This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Together AI , a prominent player in the AI Acceleration Cloud space, is also looking to integrate its proprietary Together InferenceEngine with NVIDIA Dynamo. This integration aims to enable seamless scaling of inference workloads across multiple GPU nodes.
This ability is supported by advanced technical components like inferenceengines and knowledge graphs, which enhance its reasoning skills. It can automate social media posts, generate responses, and even create engaging content like memes and short-form blogs. For content creators, Grok-3 is an invaluable tool.
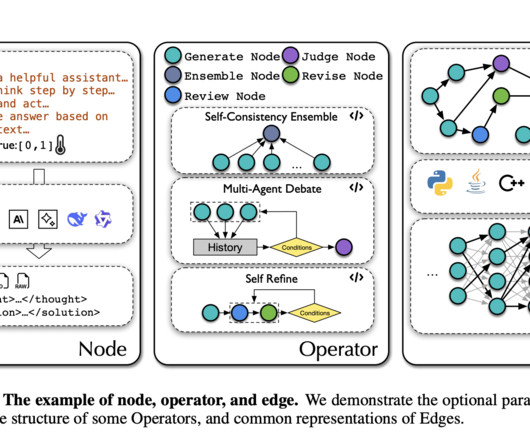
Efforts to automate workflow generation have not yet fully eliminated the need for human intervention, making broad generalization and effective skill transfer for LLMs difficult to achieve. enhancement over existing automated systems like ADAS. Specifically, AFlow achieves an average performance improvement of 5.7%
Automated optical inspection, or AOI, helps manufacturers more quickly identify defects and deliver high-quality products to their customers around the globe. The below demo shows how Techman uses Isaac Sim to optimize the inspection of robots by robots on the manufacturing line. In effect, it’s robots building robots.
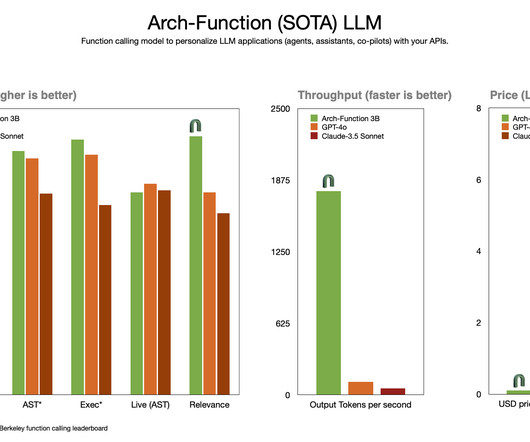
Issues of speed, flexibility, and scalability often hinder the automation of complex workflows requiring coordination across multiple systems. Arch-Function empowers industries like finance and healthcare to build intelligent agents that automate complex workflows, transforming operations into streamlined processes.
TCenter of Juris-Informatics, ROIS-DS, Tokyo, Japanhis method delivers a better organized and explicable information retrieval process by automating the procedures necessary to make the retrieval process more efficient. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
In recent years, AI-driven workflows and automation have advanced remarkably. Bee Agent Framework aims to address the complexities associated with large-scale, agent-driven automation by providing a streamlined yet robust toolkit. Yet, building complex, scalable, and efficient agentic workflows remains a significant challenge.
AI, particularly through ML and DL, has advanced medical applications by automating complex tasks. These systems rely on a domain knowledge base and an inferenceengine to solve specialized medical problems. ML algorithms learn from data to improve over time, while DL uses neural networks to handle large, complex datasets.
The challenge lies in automating computer tasks by replicating human-like interaction, which involves understanding varied user interfaces, adapting to new applications, and managing complex sequences of actions similar to how a human would perform them. If you like our work, you will love our newsletter.
NVIDIA NIM microservices, part of the NVIDIA AI Enterprise software platform, together with Google Kubernetes Engine (GKE) provide a streamlined path for developing AI-powered apps and deploying optimized AI models into production.
