This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Researchers want to create a system that eventually learns to bypass humans completely by completing the research cycle without human involvement. Fudan University and the Shanghai Artificial Intelligence Laboratory have developed DOLPHIN, a closed-loop auto-research framework covering the entire scientific research process.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. The following diagram shows our solution architecture.
It suggests code snippets and even completes entire functions based on natural language prompts. TabNine TabNine is an AI-powered code auto-completion tool developed by Codota, designed to enhance coding efficiency across a variety of Integrated Development Environments (IDEs).
fine_tuned_nv_embed") print(" Training Complete! Finally, we save the fine-tuned model and its tokenizer to the specified directory and then print a confirmation message indicating that training is complete and the model is saved. fine_tuned_nv_embed") tokenizer.save_pretrained("./fine_tuned_nv_embed") Model Saved.")
The insurance provider receives payout claims from the beneficiary’s attorney for different insurance types, such as home, auto, and life insurance. When this is complete, the document can be routed to the appropriate department or downstream process. Custom classification is a two-step process.
Use case overview The use case outlined in this post is of heart disease data in different organizations, on which an ML model will run classification algorithms to predict heart disease in the patient. Choose the Training Status tab and wait for the training run to complete. Choose New Application.
Such a representation makes many subsequent tasks, including those involving vision, classification, recognition and segmentation, and generation, easier. Therefore, encoders, decoders, and auto-encoders can all be implemented using a roughly identical crate design. Furthermore, the crate model exhibits many useful features.
Based on this classification, it then decides whether to establish boundaries using visual-based shot sequences or audio-based conversation topics. Video The complete content that enables analysis at the full video level. Along with the summary, BDA generates a complete audio transcript that includes speaker identification.
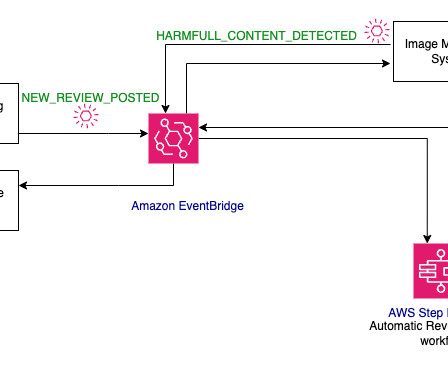
This post details how Purina used Amazon Rekognition Custom Labels , AWS Step Functions , and other AWS Services to create an ML model that detects the pet breed from an uploaded image and then uses the prediction to auto-populate the pet attributes. Start the model version when training is complete.
A typical application of GNN is node classification. The problems that GNNs are used to solve can be divided into the following categories: Node Classification: The goal of this task is to determine the labeling of samples (represented as nodes) by examining the labels of their immediate neighbors (i.e., their neighbors’ labels).
Optionally, if Account A and Account B are part of the same AWS Organizations, and the resource sharing is enabled within AWS Organizations, then the resource sharing invitation are auto accepted without any manual intervention. Following are the steps completed by using APIs to create and share a model package group across accounts.
Interactive Documentation: We showcased the power of FastAPIs auto-generated Swagger UI and ReDoc for exploring and testing APIs. This shared embedding space enables CLIP to perform tasks like zero-shot classification and cross-modal retrieval without additional fine-tuning. Join me in computer vision mastery.
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. Most of this process is the same for any binary classification except for the feature engineering step.
Hugging Face is a platform that provides pre-trained language models for NLP tasks such as text classification, sentiment analysis, and more. The NLP tasks we’ll cover are text classification, named entity recognition, question answering, and text generation. The pipeline we’re going to talk about now is zero-hit classification.
Table of Contents Training a Custom Image Classification Network for OAK-D Configuring Your Development Environment Having Problems Configuring Your Development Environment? Furthermore, this tutorial aims to develop an image classification model that can learn to classify one of the 15 vegetables (e.g.,
Here’s what you need to know: sktime is a Python package for time series tasks like forecasting, classification, and transformations with a familiar and user-friendly scikit-learn-like API. Build tuned auto-ML pipelines, with common interface to well-known libraries (scikit-learn, statsmodels, tsfresh, PyOD, fbprophet, and more!)
