This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
Avi Perez, CTO of Pyramid Analytics, explained that his business intelligence software’s AI infrastructure was deliberately built to keep data away from the LLM , sharing only metadata that describes the problem and interfacing with the LLM as the best way for locally-hosted engines to run analysis.”There’s
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications.
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
The platform automatically analyzes metadata to locate and label structured data without moving or altering it, adding semantic meaning and aligning definitions to ensure clarity and transparency. When onboarding customers, we automatically retrain these ontologies on their metadata. Even defining it back then was a tough task.
Similar to how a customer service team maintains a bank of carefully crafted answers to frequently asked questions (FAQs), our solution first checks if a users question matches curated and verified responses before letting the LLM generate a new answer. No LLM invocation needed, response in less than 1 second.
One of LLMs most fascinating strengths is their inherent ability to understand context. Localization relies on both automation and humans-in-the-loop in a process called Machine Translation Post Editing (MTPE). However, the industry is seeing enough potential to consider LLMs as a valuable option.
The company also launched an AI Developer, a Qwen-powered AI assistant designed to support programmers in automating tasks such as requirement analysis, code programming, and bug identification and fixing. DMS: OneMeta+OneOps, a platform for unified management of metadata across multiple cloud environments.
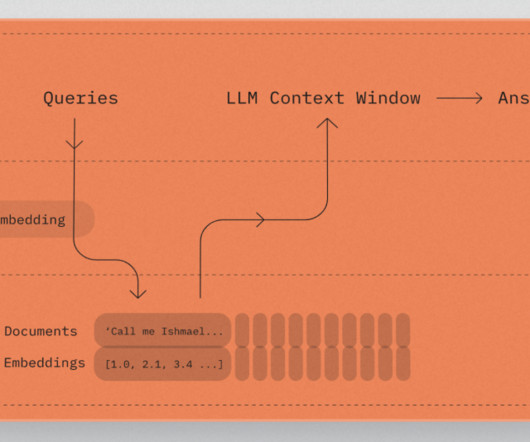
With metadata filtering now available in Knowledge Bases for Amazon Bedrock, you can define and use metadata fields to filter the source data used for retrieving relevant context during RAG. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected best practices. Metadata filtering is used to improve retrieval accuracy.
It not only collects data from websites but also processes and cleans it into LLM-friendly formats like JSON, cleaned HTML, and Markdown. These customizations make the tool adaptable for various data types and web structures, allowing users to gather text, images, metadata, and more in a structured way that benefits LLM training.
This transcription then serves as the input for a powerful LLM, which draws upon its vast knowledge base to provide personalized, context-aware responses tailored to your specific situation. LLM integration The preprocessed text is fed into a powerful LLM tailored for the healthcare and life sciences (HCLS) domain.
In this paper researchers introduced a new framework, ReasonFlux that addresses these limitations by reimagining how LLMs plan and execute reasoning steps using hierarchical, template-guided strategies. Recent approaches to enhance LLM reasoning fall into two categories: deliberate search and reward-guided methods. Check out the Paper.
RAFT vs Fine-Tuning Image created by author As the use of large language models (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Solution: Build a validation pipeline with domain experts and automate checks for the dataset (e.g.,
With the launch of the Automated Reasoning checks in Amazon Bedrock Guardrails (preview), AWS becomes the first and only major cloud provider to integrate automated reasoning in our generative AI offerings. Click on the image below to see a demo of Automated Reasoning checks in Amazon Bedrock Guardrails.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
With this LLM, CreditAI was now able to respond better to broader, industry-wide queries than before. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Each processed document maintains references to its source file, extraction timestamp, and processing metadata.
When we launched LLM-as-a-judge (LLMaJ) and Retrieval Augmented Generation (RAG) evaluation capabilities in public preview at AWS re:Invent 2024 , customers used them to assess their foundation models (FMs) and generative AI applications, but asked for more flexibility beyond Amazon Bedrock models and knowledge bases. Fields marked with ?
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the large language model (LLM) powering ChatGPT, have been trained on information culled from the internet. But how trustworthy is that training data?
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. Sonnet on Amazon Bedrock as our LLM to generate SQL queries for user inputs. This retrieved data is used as context, combined with the original prompt, to create an expanded prompt that is passed to the LLM.
When the automated content processing steps are complete, you can use the output for downstream tasks, such as to invoke different components in a customer service backend application, or to insert the generated tags into metadata of each document for product recommendation. The LLM generates output based on the user prompt.
In synchronous orchestration, just like in traditional process automation, a supervisor agent orchestrates the multi-agent collaboration, maintaining a high-level view of the entire process while actively directing the flow of information and tasks.
In the face of these challenges, MLOps offers an important path to shorten your time to production while increasing confidence in the quality of deployed workloads by automating governance processes. This post illustrates how to use common architecture principles to transition from a manual monitoring process to one that is automated.
Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Each collection includes documents, which are just lists of strings, IDs, which serve as unique identifiers for the documents, and metadata (which is not required).
Why Kubernetes for LLM Deployment? Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. Container Registry : You'll need a container registry to store your LLM Docker images.
In industries like insurance, where unpredictable scenarios are the norm, traditional automation falls short, leading to inefficiencies and missed opportunities. This is a smaller version of task automation to fulfill a particular business problem achieved by chaining agents, each performing a set of specific tasks.
The automation provided by Rad AI Impressions not only reduces burnout, but also safeguards against errors arising from manual repetition. First, it enhances researcher productivity by providing the necessary processes and automation, positioning them to deliver high-quality models with regularity. No one writes any code manually.
You can use metadata filtering to narrow down search results by specifying inclusion and exclusion criteria. For a demonstration on how you can use a RAG evaluation framework in Amazon Bedrock to compute RAG quality metrics, refer to New RAG evaluation and LLM-as-a-judge capabilities in Amazon Bedrock.
AI notetakers that can now generate highly accurate and hallucination-free meeting notes to serve as the basis for LLM-powered summaries, action items, and other metadata generation with accurate proper noun, speaker, and timing information included.
“ Gen AI has elevated the importance of unstructured data, namely documents, for RAG as well as LLM fine-tuning and traditional analytics for machine learning, business intelligence and data engineering,” says Edward Calvesbert, Vice President of Product Management at IBM watsonx and one of IBM’s resident data experts.
AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security.
Those tools and practices not only help to integrate consecutive steps (see Figure 1) together and make them work smoothly; they also make sure that the whole process is reproducible, automated and properly monitored at each stage – model training as well as model inference. Why are these elements so important?
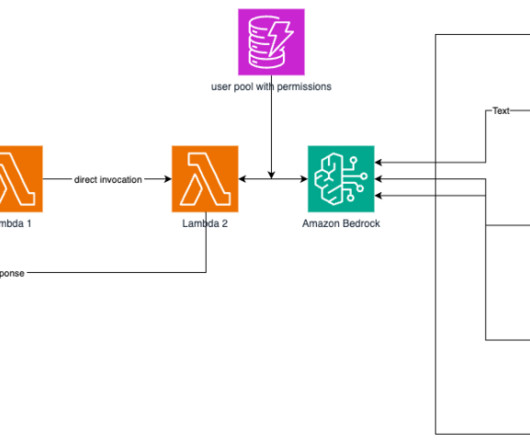
Sonnet LLM, Stability AIs Stable Diffusion 3 image generation, and knowledge base connectors AWS Lambda For workflow execution Amazon API Gateway For the Slack event handler Amazon Simple Storage Service (Amazon S3) For arbitrary unstructured data Amazon DynamoDB For persistent storage The following diagram illustrates the solution architecture.
Technologies and Tools Used To build this Resume Chatbot, I leveraged the following technologies and libraries: OpenAI API: Used to power the chatbot with a state-of-the-art LLM. LangChain: This framework was instrumental in interacting with the LLM and integrating various tools to enhance the chatbots functionality.
llm = OpenAI(temperature=0)conversation_with_summary = ConversationChain(llm=llm,memory=ConversationSummaryMemory(llm=OpenAI()),verbose=True)conversation_with_summary.predict(input="Hi, what's up?") So, how does the LLM understand that this is the company’s phone number?
To scale ground truth generation and curation, you can apply a risk-based approach in conjunction with a prompt-based strategy using LLMs. Its important to note that LLM-generated ground truth isnt a substitute for use case SME involvement. To convert the source document excerpt into ground truth, we provide a base LLM prompt template.
For an example of such a feedback loop implemented in AWS, refer to Improve LLM performance with human and AI feedback on Amazon SageMaker for Amazon Engineering. Implement metadata filtering , adding contextual layers to chunk retrieval. For example, prioritizing recent information in time-sensitive scenarios.
The system builds upon the robust FactualVQA dataset, specifically constructed to provide unambiguous answers that can be reliably evaluated with automated methods. This image search capability combines SerpApi, JINA Reader for content extraction, and LLM-based summarization to retrieve and process relevant web content associated with images.
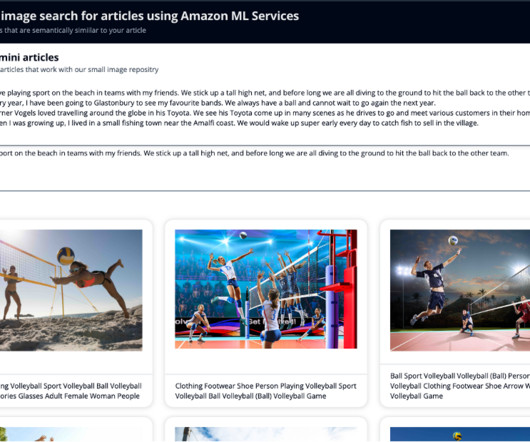
Digital publishers are continuously looking for ways to streamline and automate their media workflows in order to generate and publish new content as rapidly as they can. Finding the image that best matches an article in repositories of this scale can be a time-consuming, repetitive, manual task that can be automated.
link] The paper investigates LLM robustness to prompt perturbations, measuring how much task performance drops for different models with different attacks. link] The paper proposes query rewriting as the solution to the problem of LLMs being overly affected by irrelevant information in the prompts. ArXiv 2023. Oliveira, Lei Li.
Amazon Personalize has helped us achieve high levels of automation in content customization. They can also introduce context and memory into LLMs by connecting and chaining LLM prompts to solve for varying use cases. Getting recommendations along with metadata makes it more convenient to provide additional context to LLMs.
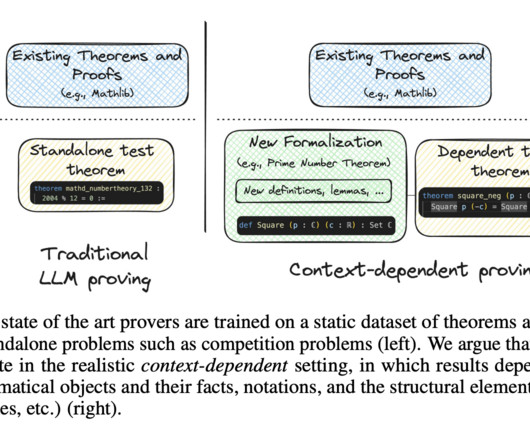
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of large language models (LLMs), with significant implications for mathematical automation. The disconnect between laboratory performance and practical applications raises concerns about the true effectiveness of LLM-based provers.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






