This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Metadata can play a very important role in using data assets to make data driven decisions. Generating metadata for your data assets is often a time-consuming and manual task. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.
With a growing library of long-form video content, DPG Media recognizes the importance of efficiently managing and enhancing video metadata such as actor information, genre, summary of episodes, the mood of the video, and more. Video data analysis with AI wasn’t required for generating detailed, accurate, and high-quality metadata.
What role does metadata authentication play in ensuring the trustworthiness of AI outputs? Metadata authentication helps increase our confidence that assurances about an AI model or other mechanism are reliable. How can organizations mitigate the risk of AI bias and hallucinations in largelanguagemodels (LLMs)?
One of these strategies is using Amazon Simple Storage Service (Amazon S3) folder structures and Amazon Bedrock Knowledge Bases metadata filtering to enable efficient data segmentation within a single knowledge base. The S3 bucket, containing customer data and metadata, is configured as a knowledge base data source.
Largelanguagemodels (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata.
Today, were excited to announce the general availability of Amazon Bedrock Data Automation , a powerful, fully managed feature within Amazon Bedrock that automate the generation of useful insights from unstructured multimodal content such as documents, images, audio, and video for your AI-powered applications.
You can trigger the processing of these invoices using the AWS CLI or automate the process with an Amazon EventBridge rule or AWS Lambda trigger. structured: | Process the pdf invoice and list all metadata and values in json format for the variables with descriptions in tags. The result should be returned as JSON as given in the tags.
Now, Syngenta is advancing further by using largelanguagemodels (LLMs) and Amazon Bedrock Agents to implement Cropwise AI on AWS, marking a new era in agricultural technology. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
LargeLanguageModels (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation. LargeLanguageModels (LLMs) are a type of neural network model trained on vast amounts of text data.
These models can also rank potential sites by identifying the best combination of site attributes and factors that align with study objectives and recruitment strategies. Healthtech companies adopting AI are also developing tools that help physicians to quickly and accurately determine eligible trials for patients.
Knowledge bases allow Amazon Bedrock users to unlock the full potential of Retrieval Augmented Generation (RAG) by seamlessly integrating their company data into the languagemodel’s generation process. Metadata filtering gives you more control over the RAG process for better results tailored to your specific use case needs.
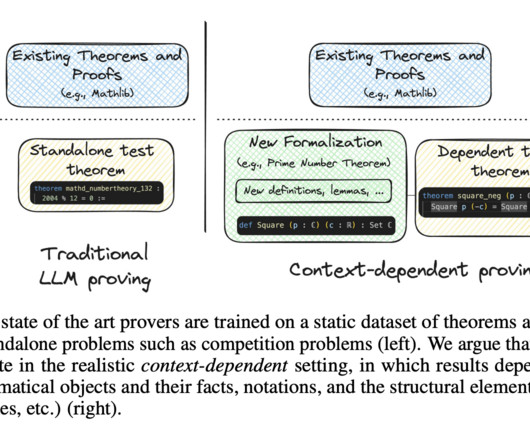
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. These findings underscore the need for more sophisticated approaches to context handling in automated theorem proving.
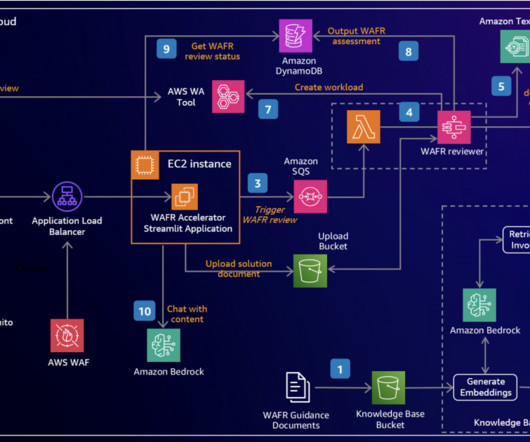
This solution automates portions of the WAFR report creation, helping solutions architects improve the efficiency and thoroughness of architectural assessments while supporting their decision-making process. Metadata filtering is used to improve retrieval accuracy.
Furthermore, Alibaba Cloud introduced Qwen2-VL, an updated vision languagemodel capable of comprehending videos lasting over 20 minutes and supporting video-based question-answering. DMS: OneMeta+OneOps, a platform for unified management of metadata across multiple cloud environments.
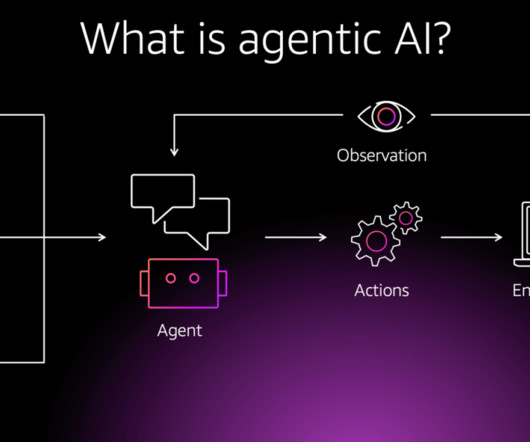
Agentic design An AI agent is an autonomous, intelligent system that uses largelanguagemodels (LLMs) and other AI capabilities to perform complex tasks with minimal human oversight. CrewAIs agents are not only automating routine tasks, but also creating new roles that require advanced skills.
