This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data. Test the knowledge base Once the data sync is complete: Choose the expansion icon to expand the full view of the testing area.
When using the FAISS adapter, translation units are stored into a local FAISS index along with the metadata. Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores. When the indexing is complete, select the created index from the index dropdown. Rerun the translation.
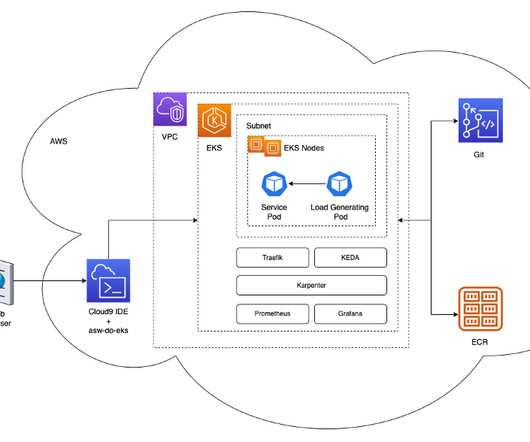
We use Amazon EKS and were looking for the best solution to auto scale our worker nodes. Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics.
For years, Rad AI has been a reliable partner to radiology practices and health systems, consistently delivering high availability and generating complete results seamlessly in 0.5–3 The pipeline begins when researchers manage tags and metadata on the corresponding model artifact. 3 seconds, with minimal latency.
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
Visit octus.com to learn how we deliver rigorously verified intelligence at speed and create a complete picture for professionals across the entire credit lifecycle. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract. Follow Octus on LinkedIn and X.
With the SageMaker HyperPod auto-resume functionality, the service can dynamically swap out unhealthy nodes for spare ones to ensure the seamless continuation of the workload. Also included are SageMaker HyperPod cluster software packages, which support features such as cluster health check and auto-resume.
This time-consuming process must be completed before content can be dubbed into another language. SageMaker asynchronous endpoints support upload sizes up to 1 GB and incorporate auto scaling features that efficiently mitigate traffic spikes and save costs during off-peak times. in a code subdirectory. in a code subdirectory.
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. For a given dataset and preprocessing job, the CPU may be undersized, resulting in maxed out processing performance and lengthy times to complete.
Our solution uses an FSx for ONTAP file system as the source of unstructured data and continuously populates an Amazon OpenSearch Serverless vector database with the user’s existing files and folders and associated metadata. Prerequisites Complete the following prerequisite steps: Make sure you have model access in Amazon Bedrock.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. The company found that data scientists were having to remove features from algorithms just so they would run to completion.
Auto-Completion and Refactoring: Enhances coding efficiency and readability. Key Features: Comprehensive Versioning: Beyond just data, DVC versions metadata, plots, models, and entire ML pipelines. Debugging and Code Navigation: Streamlines the debugging process and allows easy navigation through your codebase.
When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Flexibility, speed, and accessibility : can you customize the metadata structure? Can you see the complete model lineage with data/models/experiments used downstream?
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ). 2xlarge instances.
Tabnine for JupyterLab Typing code is complex without auto-complete options, especially when first starting out. In addition to the spent time inputting method names, the absence of auto-complete promotes shorter naming styles, which is not ideal. For a development environment to be effective, auto-complete is crucial.
SageMaker simplifies the process of managing dependencies, container images, auto scaling, and monitoring. To install the controller in your EKS cluster, complete the following steps: Configure IAM permissions to make sure the controller has access to the appropriate AWS resources. amazonaws.com/sagemaker-xgboost:1.7-1",
Prerequisites To implement this solution, you need the following: Historical and real-time user click data for the interactions dataset Historical and real-time news article metadata for the items dataset Ingest and prepare the data To train a model in Amazon Personalize, you need to provide training data.
Before you start To complete this tutorial, you'll need: An upgraded AssemblyAI account A DeepL API account. It returns metadata about the submitted transcription, from which the ID is used to set the ID of the Job. The frontend will periodically poll this route to determine when the transcription is complete.
You can use large language models (LLMs), more specifically, for tasks including summarization, metadata extraction, and question answering. SageMaker endpoints are fully managed and support multiple hosting options and auto scaling. Complete the following steps: On the Amazon S3 console, choose Buckets in the navigation pane.
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. Set up your environment To set up your environment, complete the following steps: Launch a SageMaker notebook instance with a g5.xlarge xlarge instance.
jpg and the completemetadata from styles/38642.json. Each product is identified by an ID such as 38642, and there is a map to all the products in styles.csv. From here, we can fetch the image for this product from images/38642.jpg As a result, you can deploy the model as a normal model without any additional code.
