This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
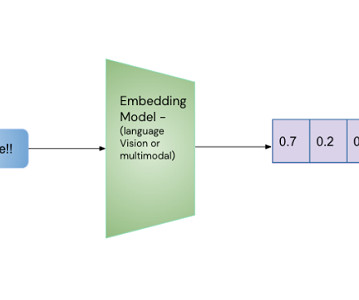
To find the relationship between a numeric variable (like age or income) and a categorical variable (like gender or education level), we first assign numeric values to the categories in a way that allows them to best predict the numeric variable. Linear categorical to categorical correlation is not supported.
In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data. By the end of the session, youll have practical strategies to reduce costs while maintaining high accuracy in real-world text classification tasks.
Classification: LLMs can categorize and label texts for sentiment, topic, authorship and more. Foster closer collaboration between security teams and MLengineers to instill security best practices. Question answering: They can provide informative answers to natural language questions across a wide range of topics.
Model risk : Risk categorization of the model version. Use case and model lifecycle governance overview In the context of regulations such as the European Union’s Artificial Intelligence Act (EU AI Act), a use case refers to a specific application or scenario where AI is used to achieve a particular goal or solve a problem.
Include summary statistics of the data, including counts of any discrete or categorical features and the target feature. Any competent software engineer can implement any algorithm. Even if you are an experienced AI/MLengineer, you should know the performance of simpler models on your dataset/problem.
While embeddings have become a popular way to represent unstructured data, they can also be generated for categorical and numeric variables in tabular datasets. Spark provides this abstraction layer to make it easy for a data engineer to pass this interface to an MLengineer to implement.
Earth.com didn’t have an in-house MLengineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system. This design necessitated distinct training processes for each model, leading to the creation of separate ML pipelines.
The traditional method of training an in-house classification model involves cumbersome processes such as data annotation, training, testing, and model deployment, requiring the expertise of data scientists and MLengineers. LLMs, in contrast, offer a high degree of flexibility.
The Ranking team is now able choose between four different automatic tuning strategies for their hyperparameter selection: Grid search – AMT will expect all hyperparameters to be categorical values, and it will launch training jobs for each distinct categorical combination, exploring the entire hyperparameter space.
Fundamental Programming Skills Strong programming skills are essential for success in ML. This section will highlight the critical programming languages and concepts MLengineers should master, including Python, R , and C++, and an understanding of data structures and algorithms. million by 2030, with a remarkable CAGR of 44.8%
Configuration files (YAML and JSON) allow ML practitioners to specify undifferentiated code for orchestrating training pipelines using declarative syntax. The following are the key benefits of this solution: Automation – The entire ML workflow, from data preprocessing to model registry, is orchestrated with no manual intervention.
It can also include constraints on the data, such as: Minimum and maximum values for numerical columns Allowed values for categorical columns. Before a model is productionized, the Contract is agreed upon by the stakeholders working on the pipeline, such as the MLEngineers, Data Scientists and Data Owners.
image by author Introduction Error analysis is a vital process in diagnosing errors made by an ML model during its training and testing steps. It enables data scientists or MLengineers to evaluate their models’ performance and identify areas for improvement. If you’re interested, you can find more information in the repository.
How to fine-tune and customize LLMs Hoang Tran, MLEngineer at Snorkel AI, outlined how he saw LLMs creating value in enterprise environments. The first categorizes instructions, while the second assesses the quality of responses.
This allows GuardDuty to categorize previously unseen domains as highly likely to be malicious or benign based on their association to known malicious domains. For example, Amazon GuardDuty , the native AWS threat detection service, uses a graph with billions of edges to improve the coverage and accuracy of its threat intelligence.
Our ML models include emotion detection, transcription, and NLP-powered conversational analysis that categorizes violations and provides a rank score to determine how confident it is that a violation has occurred. To be able to iterate quickly, we needed a compute environment that was familiar to our data scientists and MLengineers.
Throughout this exercise, you use Amazon Q Developer in SageMaker Studio for various stages of the development lifecycle and experience firsthand how this natural language assistant can help even the most experienced data scientists or MLengineers streamline the development process and accelerate time-to-value.
Based on experimental results, the collaborative models demonstrated a 4% improvement in categorizing molecules as either pharmacologically or toxicologically active or inactive. The FedML open-source library supports federated ML use cases for edge as well as cloud.
How to fine-tune and customize LLMs Hoang Tran, MLEngineer at Snorkel AI, outlined how he saw LLMs creating value in enterprise environments. The first categorizes instructions, while the second assesses the quality of responses.
After the completion of the research phase, the data scientists need to collaborate with MLengineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines. Security SMEs review the architecture based on business security policies and needs.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. This could lead to performance drifts.
How to fine-tune and customize LLMs Hoang Tran, MLEngineer at Snorkel AI, outlined how he saw LLMs creating value in enterprise environments. The first categorizes instructions, while the second assesses the quality of responses.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. This could lead to performance drifts.
And usually what ends up happening is that some poor data scientist or MLengineer has to manually troubleshoot this in a Jupyter Notebook. So this path on the right side of the production icon is what we’re calling ML observability. This could lead to performance drifts.
SageMaker geospatial capabilities make it easy for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. In this post, we explore how HSR. fillna(0) df1['totalpixels'] = df1.sum(axis=1) fillna(0) allDf[col] = allDf.groupby(idCols + ['year'])[col].transform(lambda
The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to data engineers and MLengineers that help them put these models into production. And these are not really compute-intensive for most structured ML problems.
The data scientists will start with experimentation, and then once they find some insights and the experiment is successful, then they hand over the baton to data engineers and MLengineers that help them put these models into production. And these are not really compute-intensive for most structured ML problems.
MLflow is an open-source platform designed to manage the entire machine learning lifecycle, making it easier for MLEngineers, Data Scientists, Software Developers, and everyone involved in the process. Machine learning operations (MLOps) are a set of practices that automate and simplify machine learning (ML) workflows and deployments.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Data Set Characteristics Multivariate Number of Instances 48842 Area Social Attribute Characteristics: Categorical, Integer Number of Attributes: 14 Date Donated 1996-05-01 Associated Tasks: Classification Missing Values? The following table summarizes the key components of the dataset.
In the post, they talk about advantages and diadvantages of Metaflow: Advantages User-friendly API: Metaflow offers a human-readable API that simplifies the process of building and managing ML workflows.
Text classification : Build faster models for categorizing high volumes of concurrent support tickets, emails, or customer feedback at scale; or for efficiently routing requests to larger models when necessary. This allows you to categorize and filter your interactions later.
Content categorization – Metadata can provide information about the content or category of a document, such as the subject matter, domain, or topic. Ginni Malik is a Senior Data & MLEngineer with AWS Professional Services. Outside of work, he enjoys playing adventure sports and spending time with family.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