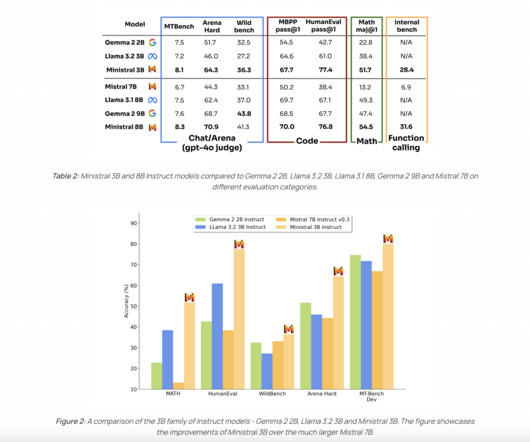
These models, collectively known as les Ministraux, are engineered to bring powerful language modeling capabilities directly to devices, eliminating the need for cloud computing resources. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
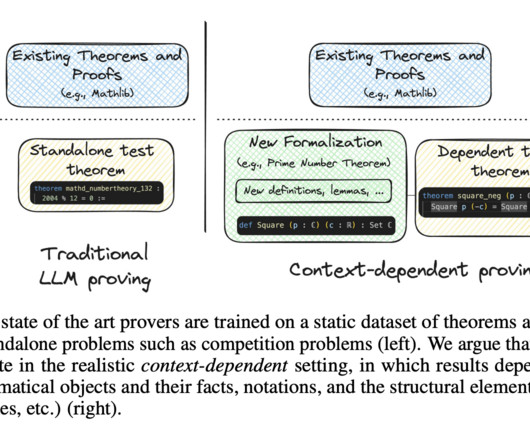
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of large language models (LLMs), with significant implications for mathematical automation. These findings underscore the need for more sophisticated approaches to context handling in automated theorem proving.
Language Processing Units (LPUs): The Language Processing Unit (LPU) is a custom inferenceengine developed by Groq, specifically optimized for large language models (LLMs). However, due to their specialized design, NPUs may encounter compatibility issues when integrating with different platforms or software environments.
Advancements in this area are vital for applications such as automated customer service, content creation, and machine translation, where language precision and sustained coherence are critical. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
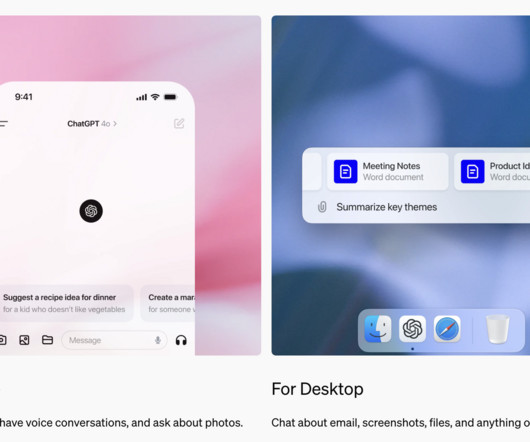
The app is designed with a simple interface that focuses on usability and minimizes distractions, providing an efficient way to get AI-generated answers, support, and automation. Users can now benefit from a faster and smoother interaction without needing to switch between multiple tabs or deal with web performance limitations.
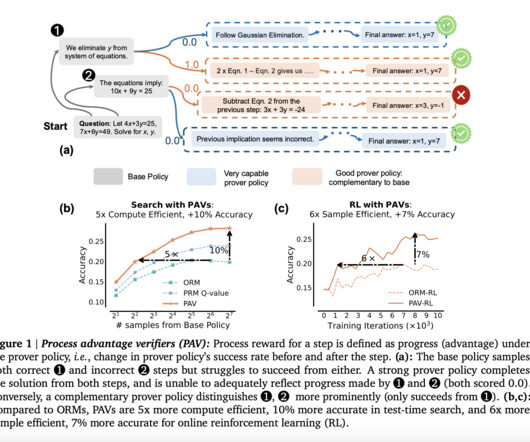
However, PRMs that rely on human-generated labels are not scalable, and even automated PRMs have shown only limited success, with small gains in performance—often just 1-2% over ORMs. Some recent efforts have introduced Process Reward Models (PRMs), which give feedback at each intermediate step. Don’t Forget to join our 50k+ ML SubReddit.
