This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction LargeLanguageModels (LLMs) are foundational machine learning models that use deep learning algorithms to process and understand natural language. These models are trained on massive amounts of text data to learn patterns and entity relationships in the language.
LargeLanguageModels like BERT, T5, BART, and DistilBERT are powerful tools in natural language processing where each is designed with unique strengths for specific tasks. These models vary in their architecture, performance, and efficiency.
A great example is the announcement that BERTmodels are now a significant force behind Google Search. Google believes that this move […] The post Building LanguageModels: A Step-by-Step BERT Implementation Guide appeared first on Analytics Vidhya.
A New Era of Language Intelligence At its essence, ChatGPT belongs to a class of AI systems called LargeLanguageModels , which can perform an outstanding variety of cognitive tasks involving natural language. From LanguageModels to LargeLanguageModels How good can a languagemodel become?
Introduction In the realm of artificial intelligence, a transformative force has emerged, capturing the imaginations of researchers, developers, and enthusiasts alike: largelanguagemodels.
Introduction In the rapidly evolving landscape of artificial intelligence, especially in NLP, largelanguagemodels (LLMs) have swiftly transformed interactions with technology. This article explores […] The post Exploring the Use of LLMs and BERT for Language Tasks appeared first on Analytics Vidhya.
The seismic impact of finetuning largelanguagemodels has utterly transformed NLP, revolutionizing our technological interactions. Rewind to 2017, a pivotal moment marked by […] The post Beginners’ Guide to Finetuning LargeLanguageModels (LLMs) appeared first on Analytics Vidhya.
Traditional techniques include reconstruction-based methods (such as autoencoders and GANs), which rely on training models to reconstruct normal log sequences and detect anomalies based on reconstruction errors. It leverages BERT to extract semantic vectors and uses Llama, a transformer decoder, for log sequence classification.
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. This includes the ability to incorporate custom terminology and domain-specific knowledge.
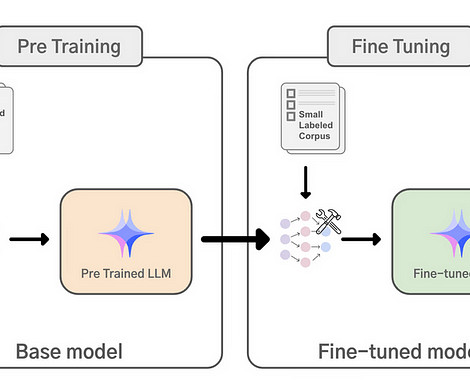
Fine-tuning largelanguagemodels (LLMs) has become an easier task today thanks to the availability of low-code/no-code tools that allow you to simply upload your data, select a base model and obtain a fine-tuned model. However, it is important to understand the fundamentals before diving into these tools.
Introduction With the advent of LargeLanguageModels (LLMs), they have permeated numerous applications, supplanting smaller transformer models like BERT or Rule Based Models in many Natural Language Processing (NLP) tasks.
In the ever-evolving domain of Artificial Intelligence (AI), where models like GPT-3 have been dominant for a long time, a silent but groundbreaking shift is taking place. Small LanguageModels (SLM) are emerging and challenging the prevailing narrative of their larger counterparts.
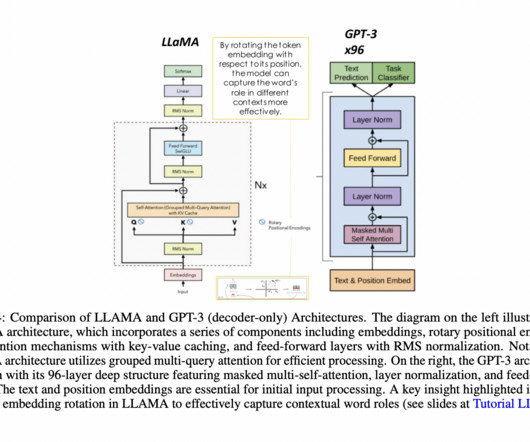
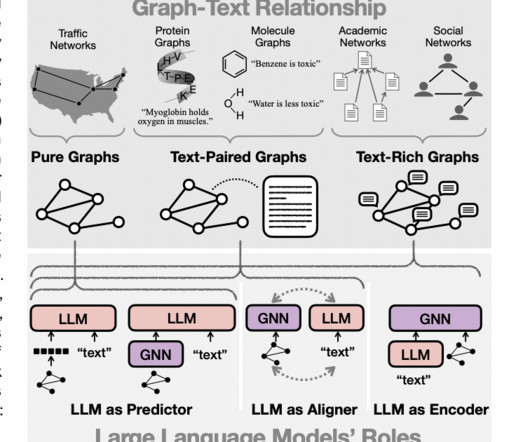
In parallel, LargeLanguageModels (LLMs) like GPT-4, and LLaMA have taken the world by storm with their incredible natural language understanding and generation capabilities. In this article, we will delve into the latest research at the intersection of graph machine learning and largelanguagemodels.
