This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In their paper, the researchers aim to propose a theory that explains how transformers work, providing a definite perspective on the difference between traditional feedforward neuralnetworks and transformers. Despite their widespread usage, the theoretical foundations of transformers have yet to be fully explored.
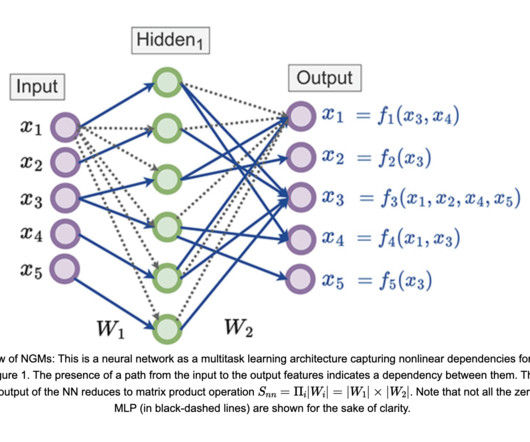
Many graphical models are designed to work exclusively with continuous or categorical variables, limiting their applicability to data that spans different types. Moreover, specific restrictions, such as continuous variables not being allowed as parents of categorical variables in directed acyclic graphs (DAGs), can hinder their flexibility.
It is known that, similar to the human brain, AI systems employ strategies for analyzing and categorizing images. Thus, there is a growing demand for explainability methods to interpret decisions made by modern machine learning models, particularly neuralnetworks.
Photo by Resource Database on Unsplash Introduction Neuralnetworks have been operating on graph data for over a decade now. Neuralnetworks leverage the structure and properties of graph and work in a similar fashion. Graph NeuralNetworks are a class of artificial neuralnetworks that can be represented as graphs.
Meme shared by rucha8062 TAI Curated section Article of the week Graph NeuralNetworks: Unlocking the Power of Relationships in Predictions By Shenggang Li This article explores Graph NeuralNetworks (GNNs), focusing on their ability to analyze connected data. Meme of the week!
One-hot encoding is a process by which categorical variables are converted into a binary vector representation where only one bit is “hot” (set to 1) while all others are “cold” (set to 0). Functionality : Each encoder layer has self-attention mechanisms and feed-forward neuralnetworks.
These fingerprints can then be analyzed by a neuralnetwork, unveiling previously inaccessible information about material behavior. As Argonne postdoctoral researcher James (Jay) Horwath explains, “The way we understand how materials move and change over time is by collecting X-ray scattering data.”
RL algorithms can be generally categorized into two groups i.e., value-based and policy-based methods. Policy Gradient Method As explained above, Policy Gradient (PG) methods are algorithms that aim to learn the optimal policy function directly in a Markov Decision Processes setting (S, A, P, R, γ).
Lucena explained how random forests first introduced the power of ensembles, but gradient boosting takes it a step further by focusing on the residual errors from previous trees. CatBoost : Specialized in handling categorical variables efficiently. LightGBM : Optimized for speed and scalability, making it useful for large datasets.
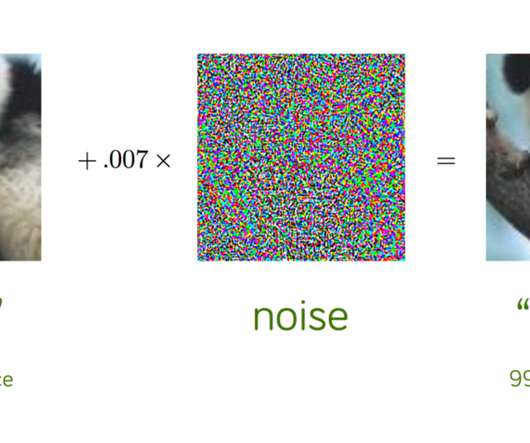
Source: Explaining and Harnessing Adversarial Examples , Goodfellow et al, ICLR 2015. We start with an image of a panda, which our neuralnetwork correctly recognizes as a “panda” with 57.7% Add a little bit of carefully constructed noise and the same neuralnetwork now thinks this is an image of a gibbon with 99.3%
In this guide, we’ll talk about Convolutional NeuralNetworks, how to train a CNN, what applications CNNs can be used for, and best practices for using CNNs. What Are Convolutional NeuralNetworks CNN? CNNs are artificial neuralnetworks built to handle data having a grid-like architecture, such as photos or movies.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. To identify the overlap densities within datasets, we developed an overlap detection algorithm leveraging the simplicity bias in neuralnetwork learning. I have also summarized the presentation’s main points here.
