This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This advancement has spurred the commercial use of generative AI in natural language processing (NLP) and computer vision, enabling automated and intelligent dataextraction. Businesses can now easily convert unstructured data into valuable insights, marking a significant leap forward in technology integration.
Whether you're leveraging OpenAI’s powerful GPT-4 or with Claude’s ethical design, the choice of LLM API could reshape the future of your business. Why LLM APIs Matter for Enterprises LLM APIs enable enterprises to access state-of-the-art AI capabilities without building and maintaining complex infrastructure.
This marks a pivotal moment for the […] The post Building an Image Data Extractor using Gemini Vision LLM appeared first on Analytics Vidhya. However, Google has recently entered the arena with the launch of the Gemini Version of their model, unveiling its API to the public on December 13th.
Traditional methods for handling such data are either too slow, require extensive manual work, or are not flexible enough to adapt to the wide variety of document types and layouts that businesses encounter. Sparrow supports local dataextraction pipelines through advanced machine learning models like Ollama and Apple MLX.
In this blog post, we explore a real-world scenario where a fictional retail store, AnyCompany Pet Supplies, leverages LLMs to enhance their customer experience. We will provide a brief introduction to guardrails and the Nemo Guardrails framework for managing LLM interactions. What is Nemo Guardrails? The ellipsis (.
Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training large language models. It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown.
Albert detailed an industry-first observation during the testing phase of Claude 3 Opus, Anthropic’s most potent LLM variant, where the model exhibited signs of awareness that it was being evaluated. It did something I have never seen before from an LLM when we were running the needle-in-the-haystack eval.
Introduction Effective retrieval methods are paramount in an era where data is the new gold. This article introduces an innovative dataextraction and processing approach. Dive into the world of txtai and Retrieval Augmented Generation (RAG), where complex data becomes easily navigable and insightful.
In this article, I will demonstrate how to leverage the Phi-3 mini model from the Azure AI studio to enhance the dataextraction process. This would be enough for most of the document extraction, but for complex documents will not suffice. The “prebuilt” layout is the best choice for the job, the rest will be done by the LLM.
Firecrawl is a vital tool for data scientists because it addresses these issues head-on. This guarantees a complete dataextraction procedure by ensuring that no important data is lost. Firecrawl extractsdata and returns it in a clean, well-formatted Markdown.
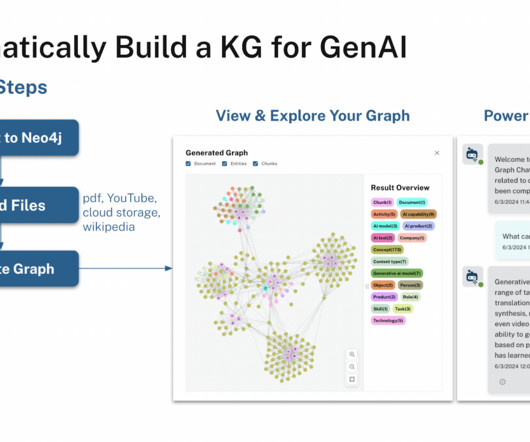
In the rapidly developing field of Artificial Intelligence, it is more important than ever to convert unstructured data into organized, useful information efficiently. Recently, a team of researchers introduced the Neo4j LLM Knowledge Graph Builder , an AI tool that can easily address this issue. The steps involved are as follows.
This is where LLMs come into play with their capabilities to interpret customer feedback and present it in a structured way that is easy to analyze. This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data We decided to use the Amazon reviews dataset.
If all youre using is an LLM for intelligent dataextraction and analysis, then a separate server might be overkill. For many organizations, the technical and financial burden is enough to make the scalability and flexibility of the cloud seem far more appealing. The Hybrid Model: A Practical Middle Ground?
Imagine you're processing 100 invoices a day and need to compile all the details into an Excel sheet by the end of the day; Extractors.ai makes this task fast and effortless, CEO Aravind Jayendran said.