Think of it as just rewriting key points or summary in a book instead of the whole story.QLoRA: It applies LoRA techniques to a model that is already compressed using 4 bit quantization(we will go through it). It is efficient, elegant, and powerful. QLoRA stands for Quantized Low-Rank Adaptation.
They serve as a core building block in many natural language processing (NLP) applications today, including information retrieval, question answering, semantic search and more. vector embedding Recent advances in largelanguagemodels (LLMs) like GPT-3 have shown impressive capabilities in few-shot learning and natural language generation.
However, among all the modern-day AI innovations, one breakthrough has the potential to make the most impact: largelanguagemodels (LLMs). Largelanguagemodels can be an intimidating topic to explore, especially if you don't have the right foundational understanding. What Is a LargeLanguageModel?
Introduction LargeLanguageModel Operations (LLMOps) is an extension of MLOps, tailored specifically to the unique challenges of managing large-scale languagemodels like GPT, PaLM, and BERT.
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
Are you curious about the intricate world of largelanguagemodels (LLMs) and the technical jargon that surrounds them? LLM (LargeLanguageModel) LargeLanguageModels (LLMs) are advanced AI systems trained on extensive text datasets to understand and generate human-like text.
The existing methods have been supported by the code, benchmarking setup, and model weights provided by the researchers at ETH Zurich. They have also suggested exploring multiple FFF trees for joint computation and the potential application in largelanguagemodels like GPT-3. of its neurons during inference.
Machines are demonstrating remarkable capabilities as Artificial Intelligence (AI) advances, particularly with LargeLanguageModels (LLMs). At the leading edge of Natural Language Processing (NLP) , models like GPT-4 are trained on vast datasets. They process and generate text that mimics human communication.
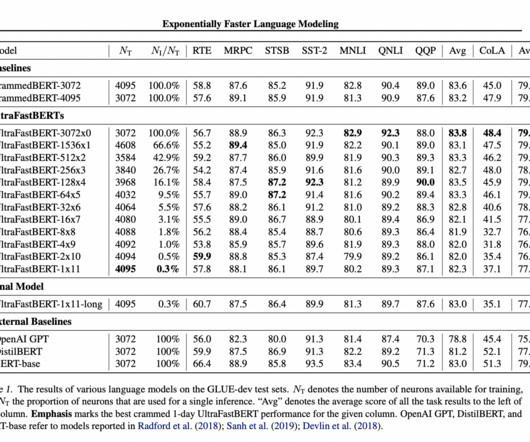
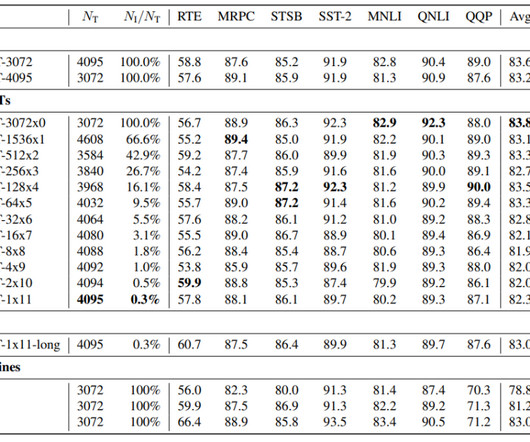
Mostly, largelanguagemodels' feedforward layers hold the most parameters. Studies show that these models use only a fraction of available neurons for output computation during inference. This article introduces UltraFastBERT, a BERT-based framework matching the efficacy of leading BERTmodels but using just 0.3%
LargeLanguageModels (LLMs) have revolutionized natural language processing, demonstrating remarkable capabilities in various applications. Recent advancements focus on scaling up these models and developing techniques for efficient fine-tuning, expanding their applicability across diverse domains.
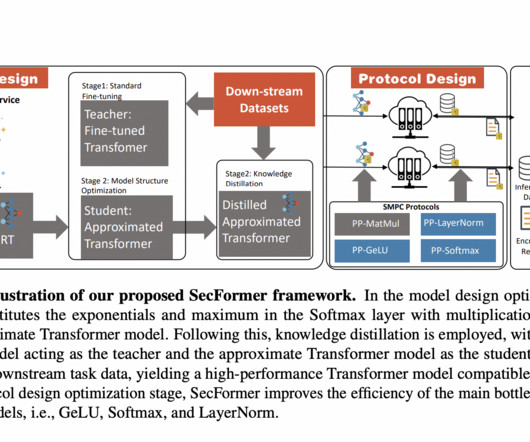
The increasing reliance on cloud-hosted largelanguagemodels for inference services has raised privacy concerns, especially when handling sensitive data. Secure Multi-Party Computing (SMPC) has emerged as a solution for preserving the privacy of both inference data and model parameters. Check out the Paper.
