This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Home Table of Contents Getting Started with Python and FastAPI: A Complete Beginner’s Guide Introduction to FastAPI Python What Is FastAPI? Your First Python FastAPI Endpoint Writing a Simple “Hello, World!” Jump Right To The Downloads Section Introduction to FastAPI Python What Is FastAPI?
Technical Deep Dive of Llama 2 For training the Llama 2 model; like its predecessors, it uses an auto-regressive transformer architecture , pre-trained on an extensive corpus of self-supervised data. OpenAI has provided an insightful illustration that explains the SFT and RLHF methodologies employed in InstructGPT.
Heres a quick recap of what you learned: Introduction to FastAPI: We explored what makes FastAPI a modern and efficient Python web framework, emphasizing its async capabilities, automatic API documentation, and seamless integration with Pydantic for data validation. By the end, youll have a fully functional API ready for real-world use cases.
GitHub Copilot GitHub Copilot is an AI-powered code completion tool that analyzes contextual code and delivers real-time feedback and recommendations by suggesting relevant code snippets. Tabnine Tabnine is an AI-based code completion tool that offers an alternative to GitHub Copilot.
Another innovative framework, Chameleon, takes a “plug-and-play” approach, allowing a central LLM-based controller to generate natural language programs that compose and execute a wide range of tools, including LLMs, vision models, web search engines, and Python functions.
It explains the fundamentals of LLMs and generative AI and also covers prompt engineering to improve performance. The book covers topics like Auto-SQL, NER, RAG, Autonomous AI agents, and others. LangChain Handbook This book is a complete guide to integrating and implementing LLMs using the LangChain framework.
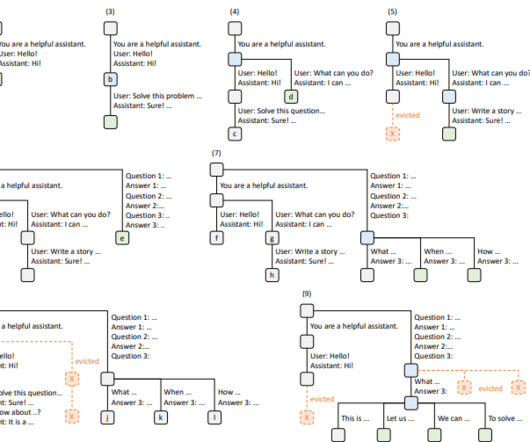
This is because a large portion of the available memory bandwidth is consumed by loading the model’s parameters and by the auto-regressive decoding process.As Batching techniques In this section, we explain different batching techniques and show how to implement them using a SageMaker LMI container.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. Discover Falcon 2 11B in SageMaker JumpStart You can access the FMs through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. After deployment is complete, you will see that an endpoint is created.
The decode phase includes the following: Completion – After the prefill phase, you have a partially generated text that may be incomplete or cut off at some point. The decode phase is responsible for completing the text to make it coherent and grammatically correct. The default is 32.
These new use cases necessitate multiple, often dependent, LLM generation calls, indicating a trend of using multi-call structures to complete complex tasks. SGLang is a domain-specific language embedded in Python, providing primitives for generation (e.g., SGLang is a domain-specific language embedded in Python. fork, join).
complete def fibonacci Another thing I really like is that Copilot doesn't just stop after giving a response. Here are some of my favorite commands: Diving deeper into the code: /explain Getting unstuck or fixing code snags: /fix Conducting tests on the code: /tests I have to say Copilot is one of my favorite tools.
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. Solution overview In this blog, we will walk through the following scenarios : Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK.
Let me explain. Our model gets a prompt and auto-completes it. Transformers is a library in Hugging Face that provides APIs and tools. It allows you to easily download and train state-of-the-art pre-trained models. You may ask what pre-trained models are. The goal of text generation is to generate meaningful sentences.
We compare the existing solutions and explain how they work behind the scenes. General purpose coding agents Auto-GPT Auto-GPT was one of the first AI agents using Large Language Models to make waves, mainly due to its ability to independently handle diverse tasks. It can be augmented or replaced by human feedback.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. and Pandas or Apache Spark DataFrames. Can you render audio/video?
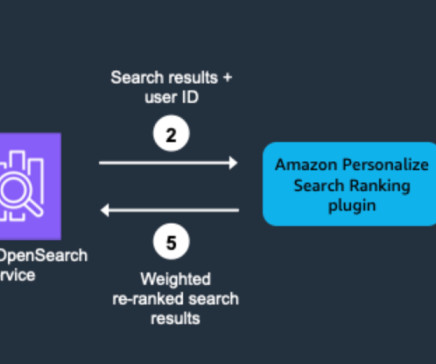
This post explains how to integrate the Amazon Personalize Search Ranking plugin with OpenSearch Service to enable personalized search experiences. Complete the following steps to deploy the stack: Sign in to the AWS Management Console with your credentials in the account where you want to deploy the CloudFormation stack.
