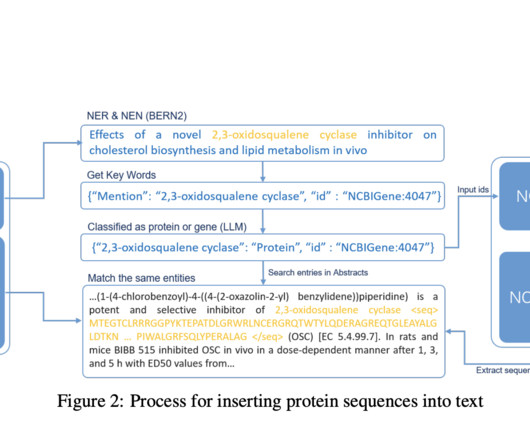
LLMs have excelled in NLP tasks, and this success has inspired attempts to adapt them to understanding proteins. The literature review highlights key limitations in existing datasets and NLP and protein sequence benchmarks.
Each of these creates visualizations and reports based on data stored in a database. They often provide drag-and-drop interfaces that allow non-technical users to create reports and dashboards using SQL queries as the underlying data source. Dataintegration tools allow for the combining of data from multiple sources.
Natural Language Processing (NLP) and Text Mining: Healthcare data includes vast amounts of unstructured information in clinical notes, research articles, and patient narratives. Data scientists and machine learning engineers employ NLP techniques and text-mining algorithms to process and analyze this textual data.
How have your experiences at companies like Comcast, Elsevier, and Microsoft influenced your approach to integrating AI and search technologies? Throughout my career, I have been deeply focused on natural language processing (NLP) techniques and machine learning.
SSL is a powerful technique for extracting meaningful patterns from large, unlabelled datasets, proving transformative in fields like computer vision and NLP. In single-cell genomics (SCG), SSL offers significant potential for analyzing complex biological data, especially with the advent of foundation models.
This technology has broad applications, including aiding individuals with visual impairments, improving image search algorithms, and integrating optical recognition with advanced language generation to enhance human-machine interactions. NLP enables computers to comprehend and generate coherent sentences.
Automatic Data Capture: Streamlining Data Entry with AI AI has the remarkable ability to extract data without manual intervention, allowing employees to focus on more critical tasks, such as customer interactions. Predictive Data Quality Machine learning models can predict data quality issues before they become critical.
This multi-faceted approach to data analysis allows for more accurate demand forecasting and inventory optimization, helping businesses reduce costs associated with overstocking or stockouts. IBM Supply Chain is designed to be scalable and adaptable, making it suitable for businesses of various sizes across different industries.
Summary: Artificial Intelligence (AI) is revolutionising Genomic Analysis by enhancing accuracy, efficiency, and dataintegration. Despite challenges like data quality and ethical concerns, AI’s potential in genomics continues to grow, shaping the future of healthcare.
LLMs are one of the most exciting advancements in natural language processing (NLP). LLMs are trained on massive amounts of text data, allowing them to generate highly accurate predictions and responses. Tokenization: Tokenization is a crucial step in data preparation for natural language processing (NLP) tasks.
Manning Contact : jennyhong@cs.stanford.edu Keywords : legal nlp, information extraction, weak supervision Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser Authors : Yuta Koreeda, Christopher D.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and natural language processing (NLP) to read and understand a document and extract specific entities or phrases. Use AWS KMS encryption in Amazon Comprehend – Amazon Comprehend works with AWS KMS to provide enhanced encryption for your data.
This dramatically reduces the size of data while capturing features that characterize the equipment’s behavior. Figure 1: Sample of HVAC sensor data AWS Glue is a serverless dataintegration service for processing large quantities of data at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content