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here. To identify the overlap densities within datasets, we developed an overlap detection algorithm leveraging the simplicity bias in neuralnetwork learning. I have also summarized the presentation’s main points here.
In the following, we will explore Convolutional NeuralNetworks (CNNs), a key element in computer vision and image processing. Whether you’re a beginner or an experienced practitioner, this guide will provide insights into the mechanics of artificial neuralnetworks and their applications. Howard et al.
Tracking your image classification experiments with Comet ML Photo from nmedia on Shutterstock.com Introduction Image classification is a task that involves training a neuralnetwork to recognize and classify items in images. A dataset of labeled images is used to train the network, with each image given a particular class or label.
Existing surveys detail a range of techniques utilized in Explainable AI analyses and their applications within NLP. The LM interpretability approaches discussed are categorized based on two dimensions: localizing inputs or model components for predictions and decoding information within learned representations.
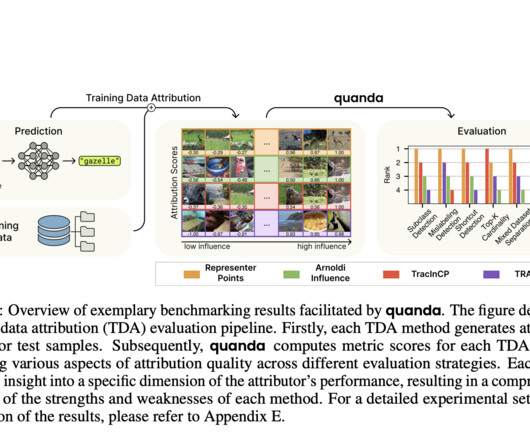
XAI, or Explainable AI, brings about a paradigm shift in neuralnetworks that emphasizes the need to explain the decision-making processes of neuralnetworks, which are well-known black boxes. Quanda differs from its contemporaries, like Captum, TransformerLens, Alibi Explain, etc.,
Traditionally, models for single-view object reconstruction built on convolutional neuralnetworks have shown remarkable performance in reconstruction tasks. Moreover, the performance of modern convolutional neuralnetworks in single-view 3D object reconstruction can be surpassed without explicitly inferring the 3D object structure.
In this hands-on session, youll start with logistic regression and build up to categorical and ordered logistic models, applying them to real-world survey data. Explainable AI for Decision-Making Applications Patrick Hall, Assistant Professor at GWSB and Principal Scientist at HallResearch.ai
A foundation model is built on a neuralnetwork model architecture to process information much like the human brain does. Foundation models: The driving force behind generative AI Also known as a transformer, a foundation model is an AI algorithm trained on vast amounts of broad data.
Most experts categorize it as a powerful, but narrow AI model. ” AGI analyzes relevant code, generates a draft function with comments explaining its logic and allows the programmer to review, optimize and integrate it. Some, like Goertzel and Pennachin , suggest that AGI would possess self-understanding and self-control.
As AIDAs interactions with humans proliferated, a pressing need emerged to establish a coherent system for categorizing these diverse exchanges. The main reason for this categorization was to develop distinct pipelines that could more effectively address various types of requests.
When it comes to implementing any ML model, the most difficult question asked is how do you explain it. Suppose, you are a data scientist working closely with stakeholders or customers, even explaining the model performance and feature selection of a Deep learning model is quite a task. How can we explain it in simple terms?