When the script ends, a completion status along with the time taken will be returned to the SageMaker studio console. These JSON files will contain all the Amazon Textract metadata, including the text that was extracted from within the documents. The following diagram illustrates the sequence of events within the script.
Launch the instance using Neuron DLAMI Complete the following steps: On the Amazon EC2 console, choose your desired AWS Region and choose Launch Instance. You can update your Auto Scaling groups to use new AMI IDs without needing to create new launch templates or new versions of launch templates each time an AMI ID changes.
In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
With SageMaker Data Wrangler, you can simplify the process of data preparation and feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization from a single visual interface. million reviews spanning May 1996 to July 2014. Next, select a training method.
Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. There will be only one type of ML metadata store (model-first), not three. We saw fashion designers sign up for our ML metadata store. Lived through the DevOps revolution. Came to ML from software. So to speak.
A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings. The score ranges from 0–1, with higher scores indicating greater semantic similarity between the two answers.
script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. When this step is complete, delete the cluster by using the following script in the eks folder: /eks-delete.sh Unless you specify Spot Instances in conf, instances will be created on demand. eks-create.sh
In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration. Click “Submit” to finalize.
Source Architecture and training PaLM-E is a decoder-only LLM that auto-regressively generates text using a multimodal prompt consisting of text, tokenized image embeddings, and state estimates representing quantities like a robot’s position, orientation, and velocity. lack of annotated data, unreliable labels, noisy inputs).
To solve this problem, we make the ML solution auto-deployable with a few configuration changes. The training and inference ETL pipeline creates ML features from the game logs and the player’s metadata stored in Athena tables, and stores the resulting feature data in an Amazon Simple Storage Service (Amazon S3) bucket.
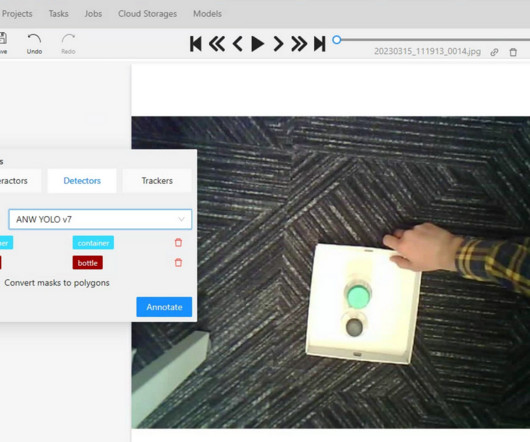
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
auto-evaluation) and using human-LLM hybrid approaches. It will take as input the text generated by an LLM and some metadata, and then output a score that indicates the quality of the text. Auto-evaluation and Hybrid approaches are often used in enterprise settings to scale LLM performance evaluation.
Evaluating Prompt Completion: The goal is to establish effective evaluation criteria to gauge LLMs’ performance across tasks and domains. Auto Eval Common Metric Eval Human Eval Custom Model Eval 3. Various prompting techniques, such as Zero/Few Shot, Chain-of-Thought (CoT)/Self-Consistency, ReAct, etc.
To store information in Secrets Manager, complete the following steps: On the Secrets Manager console, choose Store a new secret. Complete the following steps: On the Secrets Manager console, choose Store a new secret. Always make sure that sensitive data is handled securely to avoid potential security risks.
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. This results in faster restarts and workload completion. Amazon FSx is an open-source parallel file system, popular in high-performance computing (HPC).
in their paper Auto-Encoding Variational Bayes. script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. Auto-Encoding Variational Bayes. VAEs were introduced in 2013 by Diederik et al. The config.py The torch.nn
You would address it in a completely different way, depending on what’s the problem. This is more about picking, for some active learning or for knowing where the data comes from and knowing the metadata to focus on the data that are the most relevant to start with. This is a much smaller scale than Auto ML.
Others, toward language completion and further downstream tasks. In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Very large core pie, and very efficient in certain sets of things. Let’s take a look at what the breakdown is.
Others, toward language completion and further downstream tasks. In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Very large core pie, and very efficient in certain sets of things. Let’s take a look at what the breakdown is.
Model management Teams typically manage their models, including versioning and metadata. Observability tools: Use platforms that offer comprehensive observability into LLM performance, including functional logs (prompt-completion pairs) and operational metrics (system health, usage statistics). using techniques like RLHF.)
Using new_from_file only loads image metadata. The return value will contain a NumPy array of unsigned 8-bit integers with scaled image contents. Please note that the libvips API creates an image processing pipeline. Same thing with resize : no actual resizing is performed. A CSV file guides execution.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content