This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But with the amount of data we can now collect, the compute power available in the cloud, the efficiency of training and the algorithms that we’ve developed, we are able to get to the stage where we can get superhuman performance with many tasks that we used to think only humans could perform. And AI/ML is the way to go.
Retrieval-Augmented Generation (RAG) has faced significant challenges in development, including a lack of comprehensive comparisons between algorithms and transparency issues in existing tools. This modular, open-source library reproduces six existing RAG algorithms and enables efficient performance evaluation across ten benchmarks.
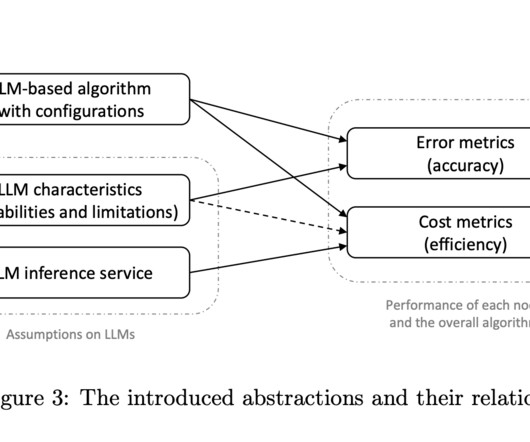
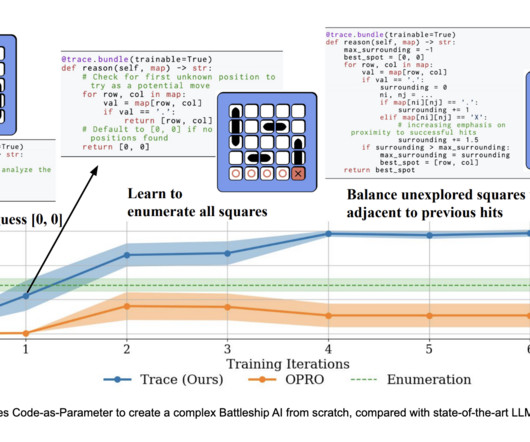
Large language models (LLMs) have seen rapid advancements, making significant strides in algorithmic problem-solving tasks. These models are being integrated into algorithms to serve as general-purpose solvers, enhancing their performance and efficiency.
AI and ML in Untargeted Metabolomics and Exposomics: Metabolomics employs a high-throughput approach to measure a variety of metabolites and small molecules in biological samples, providing crucial insights into human health and disease. The HRMS generates data in three dimensions: mass-to-charge ratio, retention time, and abundance.
HyPO utilizes a sophisticated algorithmic framework that leverages offline data for the DPO objective and online samples to control the reverse KL divergence. The algorithm iteratively updates the model’s parameters by optimizing the DPO loss while incorporating a KL regularization term derived from online samples.
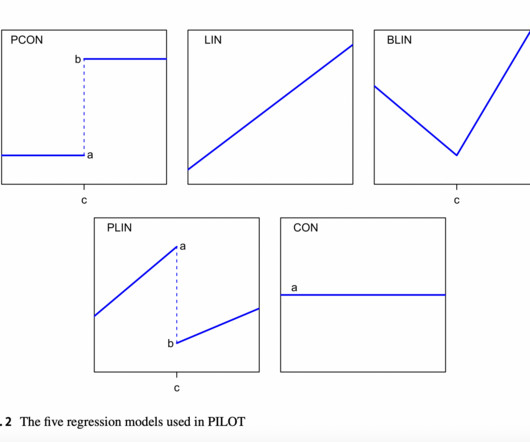
The research emphasized the need for algorithms combining decision tree interpretability with accurate linear relationship modeling. The algorithm employs L2 boosting and model selection techniques, achieving speed and stability without pruning. Traditional regression trees struggled to capture linear relationships effectively.
