This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Comprehensive Guide to BERT appeared first on Analytics Vidhya. It’s the beauty of Natural Language Processing’s Transformers. A Quick Recap of Transformers in NLP A transformer has rapidly become the dominant […].
This article was published as a part of the Data Science Blogathon Introduction In 2018, a powerful Transformer-based machine learning model, namely, BERT was developed by Jacob Devlin and his colleagues from Google for NLP applications. The post Text Classification using BERT and TensorFlow appeared first on Analytics Vidhya.
BERT (Bidirectional Encoder Representations from Transformers) is a very recent work published by Google AI Language researchers. The post An End-to-End Guide on Google’s BERT appeared first on Analytics Vidhya. Many state-of-the-art models are built on deep neural networks. It […].
The post Transfer Learning for NLP: Fine-Tuning BERT for Text Classification appeared first on Analytics Vidhya. Introduction With the advancement in deep learning, neural network architectures like recurrent neural networks (RNN and LSTM) and convolutional neural networks (CNN) have shown.
ArticleVideo Book This article was published as a part of the Data Science Blogathon BERT is too kind — so this article will be touching. The post Measuring Text Similarity Using BERT appeared first on Analytics Vidhya.
Introduction BERT is a really powerful language representation model that has been. The post Simple Text Multi Classification Task Using Keras BERT appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.
This article was published as a part of the Data Science Blogathon Introduction In the previous article, we have talked about BERT, Its Usage, And Understood some of its underlying Concepts. This article is intended to show how one can implement the learned concept to create a spam classifier using BERT.
A great example is the announcement that BERT models are now a significant force behind Google Search. Google believes that this move […] The post Building Language Models: A Step-by-Step BERT Implementation Guide appeared first on Analytics Vidhya.
In this article, we are going to use BERT along with a neural […]. The post Disaster Tweet Classification using BERT & Neural Network appeared first on Analytics Vidhya. From chatbot systems to movies recommendations to sentence completion, text classification finds its applications in one form or the other.
Introduction In this article, we will learn to train Bidirectional Encoder Representations from Transformers (BERT) in order to analyze the semantic equivalence of any two sentences, i.e. whether the two sentences convey the same meaning or not. The following aspects are covered in the […].
The post Manual for the First Time Users: Google BERT for Text Classification appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon Source: huggingface.io Hey Folks! […].
This article was published as a part of the Data Science Blogathon Objective In this blog, we will learn how to Fine-tune a Pre-trained BERT model for the Sentiment analysis task. The post Fine-tune BERT Model for Sentiment Analysis in Google Colab appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction In this article, you will learn about the input required for BERT in the classification or the question answering system development. Before diving directly into BERT let’s discuss the […].
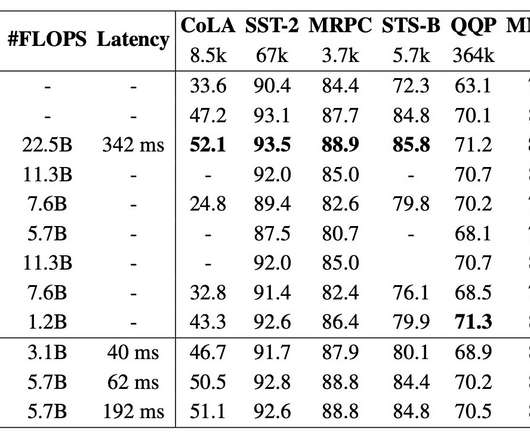
The post MobileBERT: BERT for Resource-Limited Devices appeared first on Analytics Vidhya. Overview As the size of the NLP model increases into the hundreds of billions of parameters, so does the importance of being able to.
This article explores the process of creating a FAQ chatbot specifically […] The post Build Custom FAQ Chatbot with BERT appeared first on Analytics Vidhya.
Overview Google’s BERT has transformed the Natural Language Processing (NLP) landscape Learn what BERT is, how it works, the seismic impact it has made, The post Demystifying BERT: A Comprehensive Guide to the Groundbreaking NLP Framework appeared first on Analytics Vidhya.
The post Why and how to use BERT for NLP Text Classification? ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction NLP or Natural Language Processing is an exponentially growing field. appeared first on Analytics Vidhya.
One crucial component that aids in this process is slot […] The post Enhancing Conversational AI with BERT: The Power of Slot Filling appeared first on Analytics Vidhya. However, achieving accurate and context-aware responses is a complex challenge.
The post Training BERT Text Classifier on Tensor Processing Unit (TPU) appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Training hugging face most famous model on TPU for social media.
In this article, we will delve into how Legal-BERT [5], a transformer-based model tailored for legal texts, can be fine-tuned to classify contract provisions using the LEDGAR dataset [4] — a comprehensive benchmark dataset specifically designed for the legal field. Fine-tuning Legal-BERT for multi-class classification of legal provisions.
The post Amazon Product review Sentiment Analysis using BERT appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Natural Language processing, a sub-field of machine learning has gained.
BERT greatly impacted how we study and work with human language. Creating BERT embeddings is especially good at grasping sentences with complex meanings. It does this by examining […] The post Creating BERT Embeddings with Hugging Face Transformers appeared first on Analytics Vidhya.
Introduction Adapting BERT for downstream tasks entails utilizing the pre-trained BERT model and customizing it for a particular task by adding a layer on top and training it on the target task.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction to BERT: BERT stands for Bidirectional Encoder Representations from Transformers. The post BERT for Natural Language Inference simplified in Pytorch! appeared first on Analytics Vidhya.
