
Cost-effective document classification using the Amazon Titan Multimodal Embeddings Model
AWS Machine Learning Blog
APRIL 11, 2024
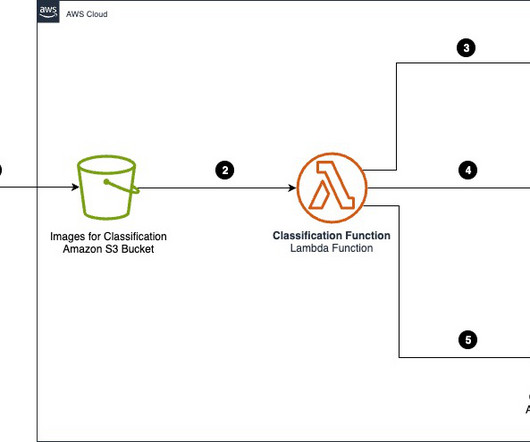
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizing documents is an important first step in IDP systems.









































Let's personalize your content