This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Explainability – Providing transparency into why certain stories are recommended builds user trust. AWS Glue performs extract, transform, and load (ETL) operations to align the data with the Amazon Personalize datasets schema. We discuss more about how to use items and interactions data attributes in DynamoDB later in this post.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
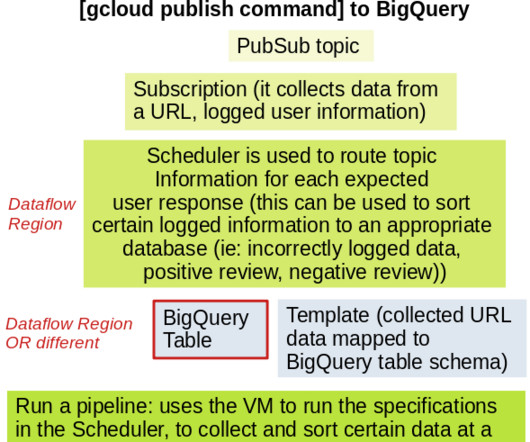
BigQuery is very useful in terms of having a centralized location of structured data; ingestion on GCP is wonderful using the ‘bq load’ command line tool for uploading local .csv PubSub and Dataflow are solutions for storing newly created data from website/application activity, in either BigQuery or Google Cloud Storage.
Observability tools: Use platforms that offer comprehensive observability into LLM performance, including functional logs (prompt-completion pairs) and operational metrics (system health, usage statistics). Develop the text preprocessing pipeline Dataingestion: Use Unstructured.io
Complete ML model training pipeline workflow | Source But before we delve into the step-by-step model training pipeline, it’s essential to understand the basics, architecture, motivations, challenges associated with ML pipelines, and a few tools that you will need to work with. to log your experiments. Let’s get started! optuna== 3.1.0
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content