This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Welcome to the transformative world of NaturalLanguageProcessing (NLP). Here, the elegance of human language meets the precision of machine intelligence. The unseen force of NLP powers many of the digital interactions we rely on.
This article was published as a part of the Data Science Blogathon Introduction In the past few years, Naturallanguageprocessing has evolved a lot using deep neural networks. BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers.
Overview Here’s a list of the most important NaturalLanguageProcessing (NLP) frameworks you need to know in the last two years From Google. The post A Complete List of Important NaturalLanguageProcessing Frameworks you should Know (NLP Infographic) appeared first on Analytics Vidhya.
Overview Google’s BERT has transformed the NaturalLanguageProcessing (NLP) landscape Learn what BERT is, how it works, the seismic impact it has made, The post Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework appeared first on Analytics Vidhya.
It’s the beauty of NaturalLanguageProcessing’s Transformers. The post Comprehensive Guide to BERT appeared first on Analytics Vidhya. A Quick Recap of Transformers in NLP A transformer has rapidly become the dominant […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction NLP or NaturalLanguageProcessing is an exponentially growing field. The post Why and how to use BERT for NLP Text Classification? appeared first on Analytics Vidhya.
Large Language Models like BERT, T5, BART, and DistilBERT are powerful tools in naturallanguageprocessing where each is designed with unique strengths for specific tasks. Whether it’s summarization, question answering, or other NLP applications.
Since its introduction in 2018, BERT has transformed NaturalLanguageProcessing. It performs well in tasks like sentiment analysis, question answering, and language inference. However, despite its success, BERT has limitations.
The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya. Introduction With the advancement in deep learning, neural network architectures like recurrent neural networks (RNN and LSTM) and convolutional neural networks (CNN) have shown.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction NaturalLanguageprocessing, a sub-field of machine learning has gained. The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya.
Introduction A highly effective method in machine learning and naturallanguageprocessing is topic modeling. A corpus of text is an example of a collection of documents. This technique involves finding abstract subjects that appear there.
Introduction Named Entity Recognition is a major task in NaturalLanguageProcessing (NLP) field. The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya.
The Challenge Legal texts are uniquely challenging for naturallanguageprocessing (NLP) due to their specialized vocabulary, intricate syntax, and the critical importance of context. Terms that appear similar in general language can have vastly different meanings in legal contexts.
ModernBERT is an advanced iteration of the original BERT model, meticulously crafted to elevate performance and efficiency in naturallanguageprocessing (NLP) tasks.
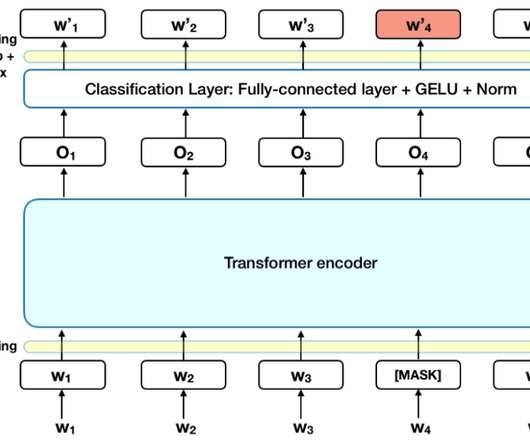
Introduction BERT, short for Bidirectional Encoder Representations from Transformers, is a system leveraging the transformer model and unsupervised pre-training for naturallanguageprocessing. Being pre-trained, BERT learns beforehand through two unsupervised tasks: masked language modeling and sentence prediction.
NaturalLanguageProcessing (NLP) has experienced some of the most impactful breakthroughs in recent years, primarily due to the the transformer architecture. BERT T5 (Text-to-Text Transfer Transformer) : Introduced by Google in 2020 , T5 reframes all NLP tasks as a text-to-text problem, using a unified text-based format.
Introduction With the advent of Large Language Models (LLMs), they have permeated numerous applications, supplanting smaller transformer models like BERT or Rule Based Models in many NaturalLanguageProcessing (NLP) tasks.
Unlocking the Future of Language: The Next Wave of NLP Innovations Photo by Joshua Hoehne on Unsplash The world of technology is ever-evolving, and one area that has seen significant advancements is NaturalLanguageProcessing (NLP). A few years back, two groundbreaking models, BERT and GPT, emerged as game-changers.
SAS' Ali Dixon and Mary Osborne reveal why a BERT-based classifier is now part of our naturallanguageprocessing capabilities of SAS Viya. The post How naturallanguageprocessing transformers can provide BERT-based sentiment classification on March Madness appeared first on SAS Blogs.