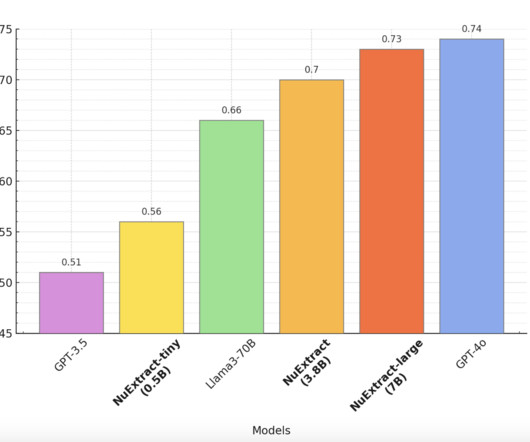
NuMind introduces NuExtract , a cutting-edge text-to-JSON language model that represents a significant advancement in structured dataextraction from text. This model aims to transform unstructured text into structured data highly efficiently.
These advanced models are capable of seamlessly integrating information from multiple modalities, such as images and text, providing a more holistic and efficient approach to dataextraction and interpretation. This shift has paved the way for more accurate and sophisticated AI-driven solutions across various industries.
Businesses can benefit greatly from using Reducto to extract value from their unstructured data. Reducto helps companies save time money, and get useful insights by automating and streamlining the dataextraction process.
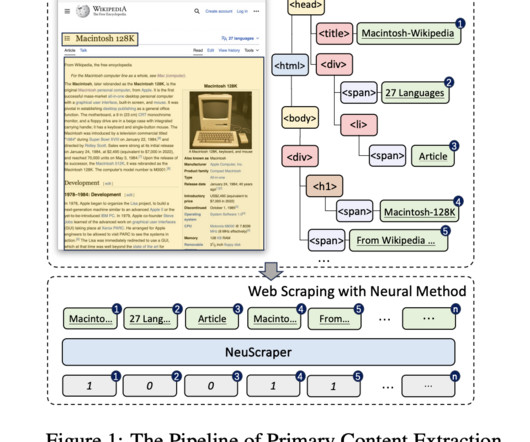
They need help to differentiate between the core content and the myriad of distractions like advertisements, pop-ups, and irrelevant hyperlinks, leading to the collection of noisy data that can dilute the quality of LLM training sets.
LeMUR: Build LLM apps on voice data LeMUR is the easiest way to code applications that apply LLMs to speech. Dialogue DataExtraction using LeMUR and JSON. Audio File Processing with LLMs through LeMUR. Learn how to utilize RAG on audio data.
Unlike screen scraping, which simply captures the pixels displayed on a screen, web scraping captures the underlying HTML code along with the data stored in the corresponding database. This approach is among the most efficient and effective methods for dataextraction from websites.
With Amazon Bedrock Data Automation, this entire process is now simplified into a single unified API call. It also offers flexibility in dataextraction by supporting both explicit and implicit extractions. It also transcribes the audio into text and combines both visual and audio data for chapter level analysis.
Medical dataextraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Meet ClinGen: An AI Model that Involves Clinical Knowledge Extraction and Context-Informed LLM Prompting appeared first on MarkTechPost.
DeepHermes 3 Preview (DeepHermes-3-Llama-3-8B-Preview) is the latest iteration in Nous Researchs series of LLMs. As one of the first models to integrate both reasoning-based long-chain thought processing and conventional LLM response mechanisms, DeepHermes 3 marks a significant step in AI model sophistication.
This framework harnesses the power of LLMs to create a seamless, user-friendly interface across numerous development frameworks. Simplifying DataExtraction with LangChain Agents Retrieving data from a database is seldom a straightforward endeavor. The future of data interaction is here, and you’re a part of it.
This groundbreaking API complements the previously launched Agent API, offering a comprehensive solution for autonomous web browsing and dataextraction. Developers expressed the need for a natural language-based web understanding and dataextraction tool to enhance the agent’s capabilities in autonomous web browsing.