By combining these features, AutoDAN-Turbo represents a significant advancement in the field of automated jailbreak attacks against large language models. Third, the method operates in a black-box manner, requiring only access to the model’s textual output, making it practical for real-world applications.
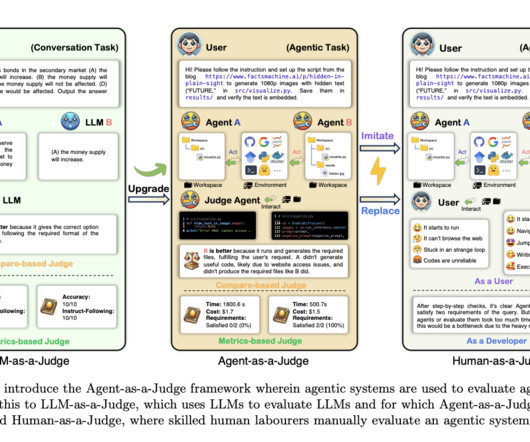
Benchmarks like SWE-Bench, for example, focus on the success rate of final solutions in long-term automated tasks but offer little insight into the performance of intermediate steps. Existing methods for evaluating agentic systems rely heavily on either human judgment or benchmarks that assess only the final task outcomes.
Code generation AI models (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. However, their ability to autonomously generate code raises concerns about security vulnerabilities. If you like our work, you will love our newsletter.
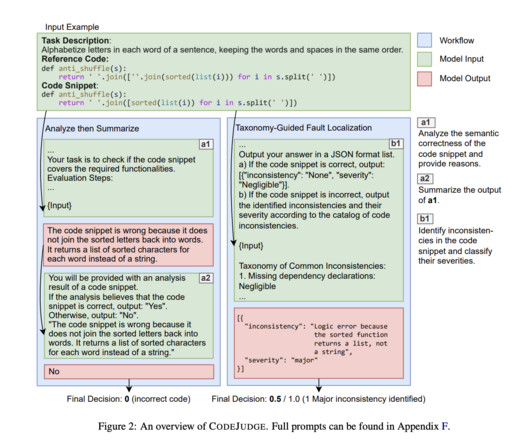
A team of researchers from Huazhong University of Science and Technology and Purdue University introduced CodeJudge has made the solution even better by allowing an automated and multilayered structure, which will allow the programming problems to be scrutinized even more deeply. If you like our work, you will love our newsletter.
The support of NVIDIA Inception is helping us advance our work to automate conversational AI use cases with domain-specific large language models,” said Ankush Sabharwal, CEO of CoRover. Conversational AI for Indian Railway Customers Bengaluru-based startup CoRover.ai billion users in over 100 languages.”
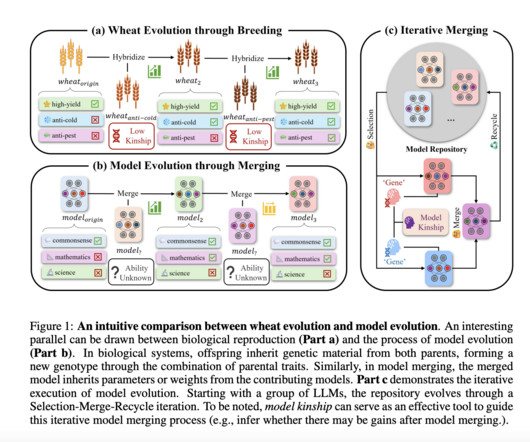
Recent work has focused on “model evolution,” with approaches like CoLD Fusion for iterative fusion, automated merging tools on platforms like Hugging Face, and Evolutionary Model Merge employing evolutionary techniques to optimize model combinations. If you like our work, you will love our newsletter.