You can use a managed service, such as Amazon Rekognition , to predict product attributes as explained in Automating product description generation with Amazon Bedrock. First, launch the notebook main.ipynb in SageMaker Studio by selecting the Image as Data Science and Kernel as Python 3. bias="none", # the bias type for Lora.
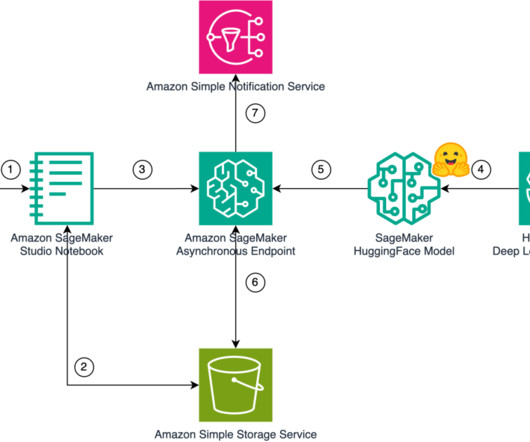
The following diagram shows how MusicGen, a single stage auto-regressive Transformer model, can generate high-quality music based on text descriptions or audio prompts. The model package contains a requirements.txt file that lists the necessary Python packages to be installed to serve the MusicGen model. Create a Hugging Face model.
Luckily, OpenCV is pip-installable: $ pip install opencv-contrib-python If you need help configuring your development environment for OpenCV, we highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes. . tensorflow and os ) on Lines 2 and 3. EPOCHS ) on Lines 20-23. here (i.e.,
LangChain is an open source Python library designed to build applications with LLMs. When you create an AWS account, you get a single sign-on (SSO) identity that has complete access to all the AWS services and resources in the account. There was no monitoring, load balancing, auto-scaling, or persistent storage at the time.
Create a KMS key in the dev account and give access to the prod account Complete the following steps to create a KMS key in the dev account: On the AWS KMS console, choose Customer managed keys in the navigation pane. Choose Create key. For Key type , select Symmetric. For Script Path , enter Jenkinsfile. Choose Save.
Build and deploy your own sentiment classification app using Python and Streamlit Source:Author Nowadays, working on tabular data is not the only thing in Machine Learning (ML). In this article, you will learn about what sentiment analysis is and how you can build and deploy a sentiment analysis system in Python.
The flexible and extensible interface of SageMaker Studio allows you to effortlessly configure and arrange ML workflows, and you can use the AI-powered inline coding companion to quickly author, debug, explain, and test code. Complete the following steps to edit an existing space: On the space details page, choose Stop space.
Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. TGI is implemented in Python and uses the PyTorch framework. Please explain the main clinical purpose of such image?Can The Python utility script dino_sam_inpainting.py
Now you can also fine-tune 7 billion, 13 billion, and 70 billion parameters Llama 2 text generation models on SageMaker JumpStart using the Amazon SageMaker Studio UI with a few clicks or using the SageMaker Python SDK. What is Llama 2 Llama 2 is an auto-regressive language model that uses an optimized transformer architecture.
Save the python file, go in the terminal and run: beam deploy tweet.py -p "default" you should see something like this… Your default browser will open on a new tab with the app: clicking on the API button will reveal you the code and parameters required for calling the app. Select the python TAB to get the details for HTTP request.
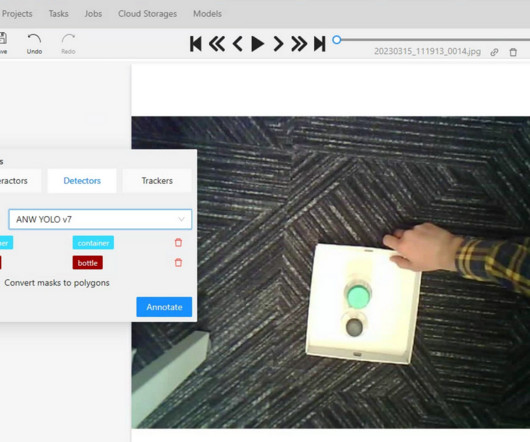
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
DataRobot Notebooks is a fully hosted and managed notebooks platform with auto-scaling compute capabilities so you can focus more on the data science and less on low-level infrastructure management. We will be writing code in Python, but DataRobot Notebooks also supports R if that’s your preferred language. Auto-scale compute.
def callbacks(): # build an early stopping callback and return it callbacks = [ tf.keras.callbacks.EarlyStopping( monitor="val_loss", min_delta=0, patience=2, mode="auto", ), ] return callbacks On Lines 12-22 , the function callbacks defines an early stopping callback and returns it. def normalize_layer(factor=1./127.5): That’s not the case.
