
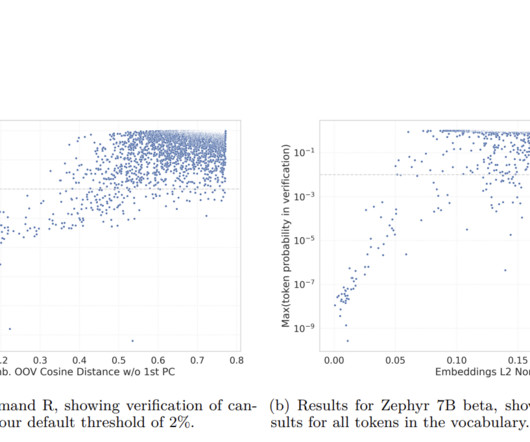
This AI Paper from Cohere Enhances Language Model Stability with Automated Detection of Under-trained Tokens in LLMs
Marktechpost
MAY 13, 2024
Tokenization is essential in computational linguistics, particularly in the training and functionality of large language models (LLMs). This process involves dissecting text into manageable pieces or tokens, which is foundational for model training and operations.












Let's personalize your content