This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Big Data is everywhere, and it continues to be a gearing-up topic these days. And DataIngestion is a process that assists a group or management to make sense of the ever-increasing volume and complexity of data and provide useful insights. This […].
In the generative AI or traditional AI development cycle, dataingestion serves as the entry point. Here, raw data that is tailored to a company’s requirements can be gathered, preprocessed, masked and transformed into a format suitable for LLMs or other models. One potential solution is to use remote runtime options like.
By leveraging ML and natural language processing (NLP) techniques, CRM platforms can collect raw data from disparate sources, such as purchase patterns, customer interactions, buying behavior, and purchasing history. Dataingested from all these sources, coupled with predictive capability, generates unmatchable analytics.
This article was published as a part of the Data Science Blogathon. Introduction to Apache Flume Apache Flume is a dataingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Apache Pinot, an open-source OLAP datastore, offers the ability to handle real-time dataingestion and low-latency querying, making it […] The post Real-Time App Performance Monitoring with Apache Pinot appeared first on Analytics Vidhya.
Introduction Apache Flume is a tool/service/dataingestion mechanism for gathering, aggregating, and delivering huge amounts of streaming data from diverse sources, such as log files, events, and so on, to centralized data storage. Flume is a tool that is very dependable, distributed, and customizable.
Moreover, data is often an afterthought in the design and deployment of gen AI solutions, leading to inefficiencies and inconsistencies. Unlocking the full potential of enterprise data for generative AI At IBM, we have developed an approach to solving these data challenges.
Prescriptive AI relies on several essential components that work together to turn raw data into actionable recommendations. The process begins with dataingestion and preprocessing, where prescriptive AI gathers information from different sources, such as IoT sensors, databases, and customer feedback.
ArangoDB offers the same functionality as Neo4j with more than competitive… arangodb.com In the course of this project, I set up a local instance of ArangoDB using docker, and employed the ArangoDB Python Driver, python-arango, to develop dataingestion scripts. This prevents timeout and reconnect issues.
Introduction Azure data factory (ADF) is a cloud-based dataingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automates data movement and data transformation.
Data engineering teams are frequently tasked with building bespoke ingestion solutions for myriad custom, proprietary, or industry-specific data sources. Many teams find that.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
What is Real-Time DataIngestion? Real-time dataingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions.
Overview In the competitive world of professional hockey, NHL teams are always seeking to optimize their performance. Advanced analytics has become increasingly important.
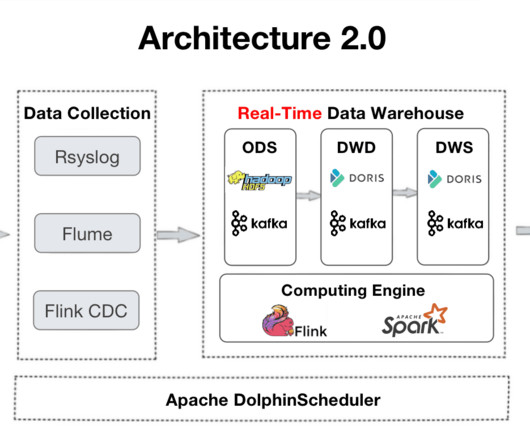
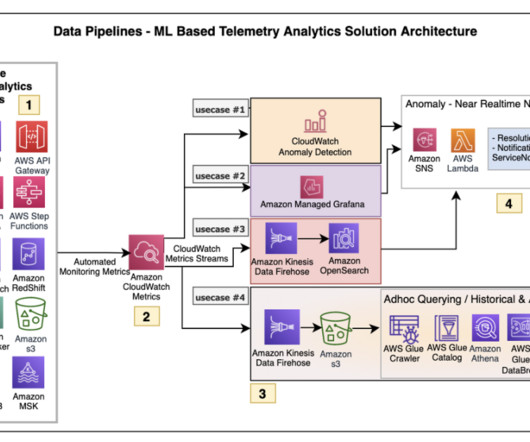
This article describes a large-scale data warehousing use case to provide reference for data engineers who are looking for log analytic solutions. It introduces the log processing architecture and real-case practice in dataingestion, storage, and queries.
Drasi's Real-Time Data Processing Architecture Drasi’s design is centred around an advanced, modular architecture, prioritizing scalability, speed, and real-time operation. Maily, it depends on continuous dataingestion , persistent monitoring, and automated response mechanisms to ensure immediate action on data changes.
If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
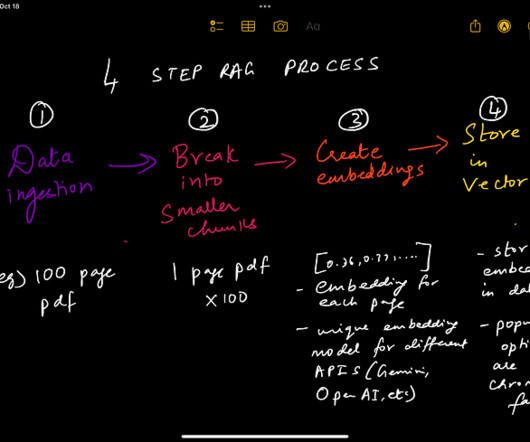
For production deployment, the no-code recipes enable easy assembly of the dataingestion pipeline to create a knowledge base and deployment of RAG or agentic chains. These solutions include two primary components: a dataingestion pipeline for building a knowledge base and a system for knowledge retrieval and summarization.
Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation. It offers elasticity, allowing businesses to handle fluctuating demands while sustaining performance and efficiency.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting dataingestion.
. - Introduction to AI Vector Embedding Generation Transformer : Discover how Onehouse solves the above challenges by enabling users to automatically create and manage vector embeddings from near real-time dataingestion streams to lakehouse tables without adding complex setups and extra tools. - Technical Deep Dive : Get into the nitty-gritty of (..)
