This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprise streaming analytics firm Streambased aims to help organisations extract impactful business insights from these continuous flows of operational event data. In an interview at the recent AI & BigData Expo , Streambased founder and CEO Tom Scott outlined the company’s approach to enabling advanced analytics on streaming data.
When we talk about data integrity, we’re referring to the overarching completeness, accuracy, consistency, accessibility, and security of an organization’s data. Together, these factors determine the reliability of the organization’s data. DataqualityDataquality is essentially the measure of data integrity.
Fragmented data stacks, combined with the promise of generative AI, amplify productivity pressure and expose gaps in enterprise readiness for this emerging technology. While turning data into meaningful intelligence is crucial, users such as analysts and datascientists are increasingly overwhelmed by vast quantities of information.
It serves as the hub for defining and enforcing data governance policies, data cataloging, data lineage tracking, and managing data access controls across the organization. Data lake account (producer) – There can be one or more data lake accounts within the organization.
Connecting AI models to a myriad of data sources across cloud and on-premises environments AI models rely on vast amounts of data for training. Once trained and deployed, models also need reliable access to historical and real-time data to generate content, make recommendations, detect errors, send proactive alerts, etc.
Data Science focuses on analysing data to find patterns and make predictions. Data engineering, on the other hand, builds the foundation that makes this analysis possible. Without well-structured data, DataScientists cannot perform their work efficiently.
Summary: A comprehensive BigData syllabus encompasses foundational concepts, essential technologies, data collection and storage methods, processing and analysis techniques, and visualisation strategies. Fundamentals of BigData Understanding the fundamentals of BigData is crucial for anyone entering this field.
An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more. For example, data catalogs have evolved to deliver governance capabilities like managing dataquality and data privacy and compliance.
This framework creates a central hub for feature management and governance with enterprise feature store capabilities, making it straightforward to observe the data lineage for each feature pipeline, monitor dataquality , and reuse features across multiple models and teams.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Jay Mishra is the Chief Operating Officer (COO) at Astera Software , a rapidly-growing provider of enterprise-ready data solutions. I would say modern tool sets that are designed keeping in view the requirements of the new age data that we are receiving have changed in in past few years and the volume of course has changed.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. A self-service infrastructure portal for infrastructure and governance.
Amazon DataZone allows you to create and manage data zones , which are virtual data lakes that store and process your data, without the need for extensive coding or infrastructure management. Solution overview In this section, we provide an overview of three personas: the data admin, data publisher, and datascientist.
In addition, organizations that rely on data must prioritize dataquality review. Data profiling is a crucial tool. For evaluating dataquality. Data profiling gives your company the tools to spot patterns, anticipate consumer actions, and create a solid data governance plan.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for datascientists to select and clean data, create features, and automate data preparation in ML workflows without writing any code.
When a new version of the model is registered in the model registry, it triggers a notification to the responsible datascientist via Amazon SNS. If the batch inference pipeline discovers dataquality issues, it will notify the responsible datascientist via Amazon SNS.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
Going from Data to Insights LexisNexis At HPCC Systems® from LexisNexis® Risk Solutions you’ll find “a consistent data-centric programming language, two processing platforms, and a single, complete end-to-end architecture for efficient processing.” These tools are designed to help companies derive insights from bigdata.
Amazon SageMaker Studio provides a fully managed solution for datascientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow datascientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
Data Management and Preprocessing for Accurate Predictions DataQuality is Paramount: The foundation of robust ML in demand forecasting lies in high-qualitydata. Retailers must ensure data is clean, consistent, and free from anomalies. Consistently review and purify data to uphold its accuracy.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
BigData Analytics This involves analyzing massive datasets that are too large and complex for traditional data analysis methods. BigData Analytics is used in healthcare to improve operational efficiency, identify fraud, and conduct large-scale population health studies.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. About the authors Ram Vittal is a Principal ML Solutions Architect at AWS.
The advent of bigdata, affordable computing power, and advanced machine learning algorithms has fueled explosive growth in data science across industries. However, research shows that up to 85% of data science projects fail to move beyond proofs of concept to full-scale deployment.
It utilises the Hadoop Distributed File System (HDFS) and MapReduce for efficient data management, enabling organisations to perform bigdata analytics and gain valuable insights from their data. In a Hadoop cluster, data stored in the Hadoop Distributed File System (HDFS), which spreads the data across the nodes.
Introduction Data Engineering is the backbone of the data-driven world, transforming raw data into actionable insights. As organisations increasingly rely on data to drive decision-making, understanding the fundamentals of Data Engineering becomes essential. ETL is vital for ensuring dataquality and integrity.
