This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This story explores CatBoost, a powerful machine-learning algorithm that handles both categorical and numerical data easily. CatBoost is a powerful, gradient-boosting algorithm designed to handle categoricaldata effectively. But what if we could predict a student’s engagement level before they begin? What is CatBoost?
Traditional customer segmentation methods are limited in scope, often categorizing customers into broad groups. These include a commitment to engineering excellence, adaptability, scalability, and ethical transparency: Precision in Model Development AI models are only as effective as the data and design behind them.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
Akeneos Product Cloud solution has PIM, syndication, and supplier data manager capabilities, which allows retailers to have all their product data in one spot. A good product search and discovery experience relies on products being accurately tagged, categorized, and syndicated to the right channels.
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. Other analyses are also available to help you visualize and understand your data.
A Comprehensive Data Science Guide to Preprocessing for Success: From Missing Data to Imbalanced Datasets This member-only story is on us. In just about any organization, the state of information quality is at the same low level – Olson, DataQualityData is everywhere! Upgrade to access all of Medium.
Generative AI has the potential to deliver powerful support in key data areas: Master data cleansing to reduce duplications and flag outliers. Master data enrichment to enhance categorization and materials attributes. Master dataquality to improve scoring, prioritization and automated validation of data.
In the early days of online shopping, ecommerce brands were categorized as online stores or “multichannel” businesses operating both ecommerce sites and brick-and-mortar locations. To ensure the success of this approach, it is crucial to maintain a strong focus on dataquality, security and ethical considerations.
UniBench categorizes these benchmarks into seven types and seventeen finer-grained capabilities, allowing researchers to quickly identify model strengths and weaknesses in a standardized manner. The framework assesses these models across 53 diverse benchmarks, categorized into seven types and seventeen capabilities.
.” “When we think about applications of AI to solve real business problems, what we find is that these specialty models are becoming more important,” says Brent Smolinksi, IBM’s Global Head of Tech, Data and AI Strategy. In this context, dataquality often outweighs quantity.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data.
It offers both open-source and enterprise/paid versions and facilitates big data management. Key Features: Seamless integration with cloud and on-premise environments, extensive dataquality, and governance tools. Pros: Scalable, strong data governance features, support for big data. Visit Hevo Data → 7.
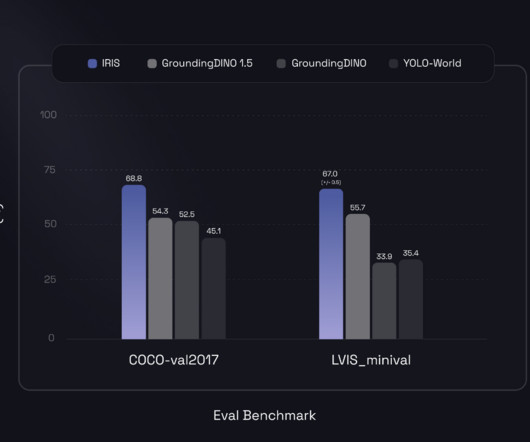
For example, when instructed to “Identify all animals in the image,” IRIS will prioritize detecting and categorizing things that resemble animals. Next, IRIS uses its training data to examine the input image and identify possible items, scenes, or actions. IRIS is an AI agent that can label visual data with prompting.
The model learning phase utilizes time series data from production calls and simulations to categorize network types and optimize parameters. The architecture combines LSTM layers for processing time series data and dense layers for non-time series data, enabling accurate modeling of network conditions.
In the past, the business relied on a conventional approach to segmentation, categorizing customers by geographic location, based on the underlying assumption that farmers from the same region would have similar needs. In those cases, a traditional approach run by humans can work better, especially if you mainly have qualitative data.
Almost half of AI projects are doomed by poor dataquality, inaccurate or incomplete datacategorization, unstructured data, and data silos. Avoid these 5 mistakes
We also detail the steps that data scientists can take to configure the data flow, analyze the dataquality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Data Wrangler creates the report from the sampled data.
