This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications. billion in 2025 to USD 66.68
The judiciary, like the legal system in general, is considered one of the largest “text processing industries” Language, documents, and texts are the raw material of legal and judicial work. As such, the judiciary has long been a field ripe for the use of technologies like automation to support the processing of documents.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Organizations across industries want to categorize and extract insights from high volumes of documents of different formats. Manually processing these documents to classify and extract information remains expensive, error prone, and difficult to scale. Categorizingdocuments is an important first step in IDP systems.
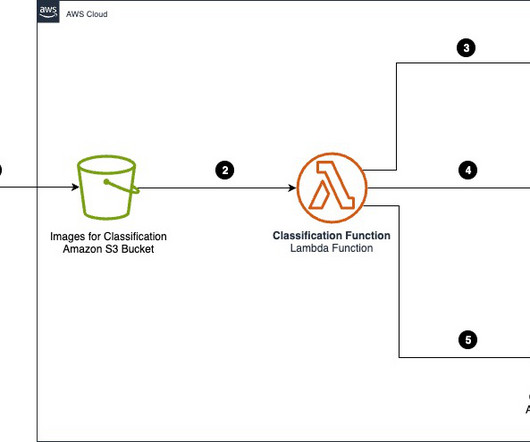
Access to car manuals and technical documentation helps the agent provide additional context for curated guidance, enhancing the quality of customer interactions. The workflow includes the following steps: Documents (owner manuals) are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
In today’s information age, the vast volumes of data housed in countless documents present both a challenge and an opportunity for businesses. Traditional document processing methods often fall short in efficiency and accuracy, leaving room for innovation, cost-efficiency, and optimizations. However, the potential doesn’t end there.
It’s ideal for workloads that aren’t latency sensitive, such as obtaining embeddings, entity extraction, FM-as-judge evaluations, and text categorization and summarization for business reporting tasks. It stores information such as job ID, status, creation time, and other metadata.
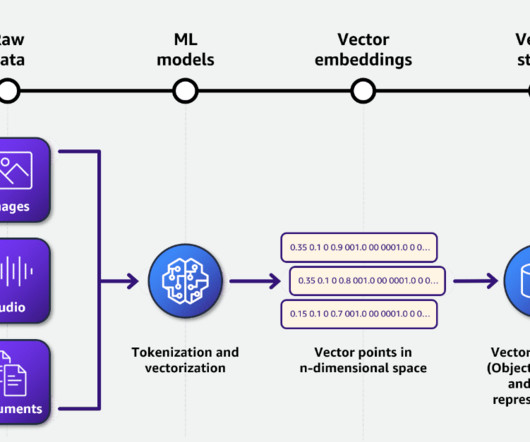
Most companies produce and consume unstructured data such as documents, emails, web pages, engagement center phone calls, and social media. Understanding the data, categorizing it, storing it, and extracting insights from it can be challenging. A metadata layer helps build the relationship between the raw data and AI extracted output.
Neglecting this preliminary stage may result in inaccurate tokenization, impacting subsequent tasks such as sentiment analysis, language modeling, or text categorization. Document Extraction: Unstructured is excellent at extracting metadata and document elements from a wide range of document types.
Broadly, Python speech recognition and Speech-to-Text solutions can be categorized into two main types: open-source libraries and cloud-based services. Sphinx is relatively lightweight compared to other speech-to-text solutions, supports multiple languages, and offers extensive developer documentation and FAQs.
The policy agent accesses the Policy Information API to extract answers to insurance-related questions from unstructured policy documents such as PDF files. The policy information agent is responsible for doing a lookup against the insurance policy documents stored in the knowledge base.
This centralized system consolidates a wide range of data sources, including detailed reports, FAQs, and technical documents. The system integrates structured data, such as tables containing product properties and specifications, with unstructured text documents that provide in-depth product descriptions and usage guidelines.
