This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
Amazon DataZone makes it straightforward for engineers, datascientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
According to IDC , 83% of CEOs want their organizations to be more data-driven. Datascientists could be your key to unlocking the potential of the Information Revolution—but what do datascientists do? What Do DataScientists Do? Datascientists drive business outcomes. Download Now.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Datascientists often spend up to 80% of their time on data engineering in data science projects.
You can use machine learning (ML) to generate these insights and build predictive models. Educators can also use ML to identify challenges in learning outcomes, increase success and retention among students, and broaden the reach and impact of online learning content. Note that major data transformation is out of scope for this post.
With the IoT, tracking website clicks, capturing call data records for a mobile network carrier, tracking events generated by “smart meters” and embedded devices can all generate huge volumes of transactions. Many consider a NoSQL database essential for high dataingestion rates.
Choose Sync to initiate the dataingestion job. After data synchronization is complete, select the desired FM to use for retrieval and generation (it requires model access to be granted to this FM in Amazon Bedrock before using). On the Amazon Bedrock console, navigate to the created knowledge base.
In this post, we discuss how the IEO developed UNDP’s artificial intelligence and machine learning (ML) platform—named Artificial Intelligence for Development Analytics (AIDA)— in collaboration with AWS, UNDP’s Information and Technology Management Team (UNDP ITM), and the United Nations International Computing Centre (UNICC).
Foundational models (FMs) are marking the beginning of a new era in machine learning (ML) and artificial intelligence (AI) , which is leading to faster development of AI that can be adapted to a wide range of downstream tasks and fine-tuned for an array of applications. Large language models (LLMs) have taken the field of AI by storm.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
However, a more holistic organizational approach is crucial because generative AI practitioners, datascientists, or developers can potentially use a wide range of technologies, models, and datasets to circumvent the established controls.
Combining accurate transcripts with Genesys CTR files, Principal could properly identify the speakers, categorize the calls into groups, analyze agent performance, identify upsell opportunities, and conduct additional machine learning (ML)-powered analytics.
I recently took the Azure DataScientist Associate certification exam DP-100, thankfully I passed after about 3–4 months for studying the Microsoft Data Science Learning Path and the Coursera Microsoft Azure DataScientist Associate Specialization.
Our expert speakers will cover a wide range of topics, tools, and techniques that datascientists of all levels can apply in their work. Scaling AI/ML Workloads with Ray Kai Fricke | Senior Software Engineer | Anyscale Inc. Check a few of them out below.
Choose Sync to initiate the dataingestion job. After the dataingestion job is complete, choose the desired FM to use for retrieval and generation. About the Authors Sandeep Singh is a Senior Generative AI DataScientist at Amazon Web Services, helping businesses innovate with generative AI.
We downloaded the data from AWS Data Exchange and processed it in AWS Glue to generate KG files. In Part 2 , we demonstrated how to use Amazon Neptune ML (in Amazon SageMaker ) to train the KG and create KG embeddings. The KG files were stored in Amazon Simple Storage Service (Amazon S3) and then loaded in Amazon Neptune.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
MongoDB Atlas offers automatic sharding, horizontal scalability, and flexible indexing for high-volume dataingestion. Among all, the native time series capabilities is a standout feature, making it ideal for a managing high volume of time-series data, such as business critical application data, telemetry, server logs and more.
Identification of relevant representation data from a huge volume of data – This is essential to reduce biases in the datasets so that common scenarios (driving at normal speed with obstruction) don’t create class imbalance. To yield better accuracy, DNNs require large volumes of diverse, good quality data.
Topics Include: Agentic AI DesignPatterns LLMs & RAG forAgents Agent Architectures &Chaining Evaluating AI Agent Performance Building with LangChain and LlamaIndex Real-World Applications of Autonomous Agents Who Should Attend: DataScientists, Developers, AI Architects, and ML Engineers seeking to build cutting-edge autonomous systems.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
Understanding the MLOps Lifecycle The MLOps lifecycle consists of several critical stages, each with its unique challenges: DataIngestion: Collecting data from various sources and ensuring it’s available for analysis. Data Preparation: Cleaning and transforming raw data to make it usable for machine learning.
Simple methods for time series forecasting use historical values of the same variable whose future values need to be predicted, whereas more complex, machine learning (ML)-based methods use additional information, such as the time series data of related variables. However, the notebook-based method is difficult to operationalize.