The models can be completely heterogenous, with their own independent serving stack. For example, an image classification use case may use three different models to perform the task. The scatter-gather pattern allows you to combine results from inferences run on three different models and pick the most probable classification model.
Legal research is a critical area for Thomson Reuters customers—it needs to be as complete as possible. To frame this research and give concrete evaluation targets, Thomson Reuters focused on several real-world tasks: legal summarization, classification, and question answering. 55 440 0.1 164 64 512 0.1
You can deploy this solution with just a few clicks using Amazon SageMaker JumpStart , a fully managed platform that offers state-of-the-art foundation models for various use cases such as content writing, code generation, question answering, copywriting, summarization, classification, and information retrieval.
When configuring your auto scaling groups for SageMaker endpoints, you may want to consider SageMakerVariantInvocationsPerInstance as the primary criteria to determine the scaling characteristics of your auto scaling group. Note that although the MMS configurations don’t apply in this case, the policy considerations still do.)
In a single visual interface, you can complete each step of a data preparation workflow: data selection, cleansing, exploration, visualization, and processing. Complete the following steps: Choose Prepare and analyze data. Complete the following steps: Choose Run Data quality and insights report. Choose Create. Choose Create.
The system is further refined with DistilBERT , optimizing our dialogue-guided multi-class classification process. Additionally, you benefit from advanced features like auto scaling of inference endpoints, enhanced security, and built-in model monitoring. To mitigate the effects of the mistakes, the diversity of demonstrations matter.
They are as follows: Node-level tasks refer to tasks that concentrate on nodes, such as node classification, node regression, and node clustering. Edge-level tasks , on the other hand, entail edge classification and link prediction. Graph-level tasks involve graph classification, graph regression, and graph matching.
Deploy the CloudFormation template Complete the following steps to deploy the CloudFormation template: Save the CloudFormation template sm-redshift-demo-vpc-cfn-v1.yaml Launch SageMaker Studio Complete the following steps to launch your SageMaker Studio domain: On the SageMaker console, choose Domains in the navigation pane.
Another option is to download complete data for your ML model training use cases using SageMaker Data Wrangler processing jobs. After you check out the data type matching applied by SageMaker Data Wrangler, complete the following steps: Choose the plus sign next to Data types and choose Add analysis. This is a one-time setup.
An output could be, e.g., a text, a classification (like “dog” for an image), or an image. It can perform visual dialogue, visual explanation, visual question answering, image captioning, math equations, OCR, and zero-shot image classification with and without descriptions. Basic structure of a multimodal LLM.
Based on the transformer architecture, Vicuna is an auto-regressive language model and offers natural and engaging conversation capabilities. The chatbot is designed for conversation and instruction and excels in summarizing, generating tables, classification, and dialog. trillion tokens. scripts, which are available on GitHub.
LLMs are specifically focused on language-based tasks such as summarization, text generation, classification, open-ended conversation, and information extraction. For most reviews, the system auto-generates a reply using an LLM. Large language models (LLMs) are one class of FMs. Execution.Input.review_text", "token.$": "$$.Task.Token",
For instance, a financial firm that needs to auto-generate a daily activity report for internal circulation using all the relevant transactions can customize the model with proprietary data, which will include past reports, so that the FM learns how these reports should read and what data was used to generate them.