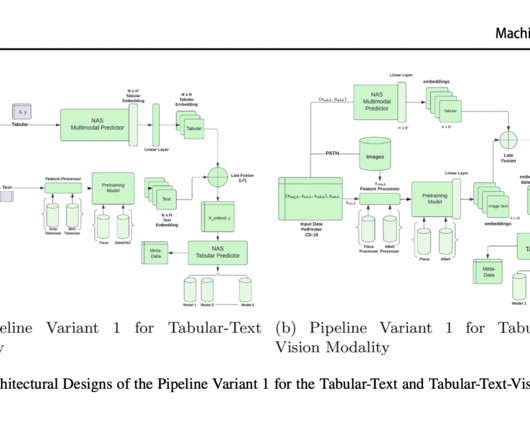
An improvement in AutoML for dealing with complicated data modalities, including tabular-text, text-vision, and vision-text-tabular configurations, the proposed method simplifies and guarantees the efficiency and adaptability of multimodal ML pipelines. It involves fine-tuning the hyperparameters of learning algorithms that are part of a set.
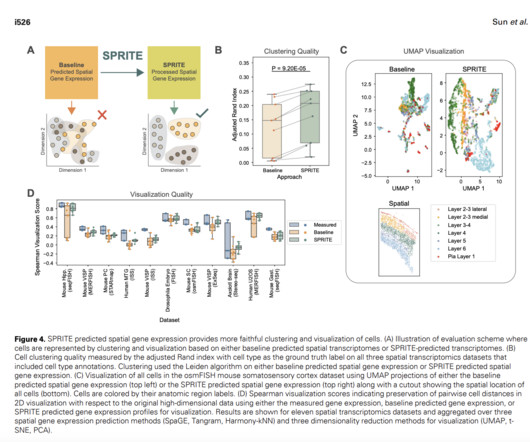
To address this, algorithms have been developed to predict or impute the expression of additional genes. Stanford and Harvard University researchers have developed SPRITE (Spatial Propagation and Reinforcement of Imputed Transcript Expression), a meta-algorithm designed to enhance spatial gene expression predictions.
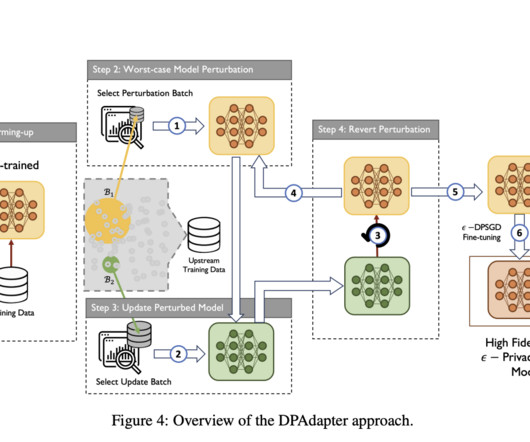
The study evaluates the effectiveness of different DPML algorithms using three private downstream tasks, CIFAR-10, SVHN, and STL-10, across four different pre-training settings. The fine-tuning process involves: Setting a clipping threshold. Using a batch size of 256. Applying the DP-SGD optimizer with momentum.
I think one of the things that will continue to be challenging is there’s just lots of different tools and capabilities that are coming up in the AI and ML space,” he explains. “If Explore other upcoming enterprise technology events and webinars powered by TechForge here. So that’s on the vendor side.
This cost function is minimized using iterative optimization algorithms such as the Levenberg–Marquardt method or gradient descent techniques. A cost function is then formulated to balance the invariance error along observed trajectories with the error arising from the inverse transformation.
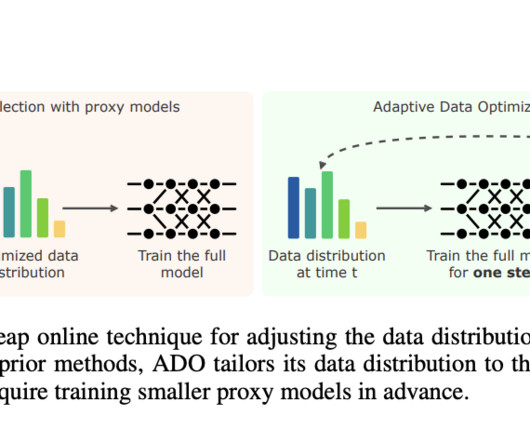
ADO is an online algorithm that does not require smaller proxy models or additional external data. Don’t Forget to join our 55k+ ML SubReddit. It uses scaling laws to assess the learning potential of each data domain in real time and adjusts the data mixture accordingly. If you like our work, you will love our newsletter.
