
Can Synthetic Clinical Text Generation Revolutionize Clinical NLP Tasks? Meet ClinGen: An AI Model that Involves Clinical Knowledge Extraction and Context-Informed LLM Prompting
Marktechpost
NOVEMBER 14, 2023
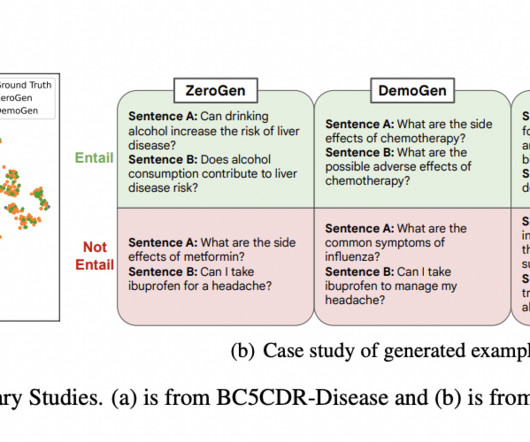
Medical data extraction, analysis, and interpretation from unstructured clinical literature are included in the emerging discipline of clinical natural language processing (NLP). Even with its importance, particular difficulties arise while developing methodologies for clinical NLP.



















Let's personalize your content