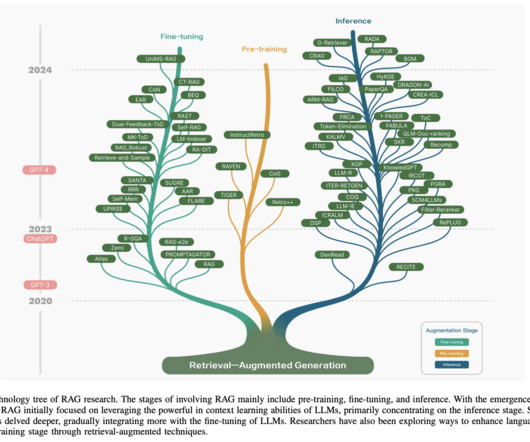
RAG enhances LLMs by retrieving relevant document chunks from the external knowledge base through semantic similarity calculation. The RAG research paradigm is continuously evolving, and RAG is categorized into three stages: Naive RAG, Advanced RAG, and Modular RAG.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. To increase the accuracy, we categorized the tables in four different types based on the schema and created four JSON files to store different tables. Weve added one dropdown menu with four choices.
Second, the information is frequently derived from natural language documents or a combination of structured, imaging, and document sources. OCR The first step of document processing is usually a conversion of scanned PDFs to text information. Thirdly, near-perfect precision is necessary for medical decision-making.
Some components are categorized in groups based on the type of functionality they exhibit. Hybrid search – In RAG, you may also optionally want to implement and expose different templates for performing hybrid search that help improve the quality of the retrieved documents. This logic sits in a hybrid search component.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. Model risk : Risk categorization of the model version.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. Images can often be searched using supplemented metadata such as keywords.
Manually analyzing and categorizing large volumes of unstructured data, such as reviews, comments, and emails, is a time-consuming process prone to inconsistencies and subjectivity. We provide a prompt example for feedback categorization. Extracting valuable insights from customer feedback presents several significant challenges.
Processing these images and scanned documents is not a cost- or time-efficient task for humans, and requires highly performant infrastructure that can reduce the time to value. Northpower categorized 1,853 poles as high priority risks, 3,922 as medium priority, 36,260 as low priority, and 15,195 as the lowest priority.
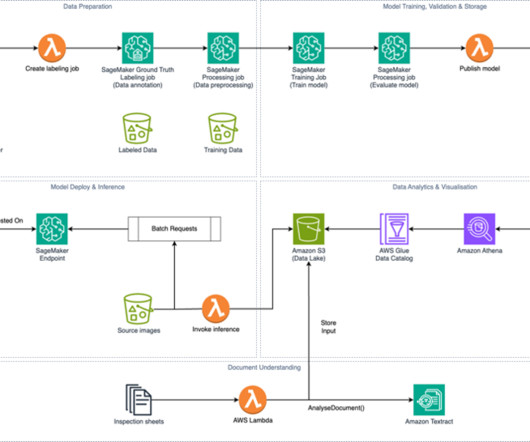
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. Amazon Textract has a Tables feature within the AnalyzeDocument API that offers the ability to automatically extract tabular structures from any document.
Tasks such as routing support tickets, recognizing customers intents from a chatbot conversation session, extracting key entities from contracts, invoices, and other type of documents, as well as analyzing customer feedback are examples of long-standing needs. We also examine the uplift from fine-tuning an LLM for a specific extractive task.
You can also include or exclude documents by using regular expressions. You can define patterns that Amazon Kendra either uses to exclude certain documents from indexing or include only documents with that pattern. In this next step, you can create field mappings to add an extra layer of metadata to your documents.
Using a user’s contextual metadata such as location, time of day, device type, and weather provides personalized experiences for existing users and helps improve the cold-start phase for new or unidentified users. API Gateway provides tools for creating and documenting APIs that route HTTP requests to Lambda functions.
RAG systems combine the strengths of reliable source documents with the generative capability of large language models (LLMs). After a user enters their query, the system retrieves relevant documents or document chunks from the vector database and adds them to the initial request as context.
Sentiment analysis, also known as opinion mining, is the process of computationally identifying and categorizing the subjective information contained in natural language text. An annotator in Spark NLP is a component that performs a specific NLP task on a text document and adds annotations to it. setInputCols(["document"]).setOutputCol("sentence_embeddings")
Text Classification: Categorize text into predefined groups for content moderation and tone detection. The official development workflow documentation can be found here. In addition, you can also add metadata with human-readable model descriptions as well as machine-readable data.