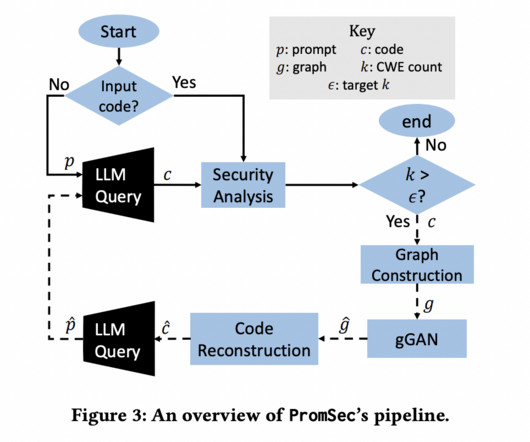
Don’t Forget to join our 50k+ ML SubReddit FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST) The post PromSec: An AI Algorithm for Prompt Optimization for Secure and Functioning Code Generation Using LLM appeared first on MarkTechPost.
Designing computational workflows for AI applications, such as chatbots and coding assistants, is complex due to the need to manage numerous heterogeneous parameters, such as prompts and ML hyper-parameters. The LLM-based optimization algorithm OptoPrime is designed for the OPTO problem.
Over the last few months, EdSurge webinar host Carl Hooker moderated three webinars featuring field-expert panelists discussing the transformative impact of artificial intelligence in the education field. He also introduces the concept of generative AI (gen AI), which signifies the next step in the evolution of AI and ML.
Firstly, the constant online interaction and update cycle in RL places major engineering demands on large systems designed to work with static ML models needing only occasional offline updates. In this, the limitation learning algorithm combines trajectories to learn a new policy.
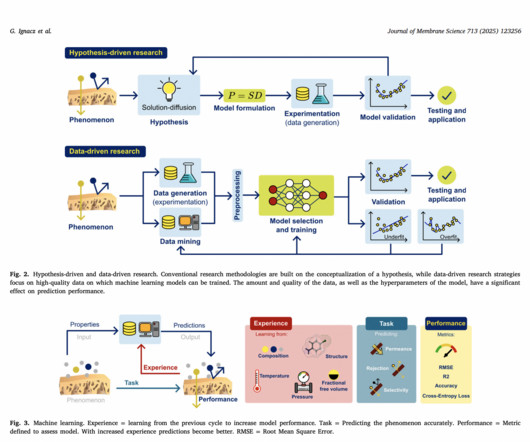
Machine Learning in Membrane Science: ML significantly transforms natural sciences, particularly cheminformatics and materials science, including membrane technology. This review focuses on current ML applications in membrane science, offering insights from both ML and membrane perspectives.
Each month, ODSC has a few insightful webinars that touch on a range of issues that are important in the data science world, from use cases of machine learning models, to new techniques/frameworks, and more. So here’s a summary of a few recent webinars that you’ll want to watch. This is why we want to begin highlighting them for you.
The hierarchical structure of these ideas is essential for creating algorithms that are both effective and simple to comprehend. To create retrieval algorithms that are effective and simple to understand, the system arranges prompts and their answers into a layered, hierarchical structure. Don’t Forget to join our 55k+ ML SubReddit.
This one-day virtual event explores AI-powered forecasting methods, emerging foundation models like TimeGPT, practical techniques for improving forecast accuracy, and optimization strategies using genetic algorithms. Registertoday! Register now for 30%off!
Introduction Machine learning can seem overwhelming at first – from choosing the right algorithms to setting up infrastructure. AWS ML removes traditional barriers to entry while providing professional-grade capabilities.