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. They can search within specific categories to narrow down results.
While effective in creating a base for model training, this foundational approach confronts substantial challenges, notably in ensuring dataquality, mitigating biases, and adequately representing lesser-known languages and dialects. A recent survey by researchers from South China University of Technology, INTSIG Information Co.,
More crucially, they include 40+ quality annotations — the result of multiple ML classifiers on dataquality, minhash results that may be used for fuzzy deduplication, or heuristics. They assert its coverage of CommonCrawl (84 processed dumps) is unparalleled. Check out the Github and Reference Blog.
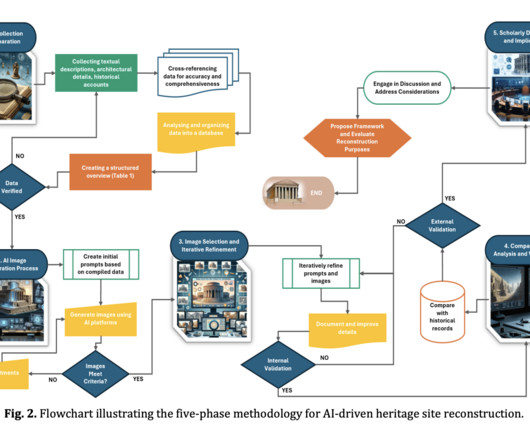
In more detail, the authors proposed to follow the following approach in their methodology: First, they collect and organize textual descriptions, architectural details, and historical records from various scholarly sources to ensure a comprehensive dataset categorized, which serves as the foundation for generating accurate textual prompts.
Here are just a few: Dataquality. In production, machine learning models may encounter data that differs from the training data, such as missing values, noise, or outliers. Ensuring dataquality and consistency is critical to maintaining model robustness. Concept drift.
Data engineering is crucial in today’s digital landscape as organizations increasingly rely on data-driven insights for decision-making. Learning data engineering ensures proficiency in designing robust data pipelines, optimizing data storage, and ensuring dataquality.
Models are trained on these data pools, enabling in-depth analysis of OP effectiveness and its correlation with model performance across various quantitative and qualitative indicators. In their methodology, the researchers implemented a hierarchical data pyramid, categorizingdata pools based on their ranked model metric scores.
To learn more about how to use natural language to explore and prepare data, refer to Use natural language to explore and prepare data with a new capability of Amazon SageMaker Canvas. On the Analyses tab, choose DataQuality and Insights Report. Choose Preview model to ensure there are no dataquality issues.
Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required. Perform dataquality checks and develop procedures for handling issues. Typical dataquality checks and corrections include: Missing data or incomplete records Inconsistent data formatting (e.g.,
Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias. What are the biggest challenges in machine learning? select all that apply) Related to the previous question, these are a few issues faced in machine learning.
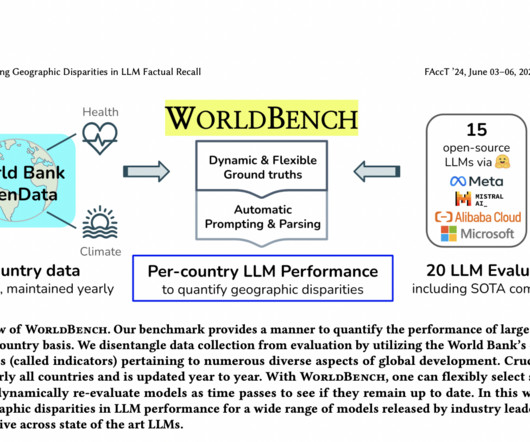
This approach offers several unique advantages: equitable representation of all countries, assured dataquality from a reputable source, and flexibility in indicator selection. WorldBench is constructed using statistics from the World Bank, a global organization tracking numerous development indicators across nearly 200 countries.