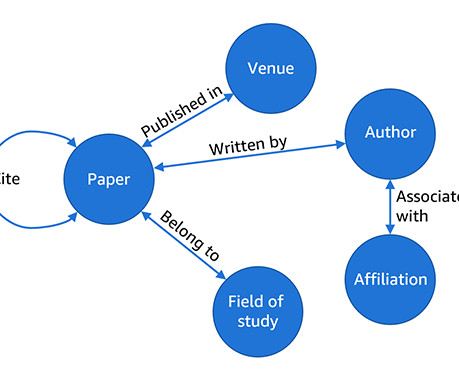
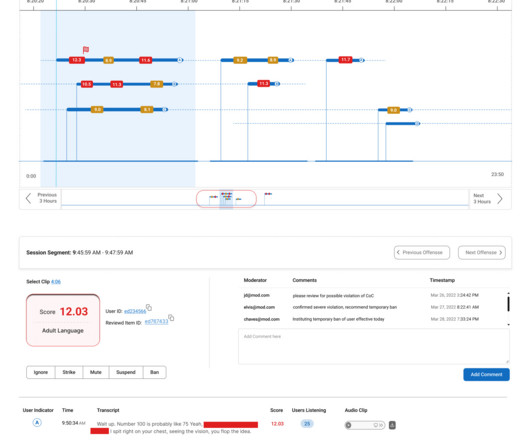








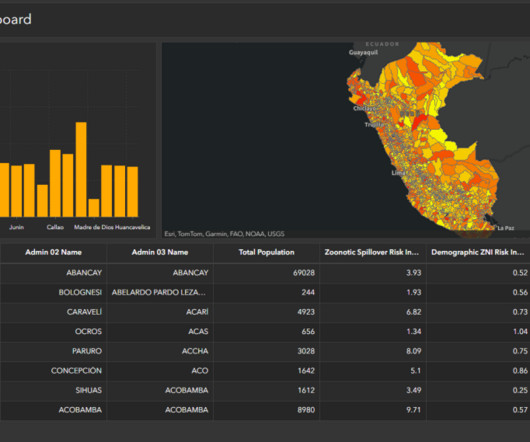




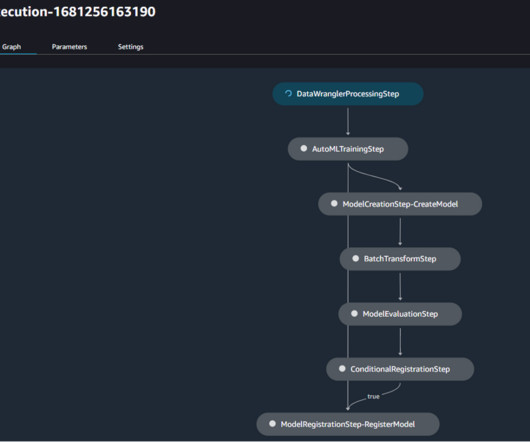









Let's personalize your content