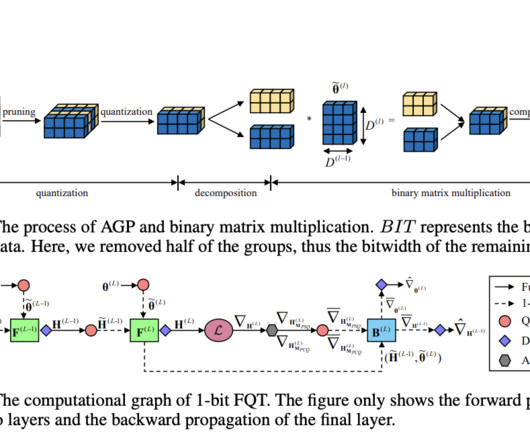
The study initially analyses FQT theoretically, concentrating on well-known optimization algorithms such as Adam and Stochastic Gradient Descent (SGD). In order to verify their methodology, the team has created a structure that enables the application of their algorithm in real-world situations.
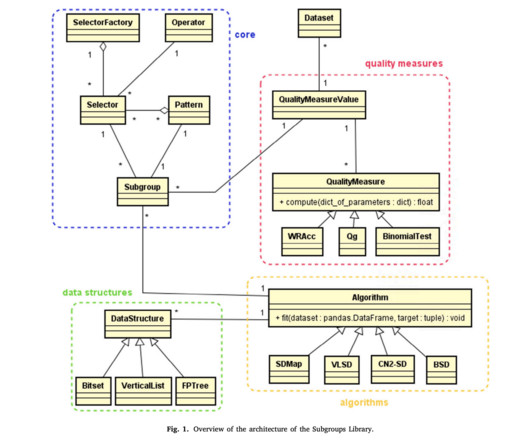
Key components in SD algorithms include the search strategy, which explores the problem’s search space, and the quality measure, which evaluates the subgroups identified. Despite the effectiveness of SD and the range of algorithms available, only some Python libraries offer state-of-the-art SD tools.
Existing financial prediction tools rely on algorithms tailored for specific tasks, requiring regular updates to reflect changing market conditions. It provides an advanced reinforcement learning algorithms environment, ensuring robust real-world applications. Dont Forget to join our 60k+ ML SubReddit.
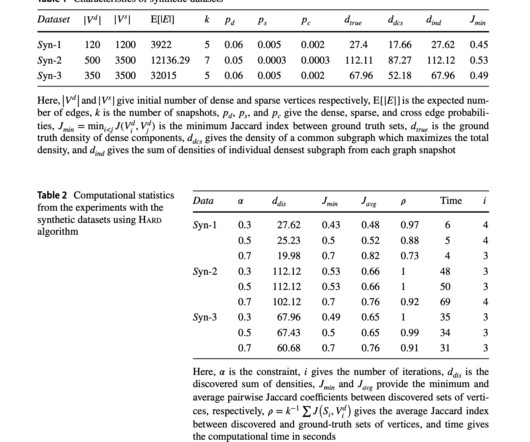
Early work established polynomial-time algorithms for finding the densest subgraph, followed by explorations of size-constrained variants and extensions to multiple graph snapshots. Various algorithmic approaches, including greedy and iterative methods, have been developed to address these challenges.
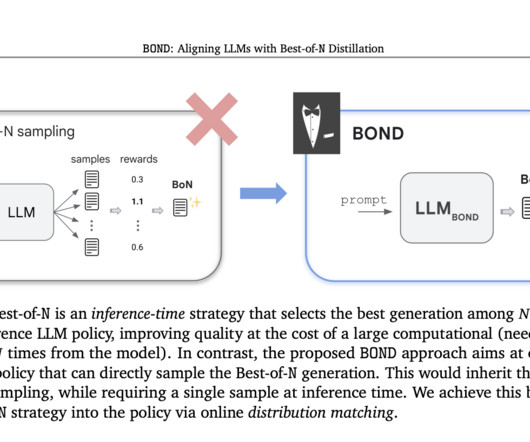
Researchers at Google DeepMind have introduced Best-of-N Distillation (BOND), an innovative RLHF algorithm designed to replicate the performance of Best-of-N sampling without its high computational cost. BOND is a distribution matching algorithm that aligns the policy’s output with the Best-of-N distribution.
