

Llamaindex Query Pipelines: Quickstart Guide to the Declarative Query API
Towards AI
FEBRUARY 7, 2024
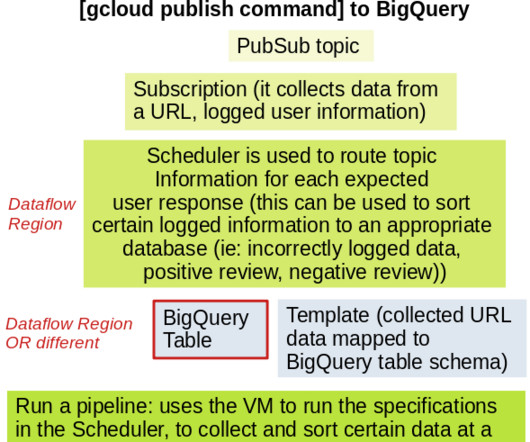
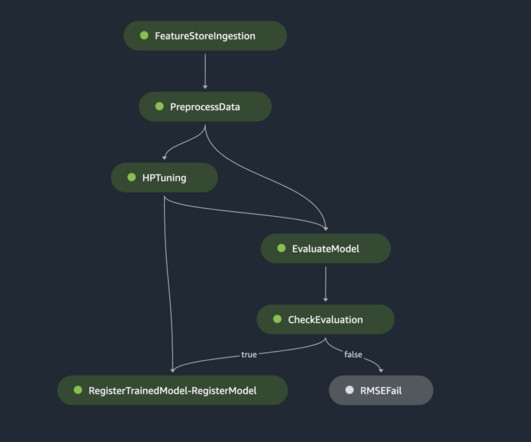
prompt -> LLM prompt -> LLM -> prompt -> LLM retriever -> response synthesizer As a full DAG (more expressive) When you are required to set up a complete DAG, for instance, a Retrieval Augmented Generation (RAG) pipeline. Sequential Chain Simple Chain: Prompt Query + LLM The simplest approach, define a sequential chain.













Let's personalize your content