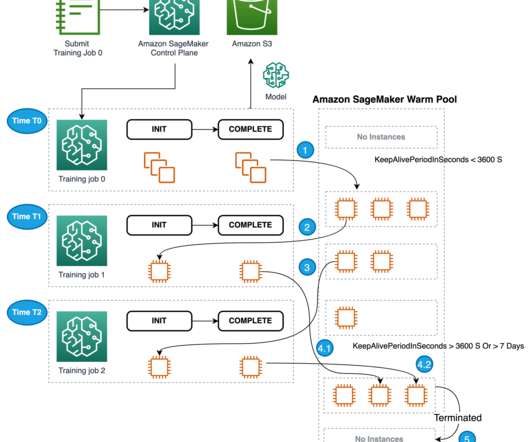
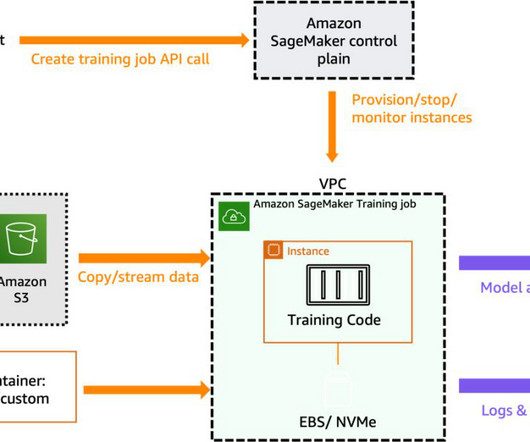
Best Egg trains multiple credit models using classification and regression algorithms. The trained model artifact is hosted on a SageMaker real-time endpoint using the built-in auto scaling and load balancing features. After the first training job is complete, the instances used for training are retained in the warm pool cluster.
This version offers support for new models (including Mixture of Experts), performance and usability improvements across inference backends, as well as new generation details for increased control and prediction explainability (such as reason for generation completion and token level log probabilities).
If the image is completely unmodified, then all 8×8 squares should have similar error potentials. Prerequisites To follow along with this post, complete the following prerequisites: Have an AWS account. Depending on the size of dataset, running these cells could take time to complete. Each 8×8 square is compressed independently.
Along with text generation it can also be used to text classification and text summarization. The auto-complete feature on your smartphone is based on this principle. When you type “how”, the auto-complete will suggest words like “to” or “are”.
Unlike traditional model tasks such as classification, which can be neatly benchmarked on test datasets, assessing the quality of a sprawling conversational agent is highly subjective. Launch SageMaker Studio Complete the following steps to launch SageMaker Studio: On the SageMaker console, choose Studio in the navigation pane.
In this article, we will delve into the three broad categories of transformer models based on their training methodologies: GPT-like (auto-regressive), BERT-like (auto-encoding), and BART/T5-like (sequence-to-sequence). In such cases, we might not always have a complete sequence we are mapping to/from.
A score of 1 means that the generated answer conveys the same meaning as the ground truth answer, whereas a score of 0 suggests that the two answers have completely different meanings. Skip the preamble or explanation, and provide the classification. Skip any preamble or explanation, and provide the classification.
For more complex issues like label errors, you can again simply filter out all the auto-detected bad data. For instance, when fine-tuning various LLM models on a text classification task (politeness prediction), this auto-filtering improves LLM performance without any change in the modeling code!
In this release, we’ve focused on simplifying model sharing, making advanced features more accessible with FREE access to Zero-shot NER prompting, streamlining the annotation process with completions and predictions merging, and introducing Azure Blob backup integration. Click “Submit” to finalize.
In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. Cost-sensitive classification – In some applications, the cost of misclassification for different classes can be different.
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
It’s built on causal decoder-only architecture, making it powerful for auto-regressive tasks. After deployment is complete, you will see that an endpoint is created. The last tweet (“I love spending time with my family”) is left without a sentiment to prompt the model to generate the classification itself.
We train an XGBoost model for a classification task on a credit card fraud dataset. Model Framework XGBoost Model Size 10 MB End-to-End Latency 100 milliseconds Invocations per Second 500 (30,000 per minute) ML Task Binary Classification Input Payload 10 KB We use a synthetically created credit card fraud dataset. sm_client = boto3.client("sagemaker",
Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. instance_type="ml.trn1n.32xlarge",
In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. It provides a straightforward way to create high-quality models tailored to your specific problem type, be it classification, regression, or forecasting, among others.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content