It easily handles a mix of categorical, ordinal, and continuous features. Yet, I haven’t seen a practical implementation tested on real data in dimensions higher than 3, combining both numerical and categorical features. All categorical features are jointly encoded using an efficient scheme (“smart encoding”).
In this world of complex terminologies, someone who wants to explain Large Language Models (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. Machine translation, summarization, ticket categorization, and spell-checking are among the examples.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. Linear Regression Decision Trees Support Vector Machines NeuralNetworks Clustering Algorithms (e.g., How Machine Learning Works?
After these accomplishments, other research has examined the advantages of pre-training large molecular graph neuralnetworks for low-data molecular modeling. They comprise jobs at the graph level and node level, as well as quantum, chemical, and biological aspects, categorical and continuous data points.
Text Classification : Categorizing text into predefined categories based on its content. It is used to automatically detect and categorize posts or comments into various groups such as ‘offensive’, ‘non-offensive’, ‘spam’, ‘promotional’, and others. It’s ‘trained’ on labeled data and then used to categorize new, unseen data.
For example, image classification, image search engines (also known as content-based image retrieval, or CBIR), simultaneous localization and mapping (SLAM), and image segmentation, to name a few, have all been changed since the latest resurgence in neuralnetworks and deep learning. Object detection is no different. 2015 ; He et al.,
This is the 3rd lesson in our 4-part series on OAK 101 : Introduction to OpenCV AI Kit (OAK) OAK-D: Understanding and Running NeuralNetwork Inference with DepthAI API Training a Custom Image Classification Network for OAK-D (today’s tutorial) OAK 101: Part 4 To learn how to train an image classification network for OAK-D, just keep reading.
Google Deepmind is also working on AI weather models, including graphcast based on graph neuralnetworks last year. This article explains linear regression in the context of spatial analysis and shows a practical example of its use in GIS. higher resolution images than current numerical models 1,000x faster. Why should you care?
Unlike regression, which deals with continuous output variables, classification involves predicting categorical output variables. Examples include Logistic Regression, Support Vector Machines (SVM), Decision Trees, and Artificial NeuralNetworks. They are easy to interpret and can handle both categorical and numerical data.
For instance, email management automation tools such as Levity use ML to identify and categorize emails as they come in using text classification algorithms. This allows you to craft personalized responses based on category, which saves time, and such customization can help improve your conversion rate.
Integrating XGboost with Convolutional NeuralNetworks Photo by Alexander Grey on Unsplash XGBoost is a powerful library that performs gradient boosting. One robust use case for XGBoost is integrating it with neuralnetworks to perform a given task. It was envisioned by Thongsuwan et al.,
We’ll start with a simple explainer of how Machine Learning models work — let’s say you want to predict how late your upcoming flight’s arrival time will be. Broadly, data sources can be broadly categorized into: Open Source Data: These are high volume data sources that are typically available for commercial purposes, including LLM training.
In addition to textual inputs, this model uses traditional structured data inputs such as numerical and categorical fields. We show you how to train, deploy and use a churn prediction model that has processed numerical, categorical, and textual features to make its prediction. For more details, refer to the GitHub repo.
Deep Learning (DL) is a more advanced technique within Machine Learning that uses artificial neuralnetworks with multiple layers to learn from and make predictions based on data. Explain The Concept of Supervised and Unsupervised Learning. Explain The Concept of Overfitting and Underfitting In Machine Learning Models.
This technique combines learning capabilities and logical reasoning from neuralnetworks and symbolic AI. This ability to trace outputs to the rules and knowledge within the program makes the symbolic AI model highly interpretable and explainable. Extracting information from the patterns learned by neuralnetworks.
Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach. Interpretability and Explainability: Deep neuralnetworks are one machine learning model that can be very complex and difficult to assess. What is Deep Learning?
Natural language processing (NLP) activities, including speech-to-text, sentiment analysis, text summarization, spell-checking, token categorization, etc., Unigrams, N-grams, exponential, and neuralnetworks are valid forms for the Language Model. rely on Language Models as their foundation.