Methodology: Synthetic Data Generation with LLMs To overcome these limitations, the researchers propose a novel single-stage training approach that leverages LLMs like GPT-3 and GPT-4 to generate diverse synthetic training data.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Challenges of building custom LLMs Building custom Large Language Models (LLMs) presents an array of challenges to organizations that can be broadly categorized under data, technical, ethical, and resource-related issues. Ensuring dataquality during collection is also important.
Resources from DigitalOcean and GitHub help us categorize these agents based on their capabilities and operational approaches. Challenges Implementation Complexity: Integrating AI agents into existing systems can be a demanding process, often requiring careful planning around data integration, legacy system compatibility, and security.
Our experiments demonstrate that careful attention to dataquality, hyperparameter optimization, and best practices in the fine-tuning process can yield substantial gains over base models. Conclusion Fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock offers significant performance improvements for specialized tasks.
Starting with a dataset that has details about loan default data in Amazon Simple Storage Service (Amazon S3), we use SageMaker Canvas to gain insights about the data. We then perform feature engineering to apply transformations such as encoding categorical features, dropping features that are not needed, and more.
The researchers present a categorization system that uses backbone networks to organize these methods. The researchers highlight that big, high-quality datasets are required to train and optimize deep learning models because of how important dataquality and label accuracy are in this process.
If you want an overview of the Machine Learning Process, it can be categorized into 3 wide buckets: Collection of Data: Collection of Relevant data is key for building a Machine learning model. It isn't easy to collect a good amount of qualitydata. How Machine Learning Works?
Some components are categorized in groups based on the type of functionality they exhibit. The AWS managed offering ( SageMaker Ground Truth Plus ) designs and customizes an end-to-end workflow and provides a skilled AWS managed team that is trained on specific tasks and meets your dataquality, security, and compliance requirements.
The data scientist discovers and subscribes to data and ML resources, accesses the data from SageMaker Canvas, prepares the data, performs feature engineering, builds an ML model, and exports the model back to the Amazon DataZone catalog. A new data flow is created on the Data Wrangler console.
However, analysis of data may involve partiality or incorrect insights in case the dataquality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher dataquality as per business requirements. Determine the range of values for categorical columns.
Scalability : A data pipeline is designed to handle large volumes of data, making it possible to process and analyze data in real-time, even as the data grows. Dataquality : A data pipeline can help improve the quality of data by automating the process of cleaning and transforming the data.
Photo by Bruno Nascimento on Unsplash Introduction Data is the lifeblood of Machine Learning Models. The dataquality is critical to the performance of the model. The better the data, the greater the results will be. Before we feed data into a learning algorithm, we need to make sure that we pre-process the data.
Pixability is a data and technology company that allows advertisers to quickly pinpoint the right content and audience on YouTube. To help brands maximize their reach, they need to constantly and accurately categorize billions of YouTube videos. Using AI to help customers optimize ad spending and maximize their reach on YouTube.
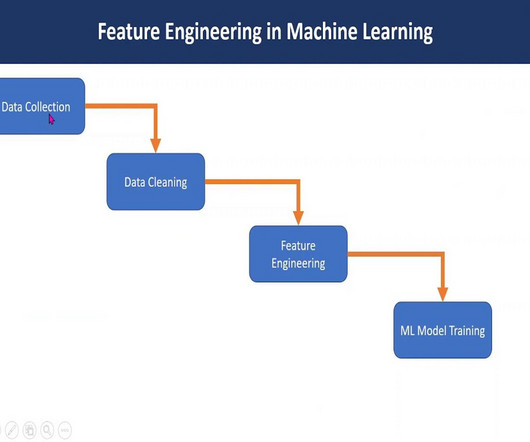
Feature Engineering enhances model performance, and interpretability, mitigates overfitting, accelerates training, improves dataquality, and aids deployment. Feature Engineering is the art of transforming raw data into a format that Machine Learning algorithms can comprehend and leverage effectively.
In the data flow view, you can now see a new node added to the visual graph. For more information on how you can use SageMaker Data Wrangler to create DataQuality and Insights Reports, refer to Get Insights On Data and DataQuality. SageMaker Data Wrangler offers over 300 built-in transformations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content