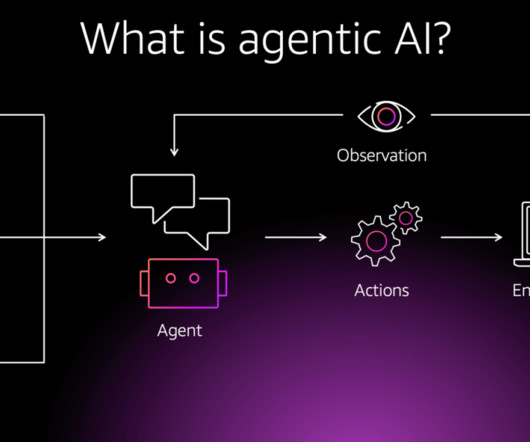





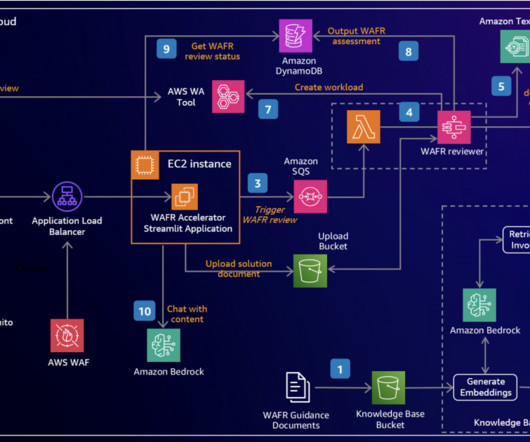



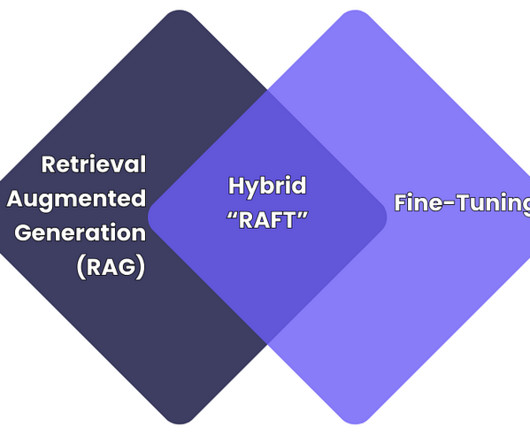





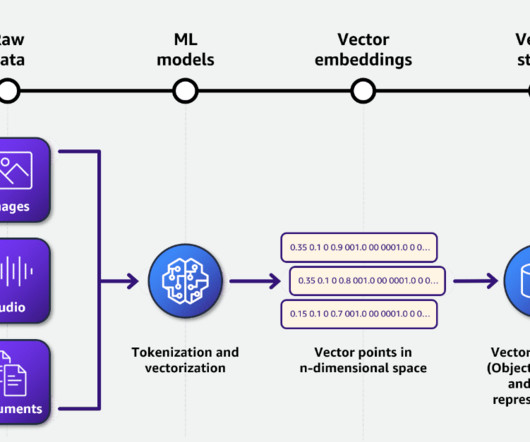






















Let's personalize your content