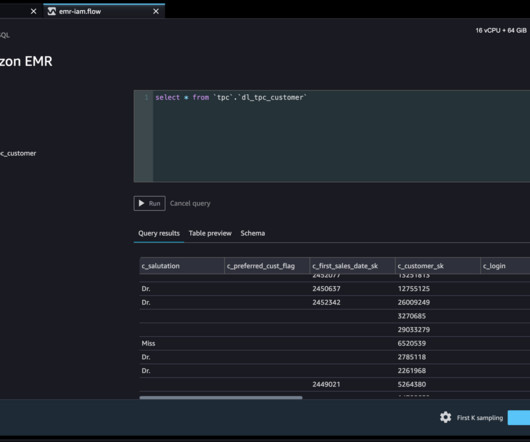
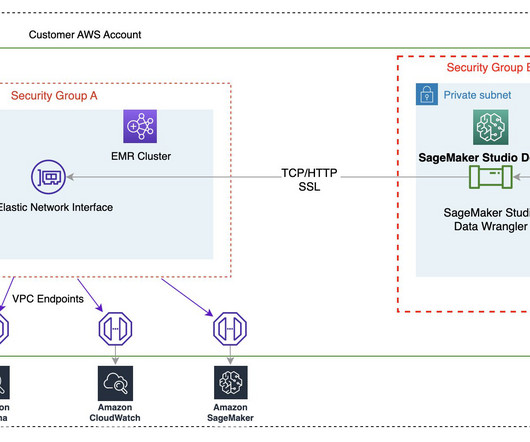
We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. In this post, we show how to use Lake Formation as a central data governance capability and Amazon EMR as a bigdata query engine to enable access for SageMaker Data Wrangler.
It involves the design, development, and maintenance of systems, tools, and processes that enable the acquisition, storage, processing, and analysis of large volumes of data. Data Engineers work to build and maintain data pipelines, databases, and data warehouses that can handle the collection, storage, and retrieval of vast amounts of data.
Cons: Complexity: Managing and securing a data lake involves intricate tasks that require careful planning and execution. DataQuality: Without proper governance, dataquality can become an issue. Performance: Query performance can be slower compared to optimized data stores.
See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge", These are key files calculated from raw data used as a baseline.
Lucrative job opportunities post-MBA include roles like DataScientist, Business Analytics Manager, Chief Data Officer, and more, spanning diverse industries. BI Analysts work closely with stakeholders, using data to drive business strategy, optimise processes, and enhance organisational performance.
Data Wrangler enables you to access data from a wide variety of popular sources ( Amazon S3 , Amazon Athena , Amazon Redshift , Amazon EMR and Snowflake) and over 40 other third-party sources. Starting today, you can connect to Amazon EMR Hive as a bigdata query engine to bring in large datasets for ML.
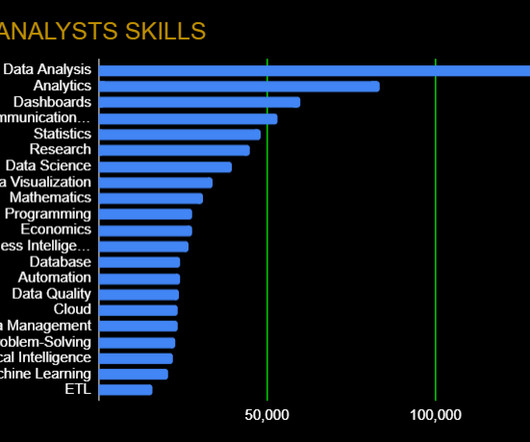
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: DataQuality, ETL, Databases, BigData The modern data analyst is expected to be able to source and retrieve their own data for analysis.
It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality. Introduction Data preprocessing is a critical step in the Machine Learning pipeline, transforming raw data into a clean and usable format.
Data Science helps businesses uncover valuable insights and make informed decisions. Programming for Data Science enables DataScientists to analyze vast amounts of data and extract meaningful information. 8 Most Used Programming Languages for Data Science 1.
This phase is crucial for enhancing dataquality and preparing it for analysis. Transformation involves various activities that help convert raw data into a format suitable for reporting and analytics. Normalisation: Standardising data formats and structures, ensuring consistency across various data sources.
Empowering DataScientists and Machine Learning Engineers in Advancing Biological Research Image from European Bioinformatics Institute Introduction: In biological research, the fusion of biology, computer science, and statistics has given birth to an exciting field called bioinformatics.
Such growth makes it difficult for many enterprises to leverage bigdata; they end up spending valuable time and resources just trying to manage data and less time analyzing it. What are the big differentiators between HPCC Systems and other bigdata tools? Spark is indeed a popular bigdata tool.
Cybersecurity Analyst Safeguarding organisations by analysing data to identify and prevent cyber threats, ensuring the security and integrity of digital systems. Spatial DataScientist Utilising geographical data to gain insights, solve location-based problems, and contribute to urban planning, environmental conservation, and logistics.
Knowledge of Cloud Computing and BigData Tools As complex Machine Learning (ML) models grow, robust infrastructure for large datasets and intensive computations becomes increasingly important. BigData Tools Integration Bigdata tools like Apache Spark and Hadoop are vital for managing and processing massive datasets.
HPCC Systems — The Kit and Kaboodle for BigData and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated data lake platform.
With the exponential growth of data and increasing complexities of the ecosystem, organizations face the challenge of ensuring data security and compliance with regulations. In addition, it also defines the framework wherein it is decided what action needs to be taken on certain data.
It involves breaking down the data into smaller chunks that can be processed in parallel across multiple nodes, and then combining the results of those processing tasks to produce a final output. Batch Processing Design Pattern The batch Processing Design Pattern is commonly used for processing large amounts of data in batches.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content