This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
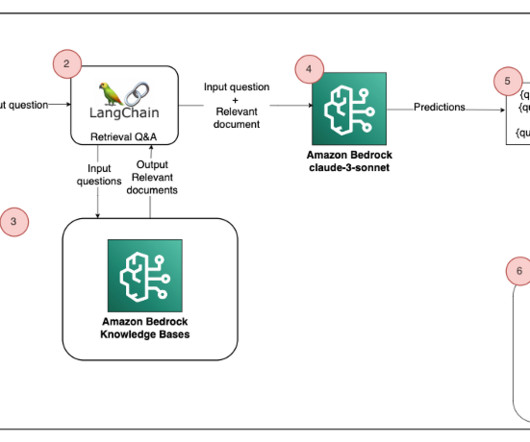
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLMintegration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
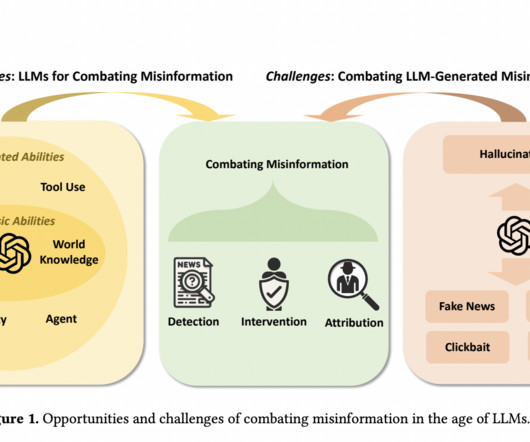
Introduction Large language models (LLMs) have revolutionized natural language processing (NLP), enabling various applications, from conversational assistants to content generation and analysis. However, working with LLMs can be challenging, requiring developers to navigate complex prompting, dataintegration, and memory management tasks.
To deal with this issue, various tools have been developed to detect and correct LLM inaccuracies. Pythia Image source Pythia uses a powerful knowledge graph and a network of interconnected information to verify the factual accuracy and coherence of LLM outputs. Dataintegrity auditing techniques to identify biases.
Patients, healthcare providers, and researchers require intelligent agents that can provide up-to-date, personalized, and context-aware support, drawing from the latest medical knowledge and individual patient data. Amazon Bedrock supports a variety of foundation models.
Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training large language models. It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown.
Currently, no standardized process exists for overcoming data ingestion’s challenges, but the model’s accuracy depends on it. Challenges in rectifying biased data: If the data is biased from the beginning, “ the only way to retroactively remove a portion of that data is by retraining the algorithm from scratch.”
This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation. AWS Glue is a serverless dataintegration service that makes it straightforward for analytics users to discover, prepare, move, and integratedata from multiple sources.
We started from a blank slate and built the first native large language model (LLM) customer experience intelligence and service automation platform. This makes us the central hub, collecting data from all these sources and serving as the intelligence layer on top.
LlamaIndex is a framework for building LLM applications. It simplifies dataintegration from various sources and provides tools for data indexing, engines, agents, and application integrations. Optimized for search and retrieval, it streamlines querying LLMs and retrieving documents.
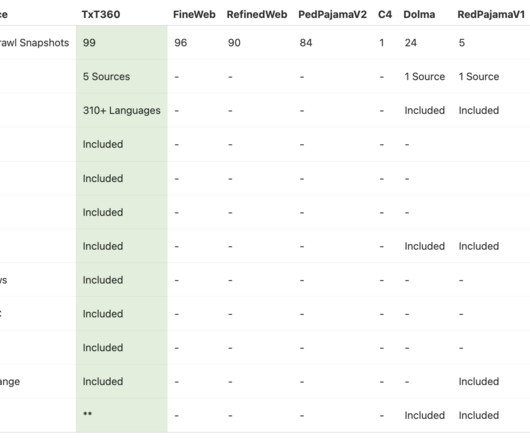
Each of these specialized sources went through tailored pipelines to preserve dataintegrity and quality, ensuring that the resulting language models can handle a wide range of topics. TxT360: A New Era for Open-Source AI The release of TxT360 marks a significant leap forward in AI and NLP research.
70B NVIDIA NIM microservice, running on NVIDIA DGX systems , which accelerated LLM inference 4x compared with the native model. The researchers’ AI-powered dataintegration and predictive analytics tool, AMRSense, improves accuracy and speeds time to insights on antimicrobial resistance.
When framed in the context of the Intelligent Economy RAG flows are enabling access to information in ways that facilitate the human experience, saving time by automating and filtering data and information output that would otherwise require significant manual effort and time to be created.
As generative AI continues to grow, the need for an efficient, automated solution to transform various data types into an LLM-ready format has become even more apparent. Meet MegaParse : an open-source tool for parsing various types of documents for LLM ingestion. Don’t Forget to join our 60k+ ML SubReddit.