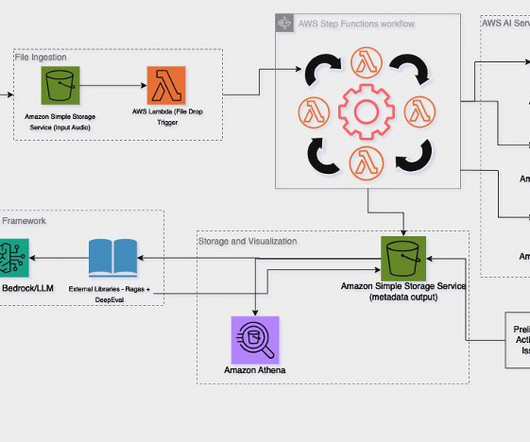
Failing to adopt a more automated approach could have potentially led to decreased customer satisfaction scores and, consequently, a loss in future revenue. The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution. and Anthropics Claude Haiku 3.
Largelanguagemodels (LLMs) have exploded in popularity over the last few years, revolutionizing natural language processing and AI. What are LargeLanguageModels and Why are They Important? Hybrid retrieval combines dense embeddings and sparse keyword metadata for improved recall.
To start simply, you could think of LLMOps ( LargeLanguageModel Operations) as a way to make machine learning work better in the real world over a long period of time. As previously mentioned: model training is only part of what machine learning teams deal with. What is LLMOps? Why are these elements so important?
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
In addition to these capabilities, generative AI can revolutionize drive tests, optimize network resource allocation, automate fault detection, optimize truck rolls and enhance customer experience through personalized services. Operators and suppliers are already identifying and capitalizing on these opportunities.
To bridge this gap, Amazon Bedrock now introduces application inference profiles , a new capability that allows organizations to apply custom cost allocation tags to track, manage, and control their Amazon Bedrock on-demand model costs and usage.
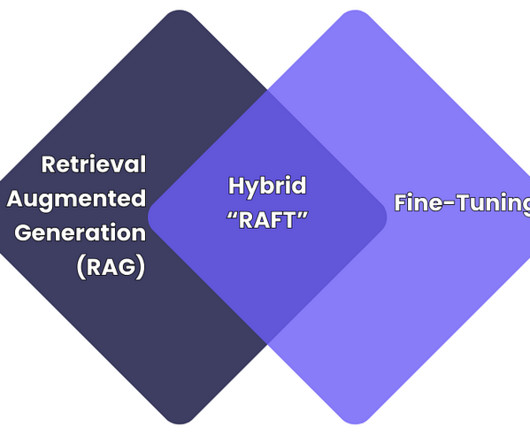
RAFT vs Fine-Tuning Image created by author As the use of largelanguagemodels (LLMs) grows within businesses, to automate tasks, analyse data, and engage with customers; adapting these models to specific needs (e.g., Version Control Problem: Managing model iterations is prone to error.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Most of today’s largest foundation models, including the largelanguagemodel (LLM) powering ChatGPT, have been trained on information culled from the internet.
Reports holistically summarize each evaluation in a human-readable way, through natural-language explanations, visualizations, and examples, focusing annotators and data scientists on where to optimize their LLMs and help make informed decisions. What is FMEval?
The advent of Multimodal LargeLanguageModels (MLLM) has ushered in a new era of mobile device agents, capable of understanding and interacting with the world through text, images, and voice. Along with GPT-4V, Mobile-Agent also employs an icon detection module for icon localization.
SQL is one of the key languages widely used across businesses, and it requires an understanding of databases and table metadata. This application allows users to ask questions in natural language and then generates a SQL query for the users request. This can be overwhelming for nontechnical users who lack proficiency in SQL.
Languagemodels are statistical methods predicting the succession of tokens in sequences, using natural text. Largelanguagemodels (LLMs) are neural network-based languagemodels with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical.
Since 2018, using state-of-the-art proprietary and open source largelanguagemodels (LLMs), our flagship product— Rad AI Impressions — has significantly reduced the time radiologists spend dictating reports, by generating Impression sections. Rad AI’s ML organization tackles this challenge on two fronts.
In the face of these challenges, MLOps offers an important path to shorten your time to production while increasing confidence in the quality of deployed workloads by automating governance processes. ML models in production are not static artifacts. These frequent manual checks can create long lead times to deliver value to customers.
