This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Extract, Transform, and Load are referred to as ETL. ETL is the process of gathering data from numerous sources, standardizing it, and then transferring it to a central database, data lake, data warehouse, or data store for additional analysis. Involved in each step of the end-to-end ETL process are: 1.
Initially, organizations struggled with versioning, monitoring, and automating model updates. As MLOps matured, discussions shifted from simple automation to complex orchestration involving continuous integration, deployment (CI/CD), and model drift detection.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Uber’s prowess as a transportation, logistics and analytics company hinges on their ability to leverage data effectively. The pursuit of hyperscale analytics The scale of Uber’s analytical endeavor requires careful selection of dataplatforms with high regard for limitless analytical processing.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. Analytic data is stored in Amazon Redshift.
It’s often described as a way to simply increase data access, but the transition is about far more than that. When effectively implemented, a data democracy simplifies the data stack, eliminates data gatekeepers, and makes the company’s comprehensive dataplatform easily accessible by different teams via a user-friendly dashboard.
The first generation of data architectures represented by enterprise data warehouse and business intelligence platforms were characterized by thousands of ETL jobs, tables, and reports that only a small group of specialized data engineers understood, resulting in an under-realized positive impact on the business.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. Automated development: Automatesdata preparation, model development, feature engineering and hyperparameter optimization using AutoAI.
The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for data ingestion. The objective is to automatedata integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa.
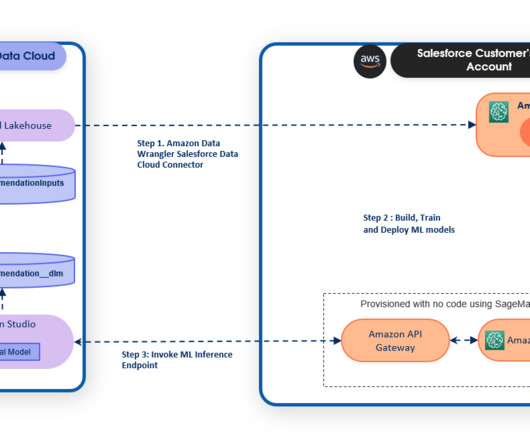
As a result, businesses can accelerate time to market while maintaining data integrity and security, and reduce the operational burden of moving data from one location to another. With Einstein Studio, a gateway to AI tools on the dataplatform, admins and data scientists can effortlessly create models with a few clicks or using code.
Align your data strategy to a go-forward architecture, with considerations for existing technology investments, governance and autonomous management built in. Look to AI to help automate tasks such as data onboarding, data classification, organization and tagging.
Businesses that require assistance with managing or personalizing procedures related to huge data quality can use the company’s range of professional services and support offerings. Collibra Data Intelligence Platform Launched in 2008, Collibra offers corporate users data intelligence capabilities.
Scaling ground truth generation with a pipeline To automate ground truth generation, we provide a serverless batch pipeline architecture, shown in the following figure. The serverless batch pipeline architecture we presented offers a scalable solution for automating this process across large enterprise knowledge bases. 201% $12.2B
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve data quality, and support Advanced Analytics like Machine Learning. These tools automate the process, making it faster and more accurate.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
As the volume of data keeps increasing at an accelerated rate, these data tasks become arduous in no time leading to an extensive need for automation. This is what data processing pipelines do for you. Let’s understand how the other aspects of a data pipeline help the organization achieve its various objectives.
Data gathering, pre-processing, modeling, and deployment are all steps in the iterative process of predictive analytics that results in output. We can automate the procedure to deliver forecasts based on new data continuously fed throughout time. This tool’s user-friendly UI consistently receives acclaim from users.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Our cloud data engineering services are designed to transform your business by creating robust and scalable data foundations across any scale. We provide comprehensive solutions to assess, architect, build, deploy, and automate your data engineering landscape on the leading cloud platforms.
Whether you aim for comprehensive data integration or impactful visual insights, this comparison will clarify the best fit for your goals. Key Takeaways Microsoft Fabric is a full-scale dataplatform, while Power BI focuses on visualising insights. Data Activator : Automates workflows, making data-triggered actions possible.
By automating repetitive tasks and generating boilerplate code, these tools free up time for engineers to focus on more complex, creative aspects of software development. Well, it is offering a way to automate the time-consuming process of writing and running tests. Just keep in mind, that this shouldn’t replace the human element.
How to set up an ML Platform in eCommerce? The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from data preparation to model deployment and monitoring. An ML Platform helps in the faster iteration of an ML project lifecycle. via Data Connectors.
Keeping track of how exactly the incoming data (the feature pipeline’s input) has to be transformed and ensuring that each model receives the features precisely how it saw them during training is one of the hardest parts of architecting ML systems. One of the core principles of MLOps is automation. What is a feature store?
Cloud-based data storage solutions, such as Amazon S3 (Simple Storage Service) and Google Cloud Storage, provide highly durable and scalable repositories for storing large volumes of data. These services automate infrastructure management tasks, allowing data engineers and scientists to focus on data processing and analysis.
Experimenting with LLMs to automate fact generation from QA ground truth using LLMs can help. Automate, but verify, with LLMs – Use LLMs to generate initial ground truth answers and facts, with a human review and curation to align with the desired assistant output standards.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content