Since a lot of developers are working on Python we continued to trainStarCoder for about 35B tokens (~3% of full training) on the Python subset which lead to a significant performance boost. Could you explain the data curation and training process required for building such a model? data or auto-generated files).
The best example is OpenAI’s ChatGPT, the well-known chatbot that does everything from content generation and code completion to question answering, just like a human. Auto-GPT, the free-of-cost and open-source in nature Python application, uses GPT-4 technology. The range of functions provided by Auto-GPT is limited.
We can install this library in the same way as other Python libraries, using pip . Image by Author If you want to end the experiment, you can use the end method of the Experiment object to mark the experiment as complete. # This dataset consists of 60,000 training grayscale images of handwritten digits between 0 to 9.
Secret Manager: obtaining secrets at runtime Container Registry: for Docker image storage Cloud Run: managed serverless runtime environment Prerequisites GitHub Repository To complete this tutorial, you’ll need some additional code, but we’ve got you covered. You can see the complete installation process by clicking here.
Notice that this forms our forward cyclic consistency cycle, as explained in Part 1 of this series. Notice that this forms our backward cyclic consistency cycle, as explained in Part 1 of this series. trainInput = trainInput.map( read_train_example, num_parallel_calls=AUTO).shuffle( cycledImageX ). genImagesX , Line 40 ).
It will further explain the various containerization terms and the importance of this technology to the machine learning workflow. These Python virtual environments encapsulate and manage Python dependencies, while Docker encapsulates the project’s dependency stack down to the host OS. Prerequisite Python 3.8
Most employees don’t master the conventional data science toolkit (SQL, Python, R etc.). On a more advanced stance, everyone who has done SQL query optimisation will know that many roads lead to the same result, and semantically equivalent queries might have completely different syntax.
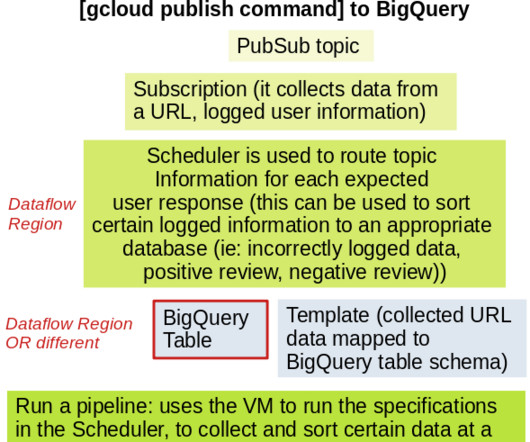
As someone who has little experience in app design, I found it unfortunate that reference [1] did not explain or give references for how the data is sent from [link] such that readers could have confidence that the data source and data are correct. $TABLE_name,javascriptTextTransformGcsPath=gs://$BUCKET_NAME/dataflow_udf_transform.js,javascriptTextTransformFunctionName=process
in their paper Auto-Encoding Variational Bayes. Auto-Encoding Variational Bayes. With that, we’ve completed the training of a variational autoencoder on the Fashion-MNIST dataset. All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms.
There will be a lot of tasks to complete. But I have to say that this data is of great quality because we already converted it from messy data into the Python dictionary format that matches our type of work. I tried learning how to code the Gradio interface in Python. Are you ready to explore? Let’s begin! In the end, it worked.
How would you explain deploying models on GPU in one minute? People will auto-scale up to 10 GPUs to handle the traffic. I think the other block is the… If you’re not familiar with the Python Global Interpreter Lock. For CPU, for most code, if you’re doing Python, you can do step-3 debugging.
Once the exploratory steps are completed, the cleansed data is subjected to various algorithms like predictive analysis, regression, text mining, recognition patterns, etc depending on the requirements. Define and explain selection bias? It is the discounting of those subjects that did not complete the trial.
We can well explain this in a cancer detection example. The lines are then parsed into pythonic dictionaries. Processing large medical images Handling large TIFF input images cannot be implemented using standard Python tools for image loading ( PIL ) simply because of memory constraints. Patient ID is used as the key.
A good analogy that explains this process is JPEG compression. Their Transformers Python library is particularly useful, especially if you’re a more advanced user looking to build fine-tuning or complex inference with the ability to customize the code that loads, runs, and trains your models.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content