This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also data preparation and ML pipelines that can automate the retraining process. But there is still an engineering challenge.
To promote the success of this migration, we collaborated with the AWS team to create automated and intelligent digital experiences that demonstrated Rockets understanding of its clients and kept them connected. With just one part-time MLengineer for support, our average issue backlog with the vendor is practically non-existent.
Often the Data Team, comprising Data and MLEngineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL data pipeline in ML? Let’s look at the importance of ETL pipelines in detail.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. MLEngineer at Tiger Analytics. The large machine learning (ML) model development lifecycle requires a scalable model release process similar to that of software development. This post is co-written with Jayadeep Pabbisetty, Sr.
Artificial intelligence (AI) and machine learning (ML) offerings from Amazon Web Services (AWS) , along with integrated monitoring and notification services, help organizations achieve the required level of automation, scalability, and model quality at optimal cost.
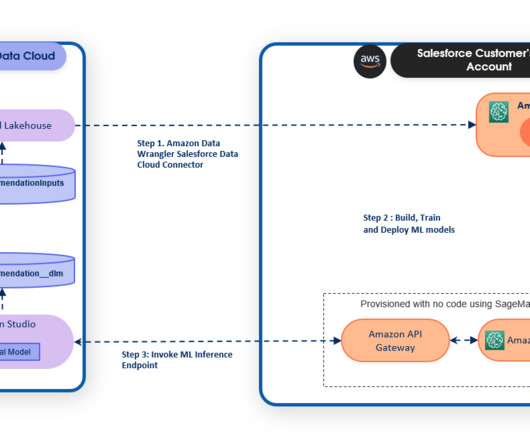
It eliminates tedious, costly, and error-prone ETL (extract, transform, and load) jobs. For example, you can use automated workflows that can adapt in an instant based on new data. We also provided an automated solution to deploy the SageMaker endpoints as an API using a SageMaker Projects template for Salesforce.
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
📢 Event: apply(risk), the MLEngineering Community Conference for Building Risk & Fraud Detection Systems Want to connect with the MLengineering community and learn best practices from ML practitioners at Affirm, Remitly, Block, Tide, and more, on how to build risk and fraud detection systems?
Automation : Automating as many tasks to reduce human error and increase efficiency. Collaboration : Ensuring that all teams involved in the project, including data scientists, engineers, and operations teams, are working together effectively. If you aren’t aware already, let’s introduce the concept of ETL.
We’ll see how this architecture applies to different classes of ML systems, discuss MLOps and testing aspects, and look at some example implementations. Understanding machine learning pipelines Machine learning (ML) pipelines are a key component of ML systems. But what is an ML pipeline?
The DevOps and Automation Ops departments are under the infrastructure team. The AI/ML teams are in the services department under infrastructure teams but related to AI, and a few AI teams are working on ML-based solutions that clients can consume. On top of the teams, they also have departments.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content