LargeLanguageModels have shown immense growth and advancements in recent times. The field of Artificial Intelligence is booming with every new release of these models. Famous LLMs like GPT, BERT, PaLM, and LLaMa are revolutionizing the AI industry by imitating humans.
The well-known LargeLanguageModels (LLMs) like GPT, BERT, PaLM, and LLaMA have brought in some great advancements in Natural Language Processing (NLP) and Natural Language Generation (NLG). If you like our work, you will love our newsletter.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. BERT is trained on sequences where some of the words in a sentence are masked, and it has to fill in those words taking into account both the words before and after the masked words.
The intermediate layers of largelanguagemodels (LLMs) contain surprisingly rich representations that often outperform the final layer on downstream tasks, according to new research from CDS Research Scientist Ravid Shwartz-Ziv , CDS Professor Yann LeCun , and their collaborators.
RAG is what is necessary for the LargeLanguageModels (LLMs) to provide or generate accurate and factual answers. Introduction Retrieval Augmented-Generation (RAG) has taken the world by Storm ever since its inception.
In this world of complex terminologies, someone who wants to explain LargeLanguageModels (LLMs) to some non-tech guy is a difficult task. So that’s why I tried in this article to explain LLM in simple or to say general language. A transformer architecture is typically implemented as a Largelanguagemodel.
These are deep learning models used in NLP. This discovery fueled the development of largelanguagemodels like ChatGPT. Largelanguagemodels or LLMs are AI systems that use transformers to understand and create human-like text. We choose a BERTmodel fine-tuned on the SQuAD dataset.
Computer programs called largelanguagemodels provide software with novel options for analyzing and creating text. It is not uncommon for largelanguagemodels to be trained using petabytes or more of text data, making them tens of terabytes in size.
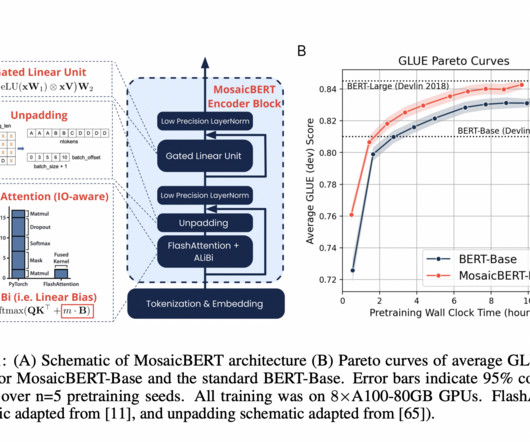
BERT is a languagemodel which was released by Google in 2018. It is based on the transformer architecture and is known for its significant improvement over previous state-of-the-art models. BERT-Base reached an average GLUE score of 83.2% hours taken by BERT-Large. hours compared to 23.35
Largelanguagemodels (LLMs) built on transformers, including ChatGPT and GPT-4, have demonstrated amazing natural language processing abilities. The creation of transformer-based NLP models has sparked advancements in designing and using transformer-based models in computer vision and other modalities.
Introduction Largelanguagemodels (LLMs) are increasingly becoming powerful tools for understanding and generating human language. LLMs have even shown promise in more specialized domains, like healthcare, finance, and law.
Nikolaus Kriegeskorte, a principal investigator at Columbia's Zuckerman Institute, emphasized the relative success of largelanguagemodels in capturing crucial aspects missed by simpler models.
At the same time, Llama and other largelanguagemodels have emerged and are revolutionizing NLP with their exceptional text understanding, generation, and generalization capabilities. This Paper Explores the Detective Skills of LargeLanguageModels in Information Extraction appeared first on MarkTechPost.
As the demand for largelanguagemodels (LLMs) continues to rise, ensuring fast, efficient, and scalable inference has become more crucial than ever. Let’s break down the key components: Model Definition TensorRT-LLM allows you to define LLMs using a simple Python API.
ChatGPT is part of a group of AI systems called LargeLanguageModels (LLMs) , which excel in various cognitive tasks involving natural language. LargeLanguageModels In recent years, LLM development has seen a significant increase in size, as measured by the number of parameters.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Techniques like Word2Vec and BERT create embedding models which can be reused.
Google has been a frontrunner in AI research, contributing significantly to the open-source community with transformative technologies like TensorFlow, BERT, T5, JAX, AlphaFold, and AlphaCode.
Transformers have transformed the field of NLP over the last few years, with LLMs like OpenAI’s GPT series, BERT, and Claude Series, etc. The introduction of the transformer architecture has provided a new paradigm for building models that understand and generate human language with unprecedented accuracy and fluency.
But more than MLOps is needed for a new type of ML model called LargeLanguageModels (LLMs). LLMs are deep neural networks that can generate natural language texts for various purposes, such as answering questions, summarizing documents, or writing code.
Most people who have experience working with largelanguagemodels such as Google’s Bard or OpenAI’s ChatGPT have worked with an LLM that is general, and not industry-specific. But as time has gone on, many industries have realized the power of these models. This is where BioBERT comes in. Get your pass today !
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content