AI agents , powered by largelanguagemodels (LLMs), can analyze complex customer inquiries, access multiple data sources, and deliver relevant, detailed responses. The embeddings, along with metadata about the source documents, are indexed for quick retrieval. He holds a Master’s in Information Systems.
It was built using a combination of in-house and external cloud services on Microsoft Azure for largelanguagemodels (LLMs), Pinecone for vectorized databases, and Amazon Elastic Compute Cloud (Amazon EC2) for embeddings. Opportunities for innovation CreditAI by Octus version 1.x x uses Retrieval Augmented Generation (RAG).
The performance and quality of the models also improved drastically with the number of parameters. These models span tasks like text-to-text, text-to-image, text-to-embedding, and more. You can use largelanguagemodels (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering.
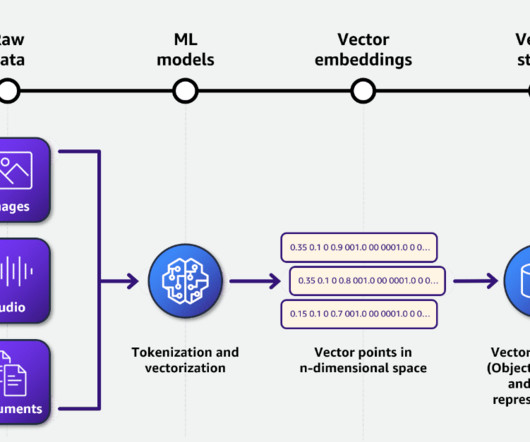
Crawl4AI, an open-source tool, is designed to address the challenge of collecting and curating high-quality, relevant data for training largelanguagemodels. Once the data is fetched, Crawl4AI applies advanced data extraction techniques using XPath and regular expressions to extract relevant text, images, and metadata.
AI agents continue to gain momentum, as businesses use the power of generative AI to reinvent customer experiences and automate complex workflows. Agents use the reasoning capability of foundation models (FMs) to break down user-requested tasks into multiple steps. Lets look at how the interface adapts to different user roles.
Largelanguagemodels (LLMs) have transformed the way we engage with and process natural language. These powerful models can understand, generate, and analyze text, unlocking a wide range of possibilities across various domains and industries. This provides an automated deployment experience on your AWS account.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. ” Romain Gaborit, CTO, Eviden, an ATOS business “We’re looking at the potential usage of LargeLanguageModels. .”
Return item metadata in inference responses – The new recipes enable item metadata by default without extra charge, allowing you to return metadata such as genres, descriptions, and availability in inference responses. If you use Amazon Personalize with generative AI, you can also feed the metadata into prompts.
Enhanced Customer Experience through Automation and Personalization**: - **Automated Customer Support**: LLMs can power chatbots and virtual assistants that provide 24/7 customer support. Repository Information**: Not shown in the provided excerpt, but likely contains metadata about the repository.
The award, totaling $299,208 for one year, will be used for research and development of LLMs for automated named entity recognition (NER), relation extraction, and ontology metadata enrichment from free-text clinical notes.
Largelanguagemodels (LLMs) have demonstrated exceptional problem-solving abilities, yet complex reasoning taskssuch as competition-level mathematics or intricate code generationremain challenging. Template Trajectory Optimization : Using preference learning, the model learns to rank template sequences by their effectiveness.
In industries like insurance, where unpredictable scenarios are the norm, traditional automation falls short, leading to inefficiencies and missed opportunities. This is a smaller version of task automation to fulfill a particular business problem achieved by chaining agents, each performing a set of specific tasks.
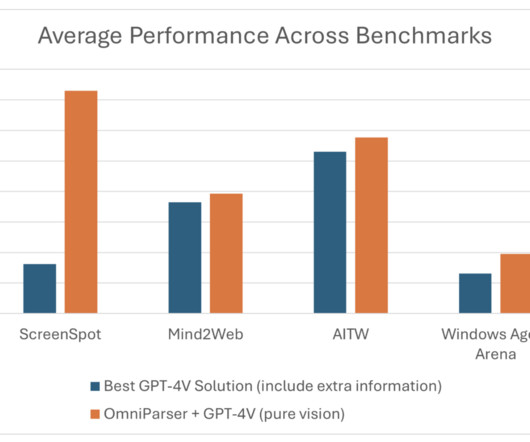
However, automated interaction with these GUIs presents a significant challenge. Traditional methods rely on parsing underlying HTML or view hierarchies, which limits their applicability to web-based environments or those with accessible metadata. Check out the Paper , Details , and Try the model here.
Most organizations today want to utilize largelanguagemodels (LLMs) and implement proof of concepts and artificial intelligence (AI) agents to optimize costs within their business processes and deliver new and creative user experiences. One noteworthy application of LLM-MA systems is call/service center automation.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in largelanguagemodels (LLMs) and natural language processing (NLP). This post will discuss agentic AI driven architecture and ways of implementing.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content