Deep learning is a branch of machine learning that makes use of neuralnetworks with numerous layers to discover intricate data patterns. Deep learning models use artificial neuralnetworks to learn from data. Deep learning models use artificial neuralnetworks to learn from data.
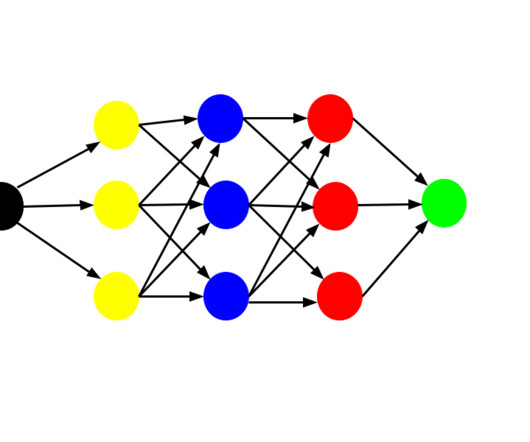
Curious how to design your deep neuralnetworks’ depth and shape? But instead of just tuning specific hyperparameters, we can also decide how our network is shaped. But instead of just tuning specific hyperparameters, we can also decide how our network is shaped. Well, here’s the guide for you.
In this lesson, we will answer this question by explaining the machine learning behind YouTube video recommendations. The overall system ( Figure 2 ) consists of two neuralnetworks for candidate generation and ranking. Hence, the ranking network takes in many more features describing the video (e.g., RecSys’16 ).
TensorFlow is an open-source software library for AI and machine learning with deep neuralnetworks. TensorFlow Lite also optimizes the trained model using quantization techniques (discussed later in this article), which consequently reduces the necessary memory usage as well as the computational cost of utilizing neuralnetworks.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















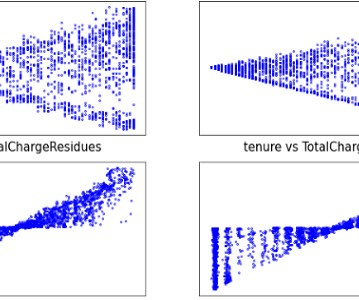


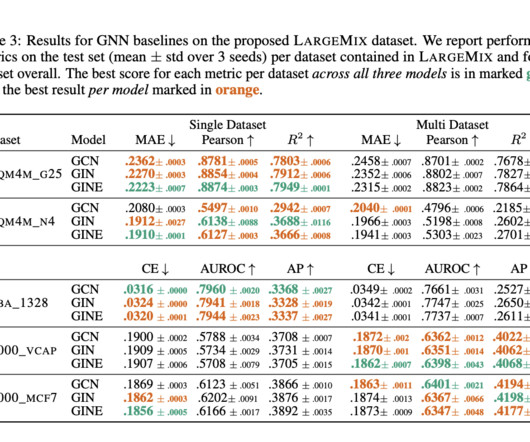







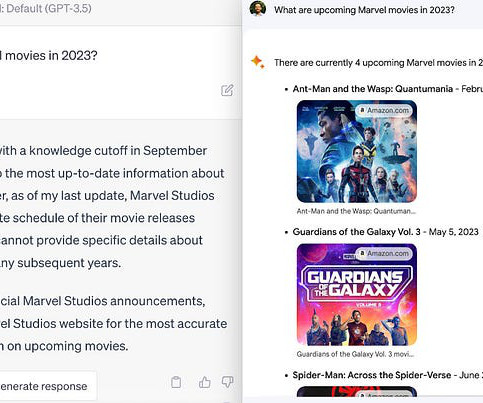



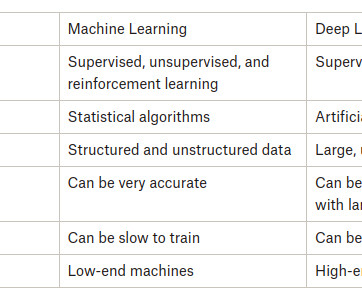











Let's personalize your content