Using the Ragas library, we evaluated their question-answering quality by combining human assessment with automated LLM-based metrics. We gauged the impact of different quantization levels and prompt engineering on response quality. Methods and Tools Let’s start with the inferenceengine for the Small Language Model.
They have the potential to revolutionize how we work and automate tasks across many industries. It uses formal languages, like first-order logic, to represent knowledge and an inferenceengine to draw logical conclusions based on user queries. LAMs represent a significant leap beyond text generation and understanding.
TPS typically includes features such as : Data Entry: Capturing transaction data through user interfaces or automated systems. Automation: Streamlining processes and reducing manual effort through automated workflows. Data Processing: Performing calculations, updates, and validations on the entered data.
Proprietary Cloud Platform : The CLUSTER ENGINE is a proprietary cloud management system that optimizes resource scheduling, providing a flexible and efficient cluster management solution Add inferenceengine roadmap : Continuous computing, guarantee high SLA. Time share for fractional time use.
Offline inference with vLLM Another way to use vLLM on Inferentia is by sending a few requests all at the same time in a script. This is useful for automation or when you have a batch of prompts that you want to send all at the same time. sampling_params = SamplingParams(temperature=0.8, top_p=0.95) # Create an LLM.
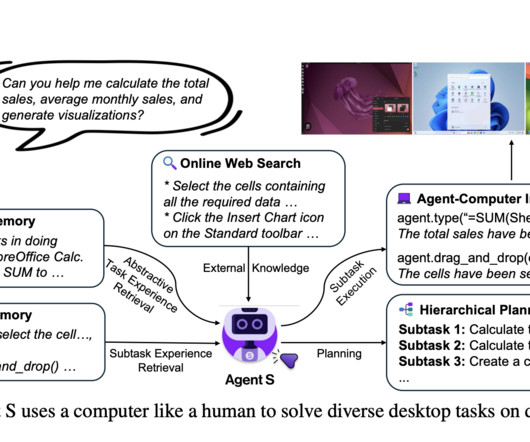
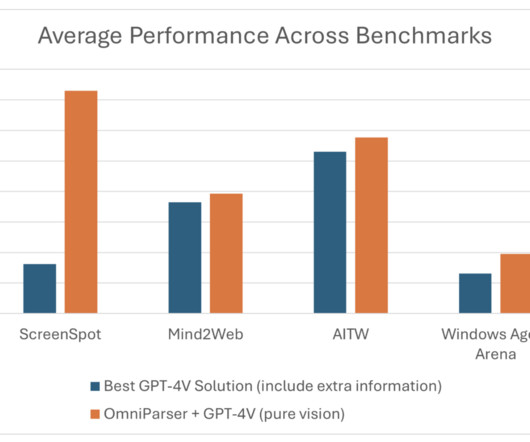
However, automated interaction with these GUIs presents a significant challenge. This model, available here on Hugging Face , represents an exciting development in intelligent GUI automation. This gap becomes particularly evident in building intelligent agents that can comprehend and execute tasks based on visual information alone.
