This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
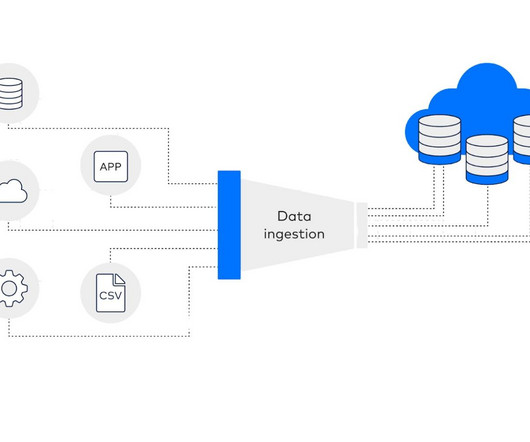
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. What is ETL? ETL stands for Extract, Transform, Load.
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Rockets legacy data science architecture is shown in the following diagram. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark.
In BI systems, data warehousing first converts disparate raw data into clean, organized, and integrated data, which is then used to extract actionable insights to facilitate analysis, reporting, and data-informed decision-making. The following elements serve as a backbone for a functional data warehouse.
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. This manual synchronization process, hindered by disparate data formats, is resource-intensive, limiting the potential for widespread data orchestration.
The following figure shows an example diagram that illustrates an orchestrated extract, transform, and load (ETL) architecture solution. Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automate data flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation.
Tackling these challenges is key to effectively connecting readers with content they find informative and engaging. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. The following diagram illustrates the dataingestion architecture.
Customer 360 initiatives are designed to bring together relevant information about individual consumers from different touch points, including but not limited to sales, marketing, customer service, and social media platforms. How Data Engineering Enhances Customer 360 Initiatives 1.
These work together to enable efficient data processing and analysis: · Hive Metastore It is a central repository that stores metadata about Hive’s tables, partitions, and schemas. Thus, making it easier for analysts and data scientists to leverage their SQL skills for Big Data analysis.
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. As stated above, data pipelines represent the backbone of modern data architecture.
Hence, the quality of data is significant here. Quality data fuels business decisions, informs scientific research, drives technological innovations, and shapes our understanding of the world. The Relevance of Data Quality Data quality refers to the accuracy, completeness, consistency, and reliability of data.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines.
Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. Its drag-and-drop interface makes it user-friendly, allowing data engineers to build complex workflows without extensive coding knowledge. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
This is what data processing pipelines do for you. Automating myriad steps associated with pipeline data processing, helps you convert the data from its raw shape and format to a meaningful set of information that is used to drive business decisions.
Its core components include: Lakehouse : Offers robust data storage and processing capabilities. Data Factory : Simplifies the creation of ETL pipelines to integrate data from diverse sources. It supports a broad range of data types and sources, ensuring robust data management across silos.
Recommended How to Solve the DataIngestion and Feature Store Component of the MLOps Stack Read more A unified architecture for ML systems One of the challenges in building machine-learning systems is architecting the system. These features are computed on-demand using feature functions.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page. Every Airflow task calls Amazon ECS tasks with some overrides.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Instead, flexible open-source programming languages and public data repositories are empowering anyone to experiment, build models, and question through data. Students, academics, startupsall levels now avail equal resources to mine information forgood. In fact, statistics show the expansion firsthand.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content