Setting the Stage: Why Augmentation Matters Imagine youre chatting with an LLM about complex topics like medical research or historical events. Drawbacks: Latency: Fetching and processing external data can slow down response times. Dependency on Retrievers: Performance hinges on the quality and relevance of retrieved data.
This can result in biased outcomes and hinder the effectiveness of LLMs on other tasks. Improper cleaning of training data or a lack of representation of real-world data in testing can lead to data contamination. Data contamination can negatively impact LLM performance in various ways.
This data governance requires us to understand the origin, sensitivity, and lifecycle of all the data that we use. Risks of training LLM models on sensitive data Large language models can be trained on proprietary data to fulfill specific enterprise use cases. and watsonx.data.
So, it’s possible that even medically-tuned LLMs or general foundation LLMs won’t be able to use this data when reasoning about and suggesting therapies based on individualized health behaviors. Following refinement from the exceptional Gemini Ultra 1.0, All human experts, Gemini Ultra 1.0,
DataIntegrity: The Foundation for Trustworthy AI/ML Outcomes and Confident Business Decisions Let’s explore the elements of dataintegrity, and why they matter for AI/ML. The World’s First Open Instruction-Tuned LLM Databricks released Dolly 2.0, Databricks Introduces Dolly 2.0:
This issue is pronounced in environments where dataintegrity and confidentiality are paramount. Existing research in Robotic Process Automation (RPA) has focused on rule-based systems like UiPath and Blue Prism, which automate routine tasks such as data entry and customer service.
This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality dataintegration problem of low-cost sensors. This is done to optimize performance and minimize cost of LLM invocation.
By facilitating efficient dataintegration and enhancing LLM performance, LlamaIndex is tailored for scenarios where rapid, accurate access to structured data is paramount. Key Features of LlamaIndex: Data Connectors: Facilitates the integration of various data sources, simplifying the data ingestion process.
Finally, metrics such as ROUGE and F1 can be fooled by shallow linguistic similarities (word overlap) between the ground truth and the LLM response, even when the actual meaning is very different. Prior to Amazon, Evangelia completed her Ph.D. at Language Technologies Institute, Carnegie Mellon University.
However, studies have also shown that LLMs can be readily programmed to produce false information, intentionally or unintentionally, due to their ability to mimic human speech, which may include hallucinations, and their ability to follow human commands. This makes it harder for humans and detectors to identify.
Multimodal DataIntegration isCritical Relying solely on structured EHR data risks missing up to 80% of patient context. Combining notes, lab results, imaging data, and prescription histories give a fuller picturevital for accurate risk prediction and decisionsupport. Careful pruning to eliminate low-quality data.
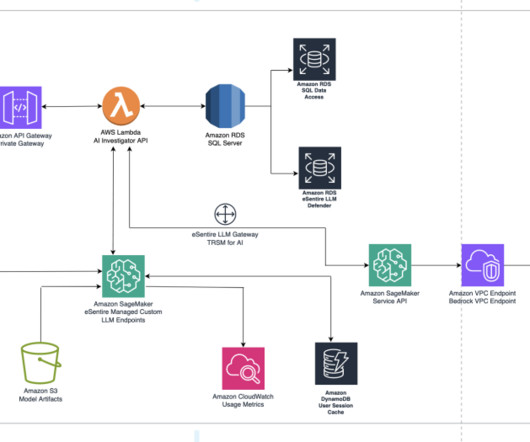
With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. The Q&A handler, running on AWS Fargate, orchestrates the complete query response cycle by coordinating between services and processing responses through the LLM pipeline.
The LLM models augment SOC investigations with knowledge from eSentire’s security experts and security data, enabling higher-quality investigation outcomes while also reducing time to investigate. Therefore, eSentire decided to build their own LLM using Llama 1 and Llama 2 foundational models.
These models struggle with processing temporal dynamics and integrating audio-visual data, limiting their effectiveness in predicting future events and performing comprehensive multimodal analyses. Addressing these complexities is crucial for enhancing Video-LLM performance.
Beyond Benchmarks: Evaluating AI Agents in the RealWorld Sinan Ozdemir, AI & LLM Expert, Author, and Founder + CTO of LoopGenius Benchmarks can only take you so far. The session shares lessons on dataintegration, compliance, and domain adaptationmaking it essential for anyone building industry-specific agents.
On the other hand, the valuable data needed to gain those insights has to stay confidential and is only allowed to be shared with certain parties or no third parties at all. So, is there a way to gain insights of valuable data through AI without the need to expose the data set or the AI model (LLM, ML, DL) to another party?