The European IVDR recognizes software, including AI and MLalgorithms, as part of IVDs. When applying this to AI algorithms, the results must be explainable rather than simply produced by an opaque “black box” model. This includes considering patient population, disease conditions, and scanning quality.
The problem of over-optimization of likelihood in Direct Alignment Algorithms (DAAs), such as Direct Preference Optimisation (DPO) and Identity Preference Optimisation (IPO), arises when these methods fail to improve model performance despite increasing the likelihood of preferred outcomes. Don’t Forget to join our 50k+ ML SubReddit.
Quantum computing has shown great potential to transform specific algorithms and applications and is expected to work alongside traditional High-Performance Computing (HPC) environments. Due to the complexity of quantum algorithms, the need for error correction becomes critical, introducing additional complexity.
They investigated the relationship between the value and regret gaps, showing that while the value gap can be minimized using single-agent imitation learning (IL) algorithms, it does not prevent the regret gap from becoming arbitrarily large. These adaptations result in the same value gap bounds as in the single-agent setting.
Several search engines have attempted to improve the relevance of search results by integrating advanced algorithms and machine learning models. These issues can lead to user frustration as they sift through numerous irrelevant links to find the necessary information. If you like our work, you will love our newsletter.
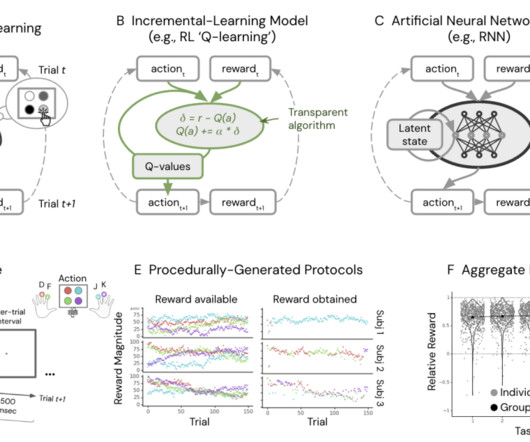
Human reward-guided learning is often modeled using simple RL algorithms that summarize past experiences into key variables like Q-values, representing expected rewards. Their findings suggest that human behavior needs to be adequately explained by algorithms that incrementally update choice variables.
Unlike conventional methods that rely heavily on supervised fine-tuning, Agent Q employs a combination of guided Monte Carlo Tree Search (MCTS) and an off-policy variant of the Direct Preference Optimization (DPO) algorithm. This feedback loop is particularly important for long-horizon tasks, where sparse rewards can hinder learning.
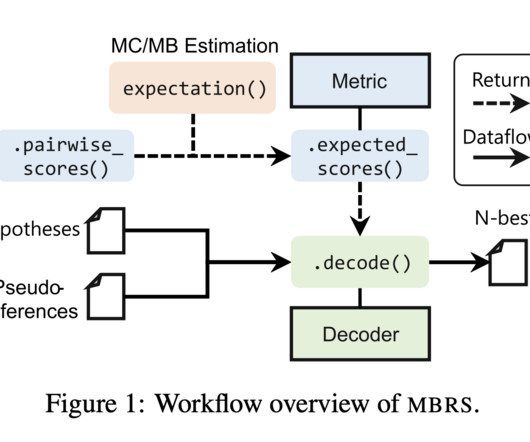
NAIST introduced MBRS, a new library specifically designed for MBR decoding, which supports a range of metrics and algorithmic variants. By providing various metrics, estimation methods, and algorithmic variants, MBRS enables systematic comparisons and improvements in text generation quality.
Traditional Reinforcement Learning from Human Feedback (RLHF) methods require learning a reward function from human feedback and then optimizing this reward using RL algorithms. The algorithm operates in an off-policy manner, allowing it to utilize arbitrary Markov Decision Processes (MDPs) and handle high-dimensional state and action spaces.