The capability of AI to execute complex tasks efficiently is determined by image annotation, which is a key determinant of its success and is defined as the process of labeling images with descriptive metadata. AI and machine learning applications require image annotation partners to label and categorize images.
Therefore, the data needs to be properly labeled/categorized for a particular use case. Text annotation assigns labels to a text document or various elements of its content. NLP Lab is a Free End-to-End No-Code AI platform for document labeling and AI/ML model training.
Building a tool for managing experiments can help your data scientists; 1 Keep track of experiments across different projects, 2 Save experiment-related metadata, 3 Reproduce and compare results over time, 4 Share results with teammates, 5 Or push experiment outputs to downstream systems.
You can add metadata to the policy by attaching tags as key-value pairs, then choose Next: Review. You can send batch predictions to QuickSight for numeric, categorical prediction, and time series forecasting models. You can learn more on the Canvas product page and documentation. Choose Next: Tags.
There is a target feature, static categorical features, time-varying known categorical features, time-varying known real features, and time-varying unknown real features. Static covariate encoders: This encoder is used to integrate static metadata into the network. Have a look at the Neptune-Lightning integration documentation.
These techniques can be applied to a wide range of data types, including numerical data, categorical data, text data, and more. is a document-oriented database that stores data in a semi-structured format (BSON, similar to JSON). NoSQL databases are often categorized into different types based on their data models and structures.
When preparing your CSV file for input into a SageMaker AutoML time series forecasting model, you must ensure that it includes at least three essential columns (as described in the SageMaker AutoML V2 documentation ): Item identifier attribute name : This column contains unique identifiers for each item or entity for which predictions are desired.
Igor Tsvetkov Former Senior Staff Software Engineer, Cruise AI teams automating error categorization and correlation can significantly reduce debugging time in hyperscale environments, just as Cruise has done. By using classification strategies to identify if failures originated from hardware constraints (e.g.,
Local Tracking with Database: You can use a local database to manage experiment metadata for a cleaner setup compared to local files. A nnotations and Descriptions: Markdown text for documenting models and versions. Tags: To label and categorize, attach key-value pairs to models and versions.
Operationalization journey per generative AI user type To simplify the description of the processes, we need to categorize the main generative AI user types, as shown in the following figure. We will cover monitoring in a separate post. words for English).
Methods for continual learning can be categorized as regularization-based, architectural, and memory-based, each with specific advantages and drawbacks. With continual learning, you can use each document to automatically retrain models, gradually adjusting it to the data the user uploads to the system.
Parallel computing Parallel computing refers to carrying out multiple processes simultaneously, and can be categorized according to the granularity at which parallelism is supported by the hardware. The following table shows the metadata of three of the largest accelerated compute instances. 32xlarge 0 16 0 128 512 512 4 x 1.9
LangChain categorizes its chains into three types: Utility chains, Generic chains, and Combine Documents chains. This function collects the most recent NLP paper summaries from arXiv and encapsulates them into LangChain Document objects, using the summary as content and the unique entry id as the source.
Recent Progress Recent progress in this area can be categorized into two categories: 1) new groups, communities, support structures, and initiatives that have enabled broader work; and 2) high-level research contributions such as new datasets and models that allow others to build on them. Joshi et al. [92] Lucassen, T., Chaudhary, V.,
The resulting learned embeddings and associated metadata as features is then inputted to a survival model for predicting 10-year incidence of major adverse cardiac events. Instead, the idea is to focus on the not-fun parts, like processing incoming issues, matching questions to existing documentation, and so on.
Use cases for vector databases for RAG In the context of RAG architectures, the external knowledge can come from relational databases, search and document stores, or other data stores. Knowledge bases are essential for various use cases, such as customer support, product documentation, internal knowledge sharing, and decision-making systems.
Document summarization : Process vast amounts of business content in real time, such as summarizing thousands of customer call transcripts daily, enabling insights at a scale previously limited by latency constraints. You can optionally add request metadata to these inference requests to filter your invocation logs for specific use cases.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content