NaturalLanguageProcessing (NLP) is integral to artificial intelligence, enabling seamless communication between humans and computers. Researchers from East China University of Science and Technology and Peking University have surveyed the integrated retrieval-augmented approaches to language models.
Overview Neural fake news (fake news generated by AI) can be a huge issue for our society This article discusses different NaturalLanguageProcessing. The post An Exhaustive Guide to Detecting and Fighting Neural Fake News using NLP appeared first on Analytics Vidhya.
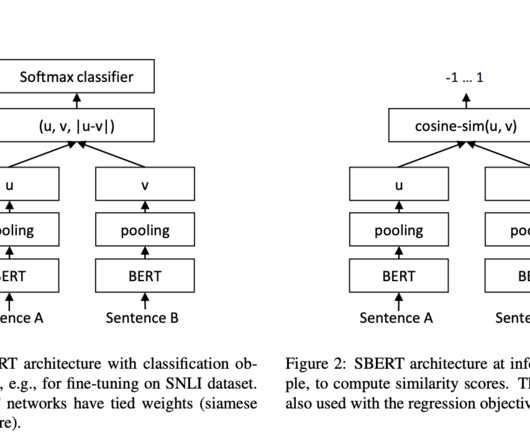
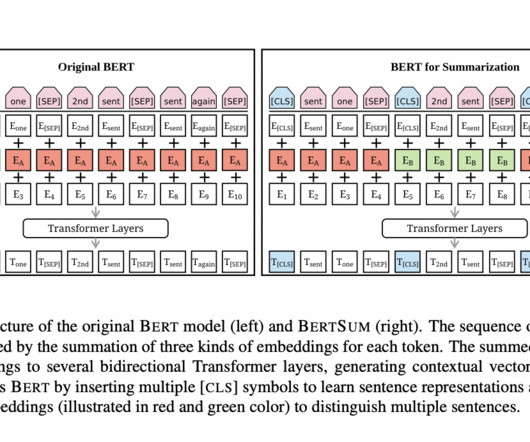
Text summarization is an NLP(NaturalLanguageProcessing) task. SBERT(Sentence-BERT) has […]. Dear readers, In this blog, we will build a Flask web app that can input any long piece of information such as a blog or news article and summarize it into just five lines!
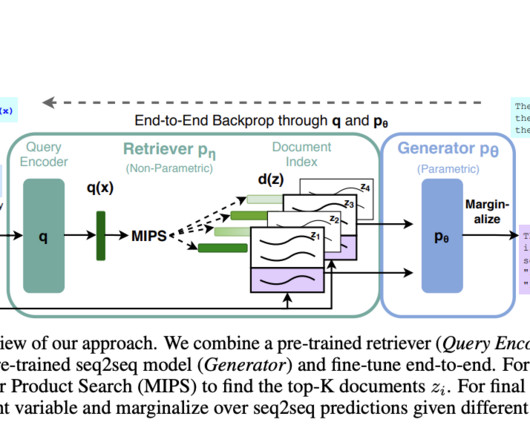
Knowledge-intensive NaturalLanguageProcessing (NLP) involves tasks requiring deep understanding and manipulation of extensive factual information. Existing research includes frameworks like REALM and ORQA, which integrate pre-trained neural language models with differentiable retrievers for enhanced knowledge access.
Introduction Welcome into the world of Transformers, the deep learning model that has transformed NaturalLanguageProcessing (NLP) since its debut in 2017. These linguistic marvels, armed with self-attention mechanisms, revolutionize how machines understand language, from translating texts to analyzing sentiments.
Bridging the Gap with NaturalLanguageProcessingNaturalLanguageProcessing (NLP) stands at the forefront of bridging the gap between human language and AI comprehension. NLP enables machines to understand, interpret, and respond to human language in a meaningful way.
Photo by Amr Taha™ on Unsplash In the realm of artificial intelligence, the emergence of transformer models has revolutionized naturallanguageprocessing (NLP). In this guide, we will explore how to fine-tune BERT, a model with 110 million parameters, specifically for the task of phishing URL detection.
They process and generate text that mimics human communication. At the leading edge of NaturalLanguageProcessing (NLP) , models like GPT-4 are trained on vast datasets. They understand and generate language with high accuracy. How LLMs Process and Store Information?