This enables companies to serve more clients, direct employees to higher-value tasks, speed up processes, lower expenses, enhance data accuracy, and increase efficiency. At the same time, the solution must provide data security, such as PII and SOC compliance. page_content) print(summary.replace(" ","").strip())
Sonnet large language model (LLM) on Amazon Bedrock. For naturalization applications, LLMs offer key advantages. They enable rapid document classification and information extraction, which means easier application filing for the applicant and more efficient application reviewing for the immigration officer.
This unstructured data can impact the efficiency and productivity of clinical services, because it’s often found in various paper-based forms that can be difficult to manage and process. In this post, we explore using the Anthropic Claude 3 on Amazon Bedrock large language model (LLM). read()) answer = response_body.get("content")[0].get("text")
In this article, well explore innovative prompt engineering techniques that can elevate your interactions with LLMs, making your dataextraction tasks more efficient and insightful. Prompt engineering is the practice of designing and refining the inputs you provide to an LLM to achieve desired outputs.
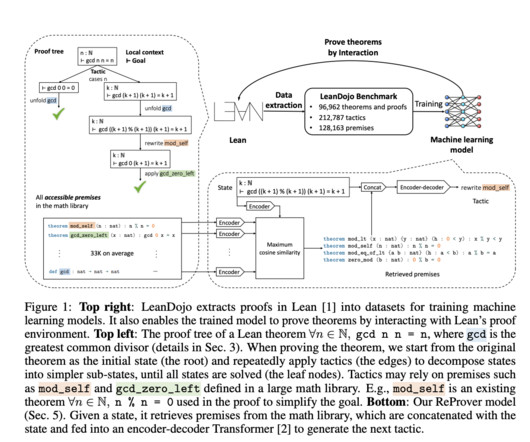
To overcome these limitations, a team of researchers from Caltech, NVIDIA, MIT, UC Santa Barbara, and UT Austin has introduced LeanDojo, which is an open-source toolkit for LLM-based theorem proving. It offers resources for working with Lean and extractingdata.
They guide the LLM to generate text in a specific tone, style, or adhering to a logical reasoning pattern, etc. For example, an LLM trained on predominantly European data might overrepresent those perspectives, unintentionally narrowing the scope of information or viewpoints it offers. After the meeting, went back to coding.”
A deep dive — dataextraction, initializing the model, splitting the data, embeddings, vector databases, modeling, and inference Photo by Simone Hutsch on Unsplash We are seeing a lot of use cases for langchain apps and large language models these days.
Image by Narciso on Pixabay Introduction Query Pipelines is a new declarative API to orchestrate simple-to-advanced workflows within LlamaIndex to query over your data. Other frameworks have built similar approaches, an easier way to build LLM workflows over your data like RAG systems, query unstructured data or structured dataextraction.
The multimodal PDF dataextraction blueprint uses NVIDIA NeMo Retriever NIM microservices to extract insights from enterprise documents, helping developers build powerful AI agents and chatbots. The digital human blueprint supports the creation of interactive, AI-powered avatars for customer service.
Updated LLM examples We added the new Flan-T5-based models for question-answering in our example notebooks, expanding the capabilities of the existing models with the newer version of Google’s multi-task model. By standardizing the date mentions, we can easily apply other analytics on the texts to obtain insights from the data.
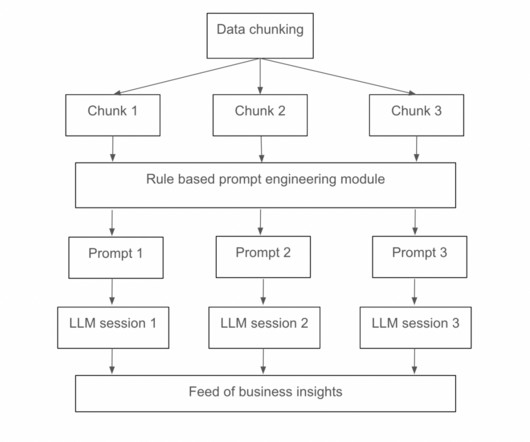
The datasets used included corporate Google Analytics 4 and Google Ads accounts data collected via APIs over two years. The process involves data cleaning, normalization, and transformation, followed by LLM-enhanced insights generation. Performance results demonstrate the effectiveness of this hybrid approach.