Introduction Google says that BERT is a major step forward, one of the biggest improvements in the history of Search. Visual BERT mastery is special because it can understand words in a sentence by looking at the words before and after them. It helps Google understand what people are looking for more accurately.
Some people might use social media to spread false information. […] The post Building a Multi-Task Model for Fake and Hate Probability Prediction with BERT appeared first on Analytics Vidhya. However, it also has its darker side and that is the widespread of fake and hate content.
ArticleVideos Introduction Note from the author: In this article, we will learn how to create your own Question and Answering(QA) API using python, flask, The post How to create your own Question and Answering API(Flask+Docker +BERT) using haystack framework appeared first on Analytics Vidhya.
By pre-training on a large corpus of text with a masked language model and next-sentence prediction, BERT captures rich bidirectional contexts and has achieved state-of-the-art results on a wide array of NLP tasks. GPT Architecture Here's a more in-depth comparison of the T5, BERT, and GPT models across various dimensions: 1.
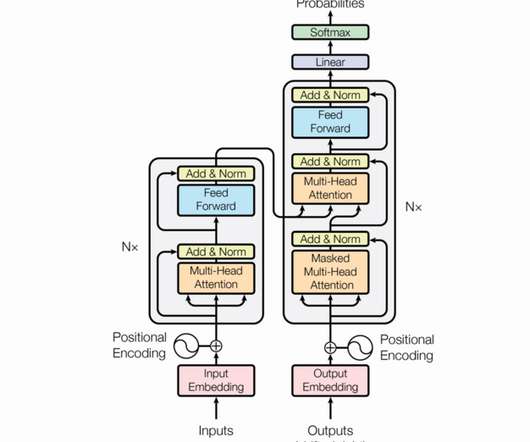
This article explores […] The post Exploring the Use of LLMs and BERT for Language Tasks appeared first on Analytics Vidhya. Since the groundbreaking ‘Attention is all you need’ paper in 2017, the Transformer architecture, notably exemplified by ChatGPT, has become pivotal.
This method highlights the underlying structure of a body of text, bringing to light themes and patterns that might […] The post Unveiling the Future of Text Analysis: Trendy Topic Modeling with BERT appeared first on Analytics Vidhya.
The post Fine-tune BERT Model for Named Entity Recognition in Google Colab appeared first on Analytics Vidhya. It is used to detect the entities in text for further use in the downstream tasks as some text/words are more informative and essential for a given context than others. […].
Since its introduction in 2018, BERT has transformed Natural Language Processing. Using bidirectional training and transformer-based self-attention, BERT introduced a new way to understand relationships between words in text. However, despite its success, BERT has limitations.
Large Language Models like BERT, T5, BART, and DistilBERT are powerful tools in natural language processing where each is designed with unique strengths for specific tasks. Whether it’s summarization, question answering, or other NLP applications. These models vary in their architecture, performance, and efficiency.
Source: Canva|Arxiv Introduction In 2018 GoogleAI researchers developed Bidirectional Encoder Representations from Transformers (BERT) for various NLP tasks. However, one of the key limitations of this technique was the quadratic dependency, due to which the BERT-like model can handle sequences of 512 tokens […].
Source: Canva Introduction In 2018, GoogleAI researchers released the BERT model. However, the BERT model did have some drawbacks i.e. it was bulky and hence a little slow. This article was published as a part of the Data Science Blogathon. It was a fantastic work that brought a revolution in the NLP domain. To navigate […].
Current text embedding models, like BERT, are limited to processing only 512 tokens at a time, which hinders their effectiveness with long documents. This limitation often results in loss of context and nuanced understanding.
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT. The key […].
ModernBERT is an advanced iteration of the original BERT model, meticulously crafted to elevate performance and efficiency in natural language processing (NLP) tasks.
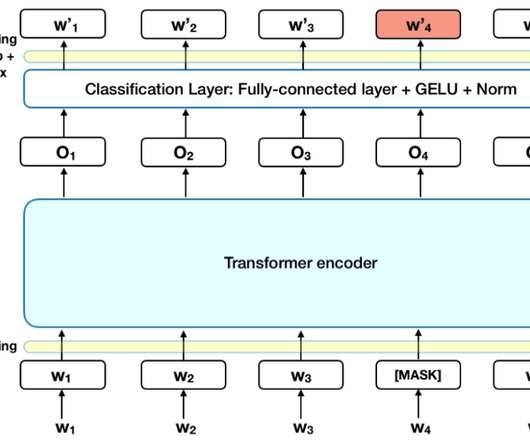
Introduction BERT, short for Bidirectional Encoder Representations from Transformers, is a system leveraging the transformer model and unsupervised pre-training for natural language processing. Being pre-trained, BERT learns beforehand through two unsupervised tasks: masked language modeling and sentence prediction.
This article was published as a part of the Data Science Blogathon Introduction In the last article, we have discussed implementing the BERT model using the TensorFlow hub; you can read it here. Implementing BERT using the TensorFlow hub was tedious since we had to perform every step from scratch.
Introduction With the advent of Large Language Models (LLMs), they have permeated numerous applications, supplanting smaller transformer models like BERT or Rule Based Models in many Natural Language Processing (NLP) tasks.
Unlike previous models like BERT, which use masked language modeling (MLM), where certain words are masked and predicted based on context, XLNet employs permutation language modeling (PLM). This means […] The post Understanding the XLNet Pre-trained Model appeared first on Analytics Vidhya.
That’s a bit like what BERT does — except instead of people, it reads text. BERT, short for Bidirectional Encoder Representations from Transformers, is a powerful machine learning model developed by Google. Let’s jump in and set up our sentiment analysis tool using BERT!
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content