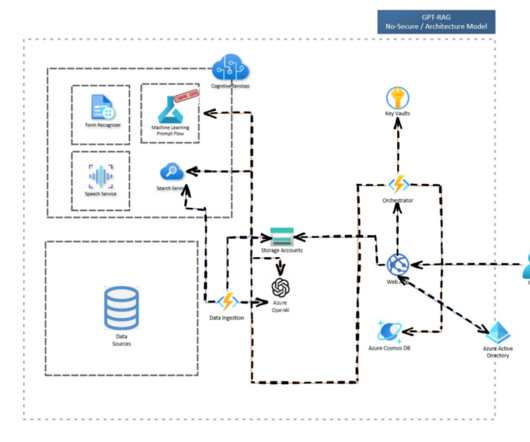
This observability ensures continuity in operations and provides valuable data for optimizing the deployment of LLMs in enterprise settings. The key components of GPT-RAG are dataingestion, Orchestrator, and front-end app.
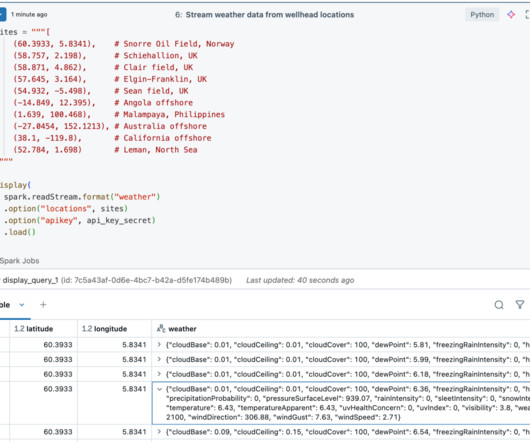
Rockets legacy data science architecture is shown in the following diagram. The diagram depicts the flow; the key components are detailed below: DataIngestion: Data is ingested into the system using Attunity dataingestion in Spark SQL.
The platform’s interactive UI, powered by Gradio, enhances the user experience by simplifying the dataingestion and parsing process. In conclusion, OmniParse addresses the significant challenge of handling unstructured data by providing a versatile and efficient platform that supports multiple data types.
Solution overview This solution uses several key AWS AI services to build and deploy the AI assistant: Amazon Bedrock – Amazon Bedrock is a fully managed service that offers a choice of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad (..)
By leveraging GPU acceleration, we've dramatically reduced index-building time, enabling faster dataingestion and improved data visibility. Compared to traditional database indexing, vector index construction requires several orders of magnitude more computational power.
Professionals can benefit from high-quality video playback, accelerate video dataingestion and use advanced AI-powered video editing features. Fifth-Generation PCIe : Provides double the bandwidth over the previous generation, improving data transfer speeds from CPU memory and unlocking faster performance for data-intensive tasks.
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project.
Deltek is continuously working on enhancing this solution to better align it with their specific requirements, such as supporting file formats beyond PDF and implementing more cost-effective approaches for their dataingestion pipeline. The first step is dataingestion, as shown in the following diagram. What is RAG?
When combined with Snorkel Flow, it becomes a powerful enabler for enterprises seeking to harness the full potential of their proprietary data. What the Snorkel Flow + AWS integrations offer Streamlined dataingestion and management: With Snorkel Flow, organizations can easily access and manage unstructured data stored in Amazon S3.
Accelerated data processing Efficient data processing pipelines are critical for AI workflows, especially those involving large datasets. Leveraging distributed storage and processing frameworks such as Apache Hadoop, Spark or Dask accelerates dataingestion, transformation and analysis.
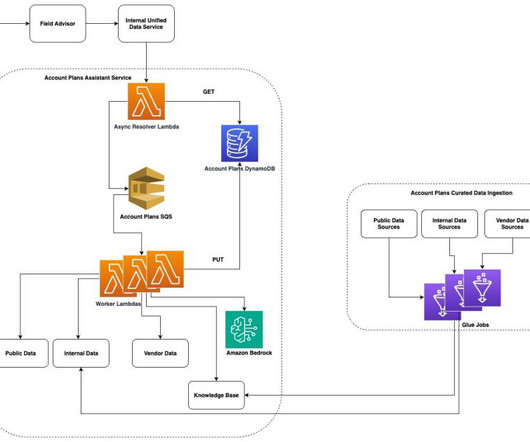
Through its RAG architecture, we semantically search and use metadata filtering to retrieve relevant context from diverse sources: internal sales enablement materials, historic APs, SEC filings, news articles, executive engagements and data from our CRM systems.
Over the years, an overwhelming surplus of security-related data and alerts from the rapidly expanding cloud digital footprint has put an enormous load on security solutions that need greater scalability, speed and efficiency than ever before.
By default, Amazon Bedrock encrypts all knowledge base-related data using an AWS managed key. When setting up a dataingestion job for your knowledge base, you can also encrypt the job using a custom AWS Key Management Service (AWS KMS) key. Alternatively, you can choose to use a customer managed key.
Overcoming challenges means addressing dataingestion bottlenecks, hybrid cloud AI model distribution, robust model safeguarding through advanced encryption and governance for trustworthiness.
As a vertically integrated AI studio, Inflection AI handles the entire process in-house, from dataingestion and model design to high-performance infrastructure. The post Inflection-2.5: The Powerhouse LLM Rivaling GPT-4 and Gemini appeared first on Unite.AI.
This solution addresses the complexities data engineering teams face by providing a unified platform for dataingestion, transformation, and orchestration. Image Source Key Components of LakeFlow: LakeFlow Connect: This component offers point-and-click dataingestion from numerous databases and enterprise applications.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content