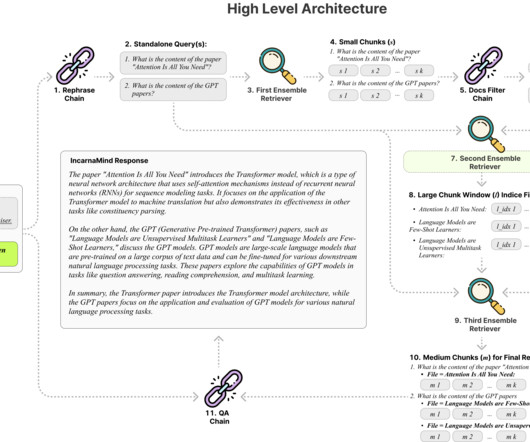
The Ensemble Retriever enhances the LLM’s responses by enabling IncarnaMind to effectively sort through both coarse- and fine-grained data in the user’s ground truth documents. Because traditional tools use a single chunk size for information retrieval, they frequently have trouble with different levels of data complexity.
Before we go deep into building the LLM-based AI application, we need to understand about LLM first. Large Language Model (LLM) refer to an advanced artificial intelligence model that is trained on vast amounts of text data to understand and generate human-like language. What is Large Language Model ?
Analytics/Answers are included(batteries included in LLM): In the consumption of the data after data janitor work, we no longer have to depend on tables, spreadsheets or any other your favorite analytics tool for messaging and formatting this dataset to build the decks/presentations that you want to communicate the insights and learnings.
This blog post explores how John Snow Labs Healthcare NLP & LLM library revolutionizes oncology case analysis by extracting actionable insights from clinical text. John Snow Labs , offers a powerful NLP & LLM library tailored for healthcare, empowering professionals to extract actionable insights from medical text.
It can be useful for quick dataextraction, but it sometimes misses key publications, and it’s not possible to manually upload a series of papers we are interested in. Elicit (www.elicit.org) aims to use AI to answer research questions by summarizing the available literature.
Moreover, these datasets suffer from limited diversity in both scale and difficulty levels, making it challenging to evaluate and enhance the reasoning capabilities of LLMs across different domains and complexity levels. million reasoning questions extracted from pretraining corpora.
In this blog, we explore how Bright Data’s tools can enhance your data collection process and what the future holds for web data in the context of AI. There are several reasons why this data is crucial for AI development: Diversity: The vast array of content available on the internet spans languages, domains, and perspectives.
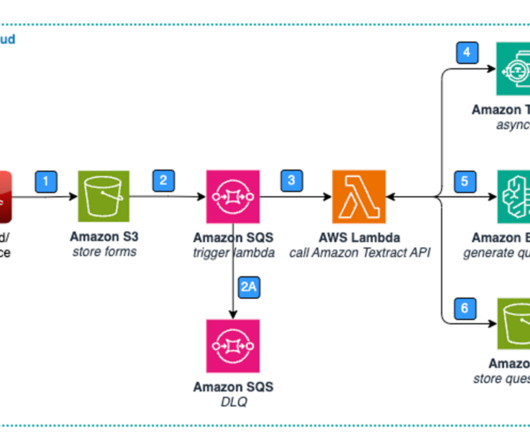
With Intelligent Document Processing (IDP) leveraging artificial intelligence (AI), the task of extractingdata from large amounts of documents with differing types and structures becomes efficient and accurate. LangChain uses Amazon Textract’s DetectDocumentText API for extracting text from printed, scanned, or handwritten documents.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content