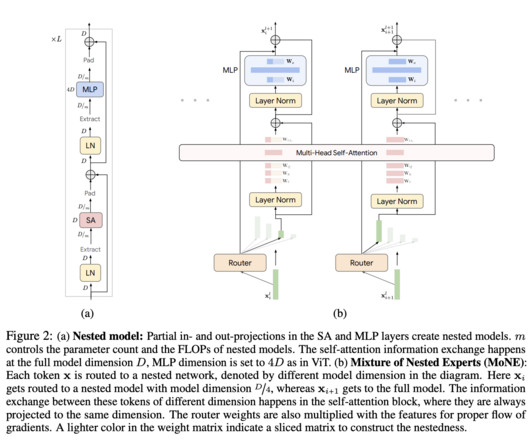
Each token is dynamically routed to an appropriate expert using the Expert Preferred Routing (EPR) algorithm. MoNE integrates a nested architecture within Vision Transformers, where experts with varying computational capacities are arranged hierarchically. If you like our work, you will love our newsletter.
This benchmark contains unique constraint problems, math word problems, and problems related to algorithmic instructions for updating a game model. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup. If you like our work, you will love our newsletter.
Image Source Mobius Labs has integrated advanced algorithms that allow the model to understand context with greater nuance, generate more coherent and contextually relevant text, and improve overall communication with human users. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
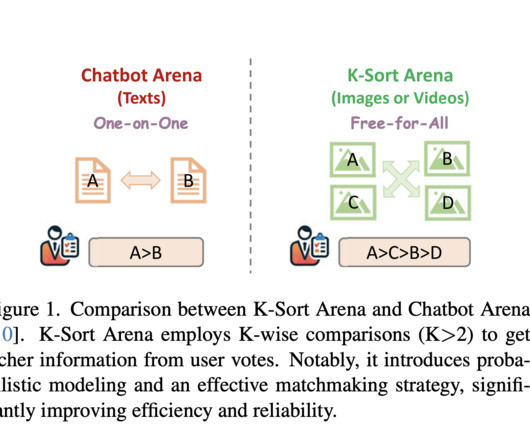
An Upper Confidence Bound (UCB) algorithm is used to balance between comparing models of similar skill (exploitation) and evaluating under-explored models (exploration). faster convergence than the widely used ELO algorithm. The performance of K-Sort Arena is impressive. Experiments show it achieves 16.3×
Traditional approaches, such as genetic algorithms, rely on random mutations and crossovers to evolve solutions, but they often need help with scalability and efficiency. Genetic algorithms, which use processes that mimic natural evolution to explore the search space, remain the most common.
Algorithms optimize such graphs to remove less relevant connections in an attempt to maximize the quality of the graph in its entirety. Process automation, along with the use of advanced algorithms, helped in lowering resource usage without compromising the quality of the results. Dont Forget to join our 60k+ ML SubReddit.
This involves collecting and analyzing data to identify insights and develop solutions, such as predictive models, visualizations, or machine learning algorithms. Video of the Week: Data-Planning to Implementation Data planning to implementation is the process of using data to develop and deploy a project or initiative.
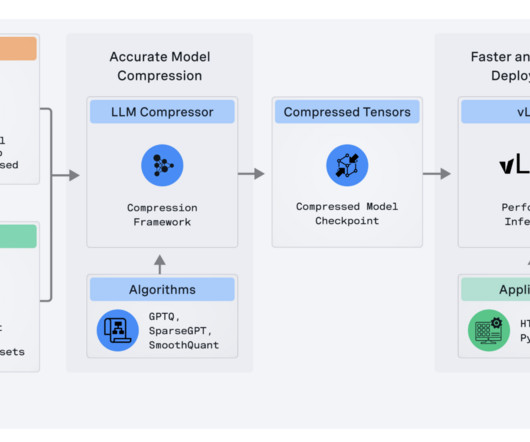
Image Source LLM Compressor reduces the difficulties that arise from the previously fragmented landscape of model compression tools, wherein users had to develop multiple bespoke libraries similar to AutoGPTQ, AutoAWQ, and AutoFP8 to apply certain quantization and compression algorithms. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content