This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Rockets legacy datascience environment challenges Rockets previous datascience solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided DataScience Experience development tools.
Here are a few key reasons: The variety and volume of data will continue to grow, requiring the database to handle diverse data types—structured, unstructured, and semi-structured—at scale. Selecting a database that can manage such variety without complex ETL processes is important.
Introduction to Data Engineering Data Engineering Challenges: Data engineering involves obtaining, organizing, understanding, extracting, and formatting data for analysis, a tedious and time-consuming task. Data scientists often spend up to 80% of their time on data engineering in datascience projects.
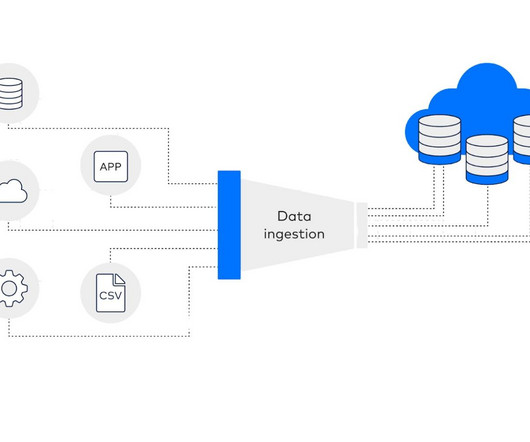
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
They can contain structured, unstructured, or semi-structured data. These can include structured databases, log files, CSV files, transaction tables, third-party business tools, sensor data, etc. The data ecosystem is connected to company-defined data sources that can ingest historical data after a specified period.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases.
Enterprises using Spark for a data lake implementation need to source and integrate additional software for tools that support user management, data storage and delivery, execution control, and administration. It truly is an all-in-one data lake solution.
Its core components include: Lakehouse : Offers robust data storage and processing capabilities. Data Factory : Simplifies the creation of ETL pipelines to integrate data from diverse sources. It supports a broad range of data types and sources, ensuring robust data management across silos.
Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. Its drag-and-drop interface makes it user-friendly, allowing data engineers to build complex workflows without extensive coding knowledge. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Step 3: Data Transformation Data transformation focuses on converting cleaned data into a format suitable for analysis and storage.
Data Governance Establish data governance policies to define roles, responsibilities, and data ownership within your organization. ETL (Extract, Transform, Load) Processes Enhance ETL processes to ensure data quality checks are performed during dataingestion.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of data pipelines, including the two major types of existing data pipelines. You also learned how to build an Extract Transform Load (ETL) pipeline and discovered the automation capabilities of Apache Airflow for ETL pipelines.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment. An example direct acyclic graph (DAG) might automate dataingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time.
What was once only possible for tech giants is now at our fingertipsvast amounts of data and analytical tools with the power to drive real progress. Open datascience is making it a reality. Remarkably, open datascience is democratizing analytics. In fact, statistics show the expansion firsthand.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
Data Foundation on AWS Amazon S3: Scalable storage foundation for data lakes. AWS Lake Formation: Simplify the process of creating and managing a secure data lake. Amazon Redshift: Fast, scalable data warehouse for analytics. AWS Glue: Fully managed ETL service for easy data preparation and integration.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content