This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Routine tasks Automation AI CRMs are designed to automate routine tasks, such as customer behavior analysis, data entry, customer follow-up emails, delivery status, sales entries, etc. Automation saves time while allowing teams to focus on strategic planning and innovation.
This capability is essential for fast-paced industries, helping businesses make quick, data-driven decisions, often with automation. By using structured, unstructured , and real-time data, prescriptive AI enables smarter, more proactive decision-making. Each plays a unique role in delivering accurate and context-aware insights.
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale dataingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
Introduction Azure data factory (ADF) is a cloud-based dataingestion and ETL (Extract, Transform, Load) tool. The data-driven workflow in ADF orchestrates and automatesdata movement and data transformation.
It is no longer sufficient to control data by restricting access to it, and we should also track the use cases for which data is accessed and applied within analytical and operational solutions. Moreover, data is often an afterthought in the design and deployment of gen AI solutions, leading to inefficiencies and inconsistencies.
Drasi’s machine learning capabilities help it integrate smoothly with various data sources, including IoT devices, databases, social media, and cloud services. This broad compatibility provides a complete view of data, helping companies identify patterns, detect anomalies , and automate responses effectively.
Summary: Dataingestion is the process of collecting, importing, and processing data from diverse sources into a centralised system for analysis. This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. This is where dataingestion comes in.
“If you think about building a data pipeline, whether you’re doing a simple BI project or a complex AI or machine learning project, you’ve got dataingestion, data storage and processing, and data insight – and underneath all of those four stages, there’s a variety of different technologies being used,” explains Faruqui.
The average cost of a data breach set a new record in 2023 of USD 4.45 On the bright side, data also shows that artificial intelligence (AI) and automation can improve security readiness and speed response to attacks, to help dramatically shrink the data breach window before causing real harm.
Additionally, they accelerate time-to-market for AI-driven innovations by enabling rapid dataingestion and retrieval, facilitating faster experimentation. Photo by Caspar Camille Rubin ) Want to learn more about AI and big data from industry leaders?
You can implement this workflow in Forecast either from the AWS Management Console , the AWS Command Line Interface (AWS CLI), via API calls using Python notebooks , or via automation solutions. The console and AWS CLI methods are best suited for quick experimentation to check the feasibility of time series forecasting using your data.
Artificial intelligence (AI) is revolutionizing industries by enabling advanced analytics, automation and personalized experiences. Accelerated data processing Efficient data processing pipelines are critical for AI workflows, especially those involving large datasets.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. Rockets legacy data science architecture is shown in the following diagram.
By automating document ingestion, chunking, and embedding, it eliminates the need to manually set up complex vector databases or custom retrieval systems, significantly reducing development complexity and time. Deploying the agent with other resources is automated through the provided AWS CloudFormation template.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting dataingestion.
SnapLogic , a leader in generative integration and automation, has introduced the industry’s first low-code generative AI development platform, Agent Creator , designed to democratize AI capabilities across all organizational levels. This post is cowritten with Greg Benson, Aaron Kesler and David Dellsperger from SnapLogic. Not anymore!
The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies. The framework provisions resources in a safe, repeatable manner, allowing for a significant acceleration of the development process.
AI has been shaping the media and entertainment industry for decades, from early recommendation engines to AI-driven editing and visual effects automation. Real-time AI which lets companies actively drive content creation, personalize viewing experiences and rapidly deliver data insights marks the next wave of that transformation.
Successful hybrid cloud strategies require a unified control and management plane, enabling automated deployment of applications across various environments, comprehensive observability and improved cyber resiliency.
This feature automatesdata layout optimization to enhance query performance and reduce storage costs. Key Features and Benefits: AutomatedData Layout Optimization: Predictive Optimization leverages AI to analyze query patterns and determine the best optimizations for data layouts.
Despite this solution’s ability to effectively ingestdata and deliver insights to HR and other IBM business units, addressing data quality and reducing manual checks of the data, which can be labor-intensive and error-prone, remained a challenge. What is data quality? If so, what caused this spike?
At Snorkel, weve partnered with Databricks to create a powerful synergy between their data lakehouse and our Snorkel Flow AI data development platform. Ingesting raw data from Databricks into Snorkel Flow Efficient dataingestion is the foundation of any machine learning project. Sign up here!
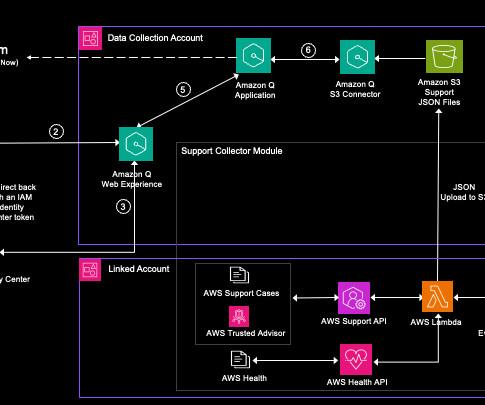
This deployment guide covers the steps to set up an Amazon Q solution that connects to Amazon Simple Storage Service (Amazon S3) and a web crawler data source, and integrates with AWS IAM Identity Center for authentication. An AWS CloudFormation template automates the deployment of this solution.
