This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The graph, stored in Amazon Neptune Analytics, provides enriched context during the retrieval phase to deliver more comprehensive, relevant, and explainable responses tailored to customer needs. By linking this contextual information, the generative AI system can provide responses that are more complete, precise, and grounded in source data.
This includes features for model explainability, fairness assessment, privacy preservation, and compliance tracking. When thinking about a tool for metadata storage and management, you should consider: General business-related items : Pricing model, security, and support. Is it fast and reliable enough for your workflow?
Explainability – Providing transparency into why certain stories are recommended builds user trust. When the ETL process is complete, the output file is placed back into Amazon S3, ready for ingestion into Amazon Personalize via a dataset import job. For example, article metadata may contain company and industry names in the article.
You can use a managed service, such as Amazon Rekognition , to predict product attributes as explained in Automating product description generation with Amazon Bedrock. jpg and the completemetadata from styles/38642.json. Each product is identified by an ID such as 38642, and there is a map to all the products in styles.csv.
We’ll walk through the data preparation process, explain the configuration of the time series forecasting model, detail the inference process, and highlight key aspects of the project. In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion.
The modal can explain an image (1, 2) or answer questions based on an image (3, 4). Multimodal datasets may reduce ethical issues as they are more diverse and contextually complete and may improve model fairness. combining video with text metadata may reveal sensitive information).) Examples of different Kosmos-1 tasks.
Founded neptune.ai , a modular MLOps component for ML metadata store , aka “experiment tracker + model registry”. There will be only one type of ML metadata store (model-first), not three. Ok, let me explain. Let me explain. We saw fashion designers sign up for our ML metadata store. Came to ML from software.
A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings. The score ranges from 0–1, with higher scores indicating greater semantic similarity between the two answers.
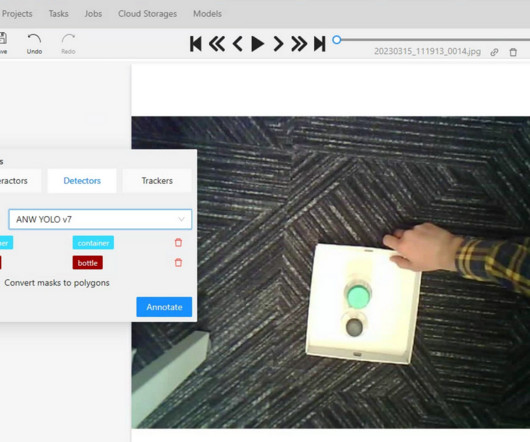
the UI for annotation, image ref: [link] The base containers that run when we put the CVAT stack up (not included auto annotation) (Semi) automated annotation The CVAT (semi) automated annotation allow user to use something call nuclio , which is a tool aimed to assist automated data science through serverless deployment.
Evaluating Prompt Completion: The goal is to establish effective evaluation criteria to gauge LLMs’ performance across tasks and domains. Auto Eval Common Metric Eval Human Eval Custom Model Eval 3. Various prompting techniques, such as Zero/Few Shot, Chain-of-Thought (CoT)/Self-Consistency, ReAct, etc.
in their paper Auto-Encoding Variational Bayes. script sets up the autoencoder model hyperparameters and creates an output directory for storing training progress metadata, model weights, and post-training analysis plots. Auto-Encoding Variational Bayes. VAEs were introduced in 2013 by Diederik et al. The config.py The torch.nn
Michal, to warm you up for all this question-answering, how would you explain to us managing computer vision projects in one minute? You would address it in a completely different way, depending on what’s the problem. Michal: As I explained at some point to me, I wouldn’t say it’s much more complex.
Model management Teams typically manage their models, including versioning and metadata. Observability tools: Use platforms that offer comprehensive observability into LLM performance, including functional logs (prompt-completion pairs) and operational metrics (system health, usage statistics). using techniques like RLHF.)
We can well explain this in a cancer detection example. Using new_from_file only loads image metadata. If any of the observations in a bag has a positive label, the whole bag is considered positive. Otherwise, the entire bag is considered negative. The model is trained on bags of observations. A CSV file guides execution.
Transparency and explainability : Making sure that AI systems are transparent, explainable, and accountable. However, explaining why that decision was made requires next-level detailed reports from each affected model component of that AI system. It can take up to 20 minutes for the setup to complete.
Additionally, this section explains how HyperPod provides a smooth developer experience for admins and scientists. Job auto resume – SageMaker HyperPod provides a job auto resume capability using the Kubeflow Training Operator for PyTorch to provide recovery and continuation of training jobs in the event of interruptions or failures.
The following diagram shows how MusicGen, a single stage auto-regressive Transformer model, can generate high-quality music based on text descriptions or audio prompts. When working with music generation models, it’s important to note that the process can often take more than 60 seconds to complete. Create a Hugging Face model.
DSX provides unmatched prevention and explainability by using a powerful combination of deep learning-based DSX Brain and generative AI DSX Companion to protect systems from known and unknown malware and ransomware in real-time. This situation hampers proactive threat hunting and exacerbates team burnout.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content