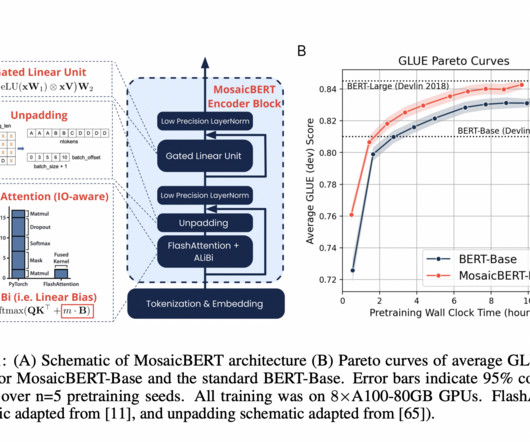
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35
Introduction Large language models (LLMs) are increasingly becoming powerful tools for understanding and generating human language. These models have achieved state-of-the-art results on different naturallanguageprocessing tasks, including text summarization, machine translation, question answering, and dialogue generation.
Source: totaljobs.com Introduction Transformers have become a powerful tool for different naturallanguageprocessing tasks. This article was published as a part of the Data Science Blogathon. The impressive performance of the transformer is mainly attributed to its self-attention mechanism.
techcrunch.com The Essential Artificial Intelligence Glossary for Marketers (90+ Terms) BERT - Bidirectional Encoder Representations from Transformers (BERT) is Google’s deep learning model designed explicitly for naturallanguageprocessing tasks like answering questions, analyzing sentiment, and translation.
Both BERT and GPT are based on the Transformer architecture. Word embedding is a technique in naturallanguageprocessing (NLP) where words are represented as vectors in a continuous vector space. It was the Attention Mechanism breakthrough that gave birth to Large Pre-Trained Models and Transformers.
Researchers have focused on developing and building models to process and compare human language in naturallanguageprocessing efficiently. This technology is crucial for semantic search, clustering, and naturallanguage inference tasks.
Encoder models like BERT and RoBERTa have long been cornerstones of naturallanguageprocessing (NLP), powering tasks such as text classification, retrieval, and toxicity detection. For example, GTEs contrastive learning boosts retrieval performance but cannot compensate for BERTs obsolete embeddings.
One of the most promising areas within AI in healthcare is NaturalLanguageProcessing (NLP), which has the potential to revolutionize patient care by facilitating more efficient and accurate data analysis and communication.
Language model pretraining has significantly advanced the field of NaturalLanguageProcessing (NLP) and NaturalLanguage Understanding (NLU). Models like GPT, BERT, and PaLM are getting popular for all the good reasons. Models like GPT, BERT, and PaLM are getting popular for all the good reasons.
Take, for instance, word embeddings in naturallanguageprocessing (NLP). BERT and its Variants : BERT (Bidirectional Encoder Representations from Transformers) by Google, is another significant model that has seen various updates and iterations like RoBERTa, and DistillBERT.
Rust aids in this process by speeding up the execution time, ensuring that the tokenization process is not just accurate but also swift, enhancing the efficiency of naturallanguageprocessing tasks. We choose a BERT model fine-tuned on the SQuAD dataset.
Introduction Embark on a journey through the evolution of artificial intelligence and the astounding strides made in NaturalLanguageProcessing (NLP). The seismic impact of finetuning large language models has utterly transformed NLP, revolutionizing our technological interactions.
In this post, we demonstrate how to use neural architecture search (NAS) based structural pruning to compress a fine-tuned BERT model to improve model performance and reduce inference times. First, we use an Amazon SageMaker Studio notebook to fine-tune a pre-trained BERT model on a target task using a domain-specific dataset.
In recent years, NaturalLanguageProcessing (NLP) has undergone a pivotal shift with the emergence of Large Language Models (LLMs) like OpenAI's GPT-3 and Google’s BERT. Beyond traditional search engines, these models represent a new era of intelligent Web browsing agents that go beyond simple keyword searches.
Attention Mechanism Image Source Course difficulty: Intermediate-level Completion time: ~ 45 minutes Prerequisites: Knowledge of ML, DL, NaturalLanguageProcessing (NLP) , Computer Vision (CV), and Python programming. Covers the different NLP tasks for which a BERT model is used. What will AI enthusiasts learn?
LLMs are deep neural networks that can generate naturallanguage texts for various purposes, such as answering questions, summarizing documents, or writing code. LLMs, such as GPT-4 , BERT , and T5 , are very powerful and versatile in NaturalLanguageProcessing (NLP).
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They have seen an increase of 56% transaction classification accuracy after moving to the new BERT based model.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content