Forrester’s 2022 Total Economic Impact Report for Data Management highlights the impact Db2 and the IBM data management portfolio is having for customers: Return on investment (ROI) of 241% and payback <6 months. Both services offer independent compute and storage scaling, high availability, and automated DBA tasks.
The platform, although functional, deals with CSV and JSON files containing hundreds of thousands of rows from various manufacturers, demanding substantial effort for dataingestion. The objective is to automatedata integration from various sensor manufacturers for Accra, Ghana, paving the way for scalability across West Africa.
These include dataingestion, data selection, data pre-processing, FM pre-training, model tuning to one or more downstream tasks, inference serving, and data and AI model governance and lifecycle management—all of which can be described as FMOps.
Building and deploying these components can be complex and error-prone, especially when dealing with large-scale data and models. Solution overview The solution provides an automated end-to-end deployment of a RAG workflow using Knowledge Bases for Amazon Bedrock. Choose Sync to initiate the dataingestion job.
Objective of Data Engineering: The main goal is to transform raw data into structured data suitable for downstream tasks such as machine learning. This involves a series of semi-automated or automated operations implemented through data engineering pipeline frameworks.
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. Select the KB and in the Data source section, choose Sync to begin dataingestion. When dataingestion completes, a green success banner appears if it is successful.
There is also an automatedingestion job from Slack conversation data to the S3 bucket powered by an AWS Lambda function. The architectures strengths lie in its consistency across environments, automatic dataingestion processes, and comprehensive monitoring capabilities.
This post demonstrates how to seamlessly automate the deployment of an end-to-end RAG solution using Knowledge Bases for Amazon Bedrock and the AWS Cloud Development Kit (AWS CDK), enabling organizations to quickly set up a powerful question answering system. Choose Sync to initiate the dataingestion job.
Oftentimes, this requires implementing a “hot” part of the initial dataingest, or landing zone where applications and users can work as fast as possible. Can you elaborate on the AI-enabled workflow management features and how they streamline data processes?
Customers across all industries run IDP workloads on AWS to deliver business value by automating use cases such as KYC forms, tax documents, invoices, insurance claims, delivery reports, inventory reports, and more. Effectively manage your data and its lifecycle Data plays a key role throughout your IDP solution.
This allows you to create rules that invoke specific actions when certain events occur, enhancing the automation and responsiveness of your observability setup (for more details, see Monitor Amazon Bedrock ). The job could be automated based on a ground truth, or you could use humans to bring in expertise on the matter.
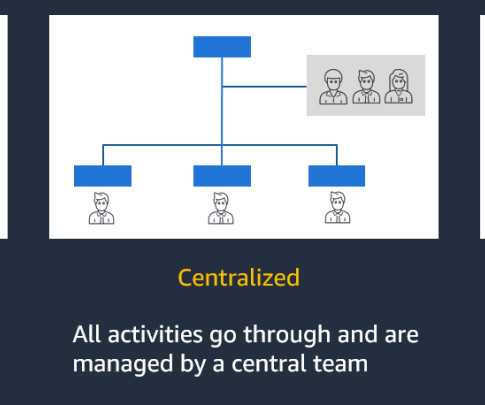
Next generation of big data platforms and long running batch jobs operated by a central team of data engineers have often led to data lake swamps. Both approaches were typically monolithic and centralized architectures organized around mechanical functions of dataingestion, processing, cleansing, aggregation, and serving.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from dataingestion to model deployment. Architecture overview Our MLOps architecture is designed to automate and monitor all stages of the ML lifecycle. Saurabh Gupta is a Principal Engineer at Zeta Global.
They implement landing zones to automate secure account creation and streamline management across accounts, including logging, monitoring, and auditing. With Amazon Bedrock Knowledge Bases , you securely connect FMs in Amazon Bedrock to your company data for RAG.
There are considered three main layers of the process data lakes use to receive and store new data. Dataingestion is when new data is introduced and absorbed into the lake. The processing layer is when data is managed and sorted into its storage category.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. Choose the car-data-ingestion-pipeline.
Automation levels The SAE International (formerly called as Society of Automotive Engineers) J3016 standard defines six levels of driving automation, and is the most cited source for driving automation. This ranges from Level 0 (no automation) to Level 5 (full driving automation), as shown in the following table.
In order analyze the calls properly, Principal had a few requirements: Contact details: Understanding the customer journey requires understanding whether a speaker is an automated interactive voice response (IVR) system or a human agent and when a call transfer occurs between the two.
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. These components include an Amazon S3 data source connector, required IAM roles, and Amazon Q Business web experience.
Summary: Apache NiFi is a powerful open-source dataingestion platform design to automatedata flow management between systems. Its architecture includes FlowFiles, repositories, and processors, enabling efficient data processing and transformation.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content