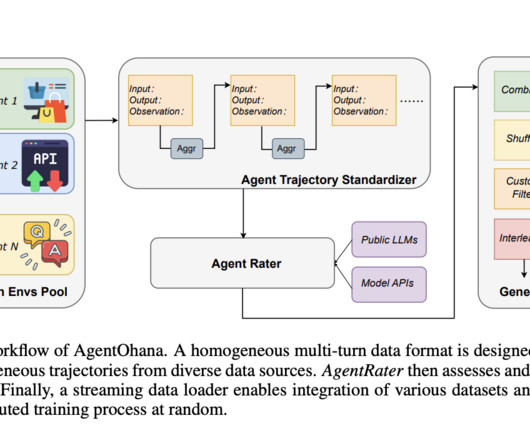
The heterogeneity of data not only poses a roadblock in terms of compatibility but also affects the consistency and quality of agent training. Existing methodologies, while commendable, often need to address the multifaceted challenges presented by this data diversity.
When working with unstructured data from many sources, including HTML, PDFs, CSVs, PNGs, and more, these capabilities are quite helpful because formatting problems, like unusual symbols or word separations, are frequently encountered.
The integration process typically starts with setting up NVIDIA NIM by installing the necessary NVIDIA drivers and CUDA toolkit, configuring the system to support NIM, and deploying models in a containerized environment. Next, LangChain is installed and configured to integrate with NVIDIA NIM.
All of these features are extremely helpful for modern data teams, but what makes Airflow the ideal platform is that it is an open-source project –– meaning there is a community of Airflow users and contributors who are constantly working to further develop the platform, solve problems and share best practices.
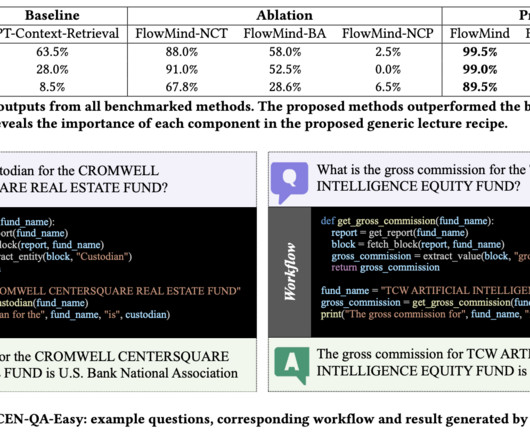
Second, for each provided base table T, the researchers use data discovery algorithms to find possible related candidate tables. This facilitates a series of data transformations and enhances the effectiveness of the proposed LLM-based system. Examples of DATALORE utilization.
Analytics/Answers are included(batteries included in LLM): In the consumption of the data after data janitor work, we no longer have to depend on tables, spreadsheets or any other your favorite analytics tool for messaging and formatting this dataset to build the decks/presentations that you want to communicate the insights and learnings.
These tools are made to detect instances in which AI falsifies data. Pythia Modern AI hallucination detection tool Pythia is intended to guarantee LLM outputs that are accurate and dependable. The top AI hallucination detection technologies have been discussed below. Tests of models such as GPT-3.5,
Supporting the company’s goal of reaching net-zero carbon status by 2035, the 5,000-acre integrated photovoltaic manufacturing plant is meant to be India’s largest solar gigafactory. It is targeted at helping drive advances in sovereign LLM frameworks, agentic AI and physical AI.
The initial round utilizes a powerful pre-trained LLM, DeepSeek-Coder-V2-Instruct (236B), to bootstrap the process. This ensures the generation of high-quality reasoning trajectories, significantly enhancing the training datasintegrity. Round 1: Bootstrapping. Process Preference Model (PPM). Outperforming OpenAI o1.
Over the course of his career, Erik has been at the forefront of integrating building large-scale platforms and integrating AI into search technologies, significantly enhancing user interaction and information accessibility.
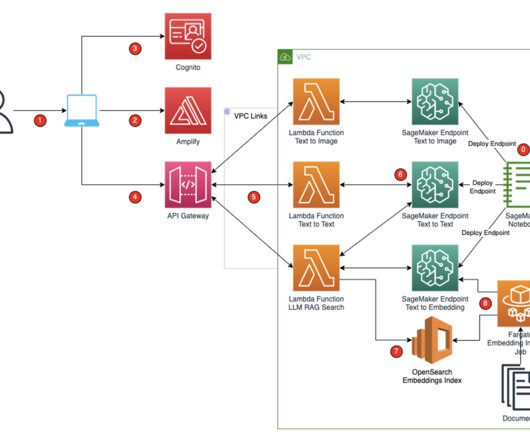
Lambda functions also construct the prompts from the sanitized user input in the respective format expected by the LLM. These Lambda functions also reformat the output from the LLMs and send the response back to the user. Also, delete the output data in Amazon S3 you created while running the application workflow.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and dataintegrity in the secure AWS environment. To learn more about Arcee.ai, visit Arcee.ai or reach out to our team.
Using this context, modified prompt is constructed required for the LLM model. A request is posted to the Amazon Bedrock Claude-2 model to get the response from the LLM model selected. The data is post-processed from the LLM response and a response is sent to the user.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
The original query is augmented with the retrieved documents, providing context for the large language model (LLM). The LLM generates a response based on the augmented query and retrieved context. This granularity supports better version control and data lineage tracking, which are crucial for dataintegrity and compliance.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content