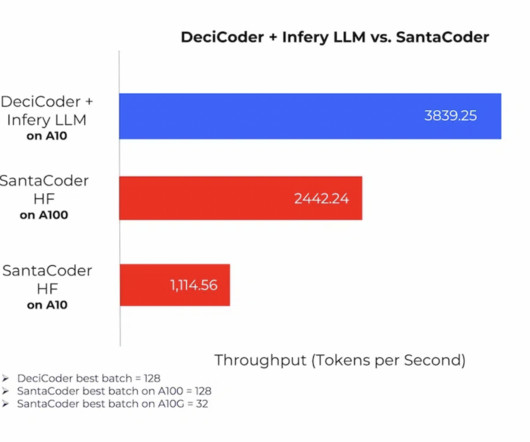
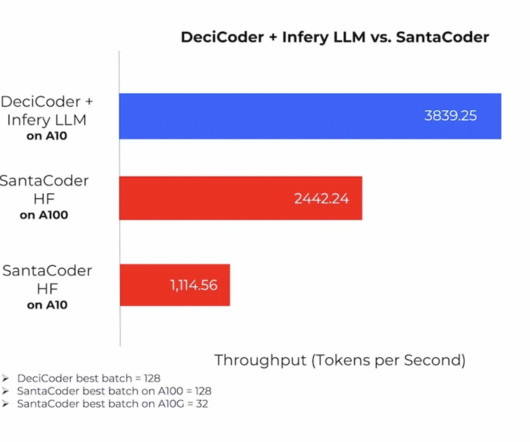
Unlike manual, labor-intensive approaches that often fall short, AutoNAC automates the process of generating optimal architectures. By leveraging DeciCoder alongside Infery LLM, a dedicated inferenceengine, users unlock the power of significantly higher throughput – a staggering 3.5 times greater than SantaCoder’s.
Unlike manual, labor-intensive approaches that often fall short, AutoNAC automates the process of generating optimal architectures. By leveraging DeciCoder alongside Infery LLM, a dedicated inferenceengine, users unlock the power of significantly higher throughput – a staggering 3.5 times greater than SantaCoder’s.
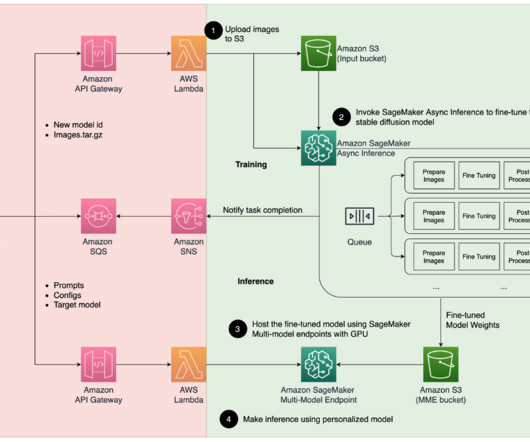
We have also added automated preprocessing to extract your face from each photo. amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117" file that loads the model into the inferenceengine and prepares the data input and output from the model. deepspeed0.8.3-cu117" Lastly, we must have a model.py
We’re delighted to announce the winners of the Essay competition on the Automation of Wisdom and Philosophy. I also liked that it identified a task (building datasets) that could plausibly lead to quality improvements in automated philosophy and which is a task that philosophers are already in a position to help with.
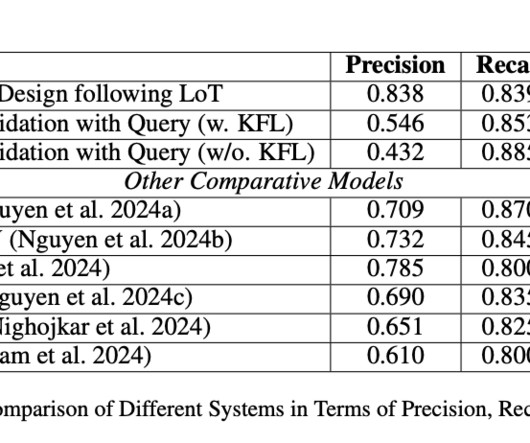
Most methods rely on spotting them by analyzing misclassified samples in a semi-automated human computer validation. Current methods for identifying biases often rely on analyzing misclassified samples through semi-automated human-computer validation. Datasets and pre-trained models come with intrinsic biases.
This method has been thoroughly validated using both automated tests and human reviewer reviews. By using a structured search strategy, the model is forced to incorporate increasingly complex and diverse viewpoints rather than straying into recurring patterns. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content