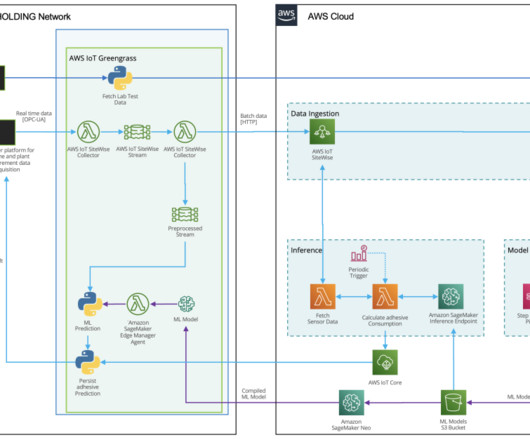
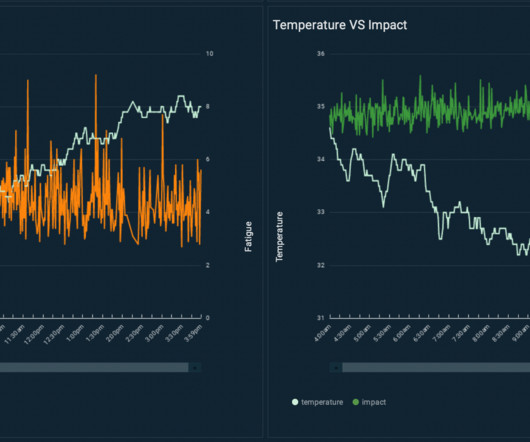
there is enormous potential to use machine learning (ML) for quality prediction. ML-based predictive quality in HAYAT HOLDING HAYAT is the world’s fourth-largest branded baby diapers manufacturer and the largest paper tissue manufacturer of the EMEA. Two types of data sources exist for this use case.
Introduction In the rapidly evolving landscape of Machine Learning , Google Cloud’s Vertex AI stands out as a unified platform designed to streamline the entire Machine Learning (ML) workflow. This unified approach enables seamless collaboration among datascientists, data engineers, and ML engineers.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
Unfortunately accessing data across various locations and file types and then operationalizing that data for AI usage has traditionally been a painfully manual, time-consuming, and costly process. Ahmad Khan, Head of AI/ML Strategy at Snowflake, discusses the challenges of operationalizing ML in a recent talk.
The PdMS includes AWS services to securely manage the lifecycle of edge compute devices and BHS assets, cloud dataingestion, storage, machine learning (ML) inference models, and business logic to power proactive equipment maintenance in the cloud. It’s an easy way to run analytics on IoT data to gain accurate insights.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
These models offer tremendous potential but also bring a unique set of challenges when it comes to building large-scale ML projects. Naturally, training a machine learning model (regardless of the problem being solved or the particular model architecture that was chosen) is a key part of every ML project. But what happens next?
Amazon SageMaker Serverless Inference is a purpose-built inference service that makes it easy to deploy and scale machine learning (ML) models. PyTorch is an open-source ML framework that accelerates the path from research prototyping to production deployment. The dataingestion for this practice should finish within 60 seconds.
They can efficiently aggregate and process data over defined periods, making them ideal for identifying trends, anomalies, and correlations within the data. High-Volume DataIngestion TSDBs are built to handle large volumes of data coming in at high velocities. What are the Benefits of Using a Time Series Database?
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Machine Learning Integration Opportunities Organizations harness machine learning (ML) algorithms to make forecasts on the data.
Data Engineering is one of the most productive job roles today because it imbibes both the skills required for software engineering and programming and advanced analytics needed by DataScientists. How to Become an Azure Data Engineer? Answer : Polybase helps optimize dataingestion into PDW and supports T-SQL.
The solution lies in systems that can handle high-throughput dataingestion while providing accurate, real-time insights. Waabis teams, running large-scale ML experiments, needed a way to organize and share their experiment data efficiently. Tools like neptune.ai Consider the challenges faced by Waabi and ReSpo.Vision.
In the upcoming part of this series, we will delve into advanced concepts of Airflow, including backfilling techniques and building an ETL pipeline in Airflow for dataingestion into Postgres and Google Cloud BigQuery. You have learned how to trigger a DAG in Airflow, create a DAG from scratch, and initiate its execution.
One of the most prevalent complaints we hear from ML engineers in the community is how costly and error-prone it is to manually go through the ML workflow of building and deploying models. Building end-to-end machine learning pipelines lets ML engineers build once, rerun, and reuse many times. If all goes well, of course ?
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with.
There comes a time when every ML practitioner realizes that training a model in Jupyter Notebook is just one small part of the entire project. Getting a workflow ready which takes your data from its raw form to predictions while maintaining responsiveness and flexibility is the real deal.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content