This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This also led to a backlog of data that needed to be ingested. Steep learning curve for datascientists: Many of Rockets datascientists did not have experience with Spark, which had a more nuanced programming model compared to other popular ML solutions like scikit-learn.
A long-standing partnership between IBM Human Resources and IBM Global Chief Data Office (GCDO) aided in the recent creation of Workforce 360 (Wf360), a workforce planning solution using IBM’s Cognitive Enterprise DataPlatform (CEDP). Data quality is a key component for trusted talent insights.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a DataPlatform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Dataplatforms & Data Governance.
Axfood has a structure with multiple decentralized data science teams with different areas of responsibility. Together with a central dataplatform team, the data science teams bring innovation and digital transformation through AI and ML solutions to the organization.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps. IBM watsonx consists of the following: IBM watsonx.ai
The teams built a new dataingestion mechanism, allowing the CTR files to be jointly delivered with the audio file to an S3 bucket. Dr. Nicki Susman is a Senior DataScientist and the Technical Lead of the Principal Language AI Services team. He has 20 years of enterprise software development experience.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer dataplatform that simplifies the deployment and scaling of MongoDB databases in the cloud.
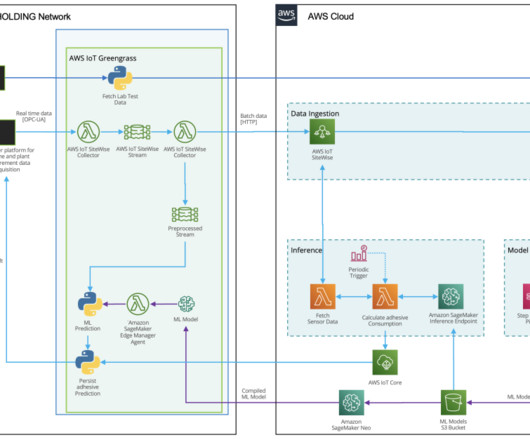
Dataingestion HAYAT HOLDING has a state-of-the art infrastructure for acquiring, recording, analyzing, and processing measurement data. Two types of data sources exist for this use case. Setting up and managing custom ML environments can be time-consuming and cumbersome.
Whether you aim for comprehensive data integration or impactful visual insights, this comparison will clarify the best fit for your goals. Key Takeaways Microsoft Fabric is a full-scale dataplatform, while Power BI focuses on visualising insights. Its strength lies in visualising and analysing data rather than managing it.
Machine Learning Operations (MLOps) can significantly accelerate how datascientists and ML engineers meet organizational needs. A well-implemented MLOps process not only expedites the transition from testing to production but also offers ownership, lineage, and historical data about ML artifacts used within the team.
Arranging Efficient Data Streams Modern companies typically receive data from multiple sources. Therefore, quick dataingestion for instant use can be challenging. Therefore, you’ll be empowered to truncate and reprocess data if bugs are detected and provide an excellent raw data source for datascientists.
Arjuna Chala, associate vice president, HPCC Systems For those not familiar with the HPCC Systems data lake platform, can you describe your organization and the development history behind HPCC Systems? They were interested in creating a dataplatform capable of managing a sizable number of datasets.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content