

How Axfood enables accelerated machine learning throughout the organization using Amazon SageMaker
AWS Machine Learning Blog
FEBRUARY 27, 2024
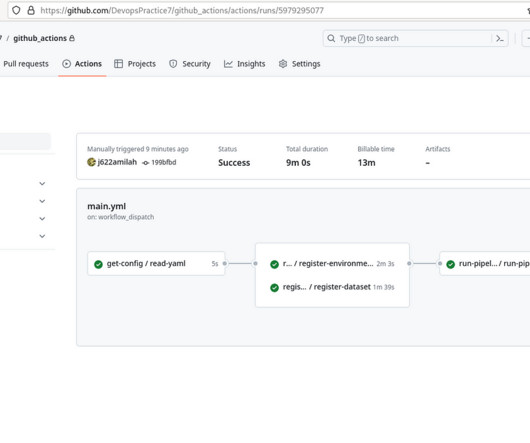
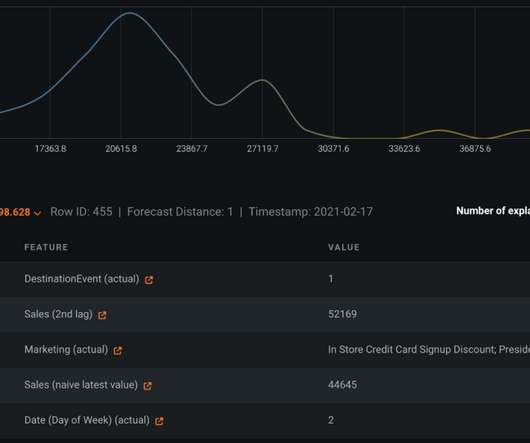
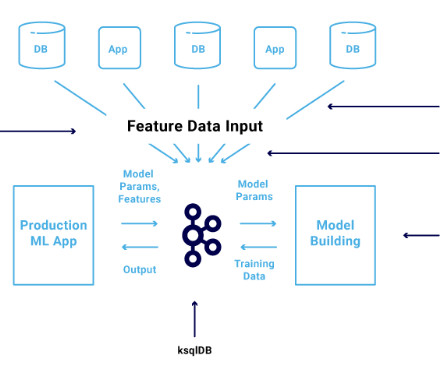
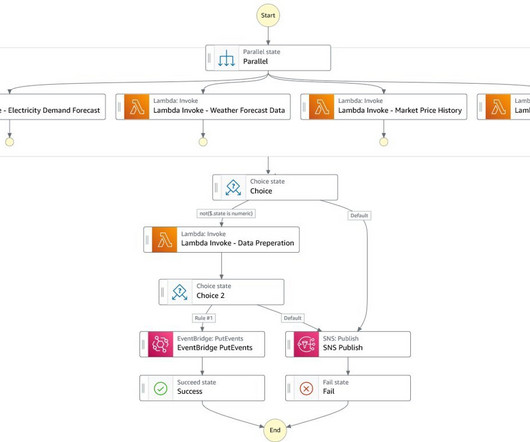
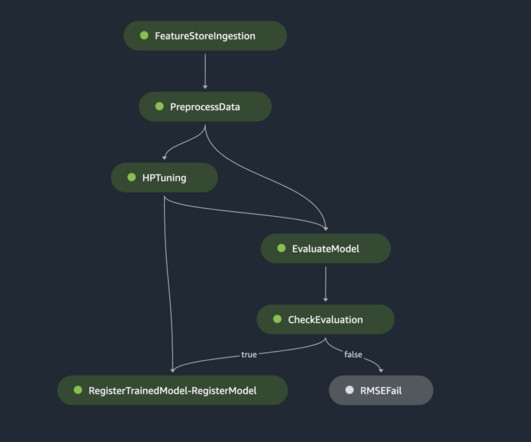
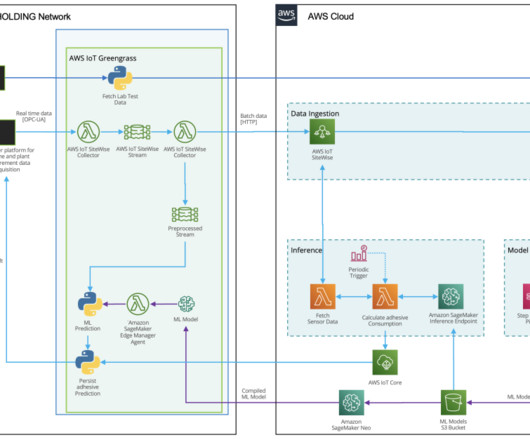
Each product translates into an AWS CloudFormation template, which is deployed when a data scientist creates a new SageMaker project with our MLOps blueprint as the foundation. These are essential for monitoring data and model quality, as well as feature attributions.






































Let's personalize your content