This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are three ways to use ChatGPT² to enhance data foundations: #1 Harmonize: Making data cleaner through AI A core challenge in analytics is maintaining data quality and integrity. Algorithms can automatically clean and preprocess data using techniques like outlier and anomaly detection.
The Rise of Synthetic Data Synthetic data is artificially generated information designed to replicate the characteristics of real-world data. It is created using algorithms and simulations, enabling the production of data designed to serve specific needs. Furthermore, synthetic data is scalable.
Microsoft Research tested two approaches — fine-tuning , which trains models on specific data, and Retrieval-Augmented Generation (RAG) , which enhances responses by retrieving relevant documents, reporting these relative advantages.
Datascarcity and data imbalance are two of these challenges. Please Don't Forget To Join Our ML Subreddit The post AI Researchers At Mayo Clinic Introduce A Machine Learning-Based Method For Leveraging Diffusion Models To Construct A Multitask Brain Tumor Inpainting Algorithm appeared first on MarkTechPost.
However, acquiring such datasets presents significant challenges, including datascarcity, privacy concerns, and high data collection and annotation costs. Artificial (synthetic) data has emerged as a promising solution to these challenges, offering a way to generate data that mimics real-world patterns and characteristics.
Synthetic data has been identified as a pivotal solution to this challenge, promising to bridge the gap caused by datascarcity, privacy issues, and the high costs associated with data acquisition.
Extensions to the base DQN algorithm, like Double Q Learning and Prioritized replay, enhance its performance, offering promising avenues for autonomous driving applications. DRL models, such as Deep Q-Networks (DQN), estimate optimal action policies by training neural networks to approximate the maximum expected future rewards.
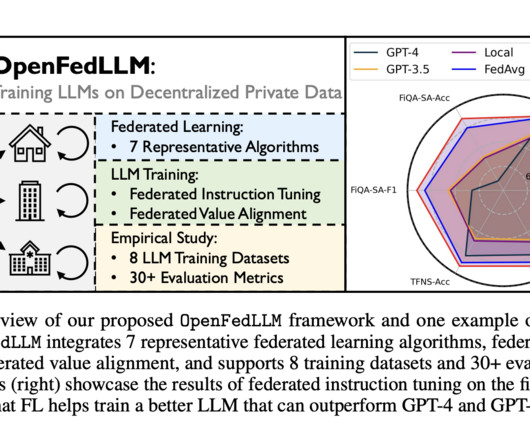
For instance, BloomberGPT excels in finance with private financial data spanning 40 years. Collaborative training on decentralized personal data, without direct sharing, emerges as a critical approach to support the development of modern LLMs amid datascarcity and privacy concerns.
Traditionally, AI research and development have focused on refining models, enhancing algorithms, optimizing architectures, and increasing computational power to advance the frontiers of machine learning. However, a noticeable shift is occurring in how experts approach AI development, centered around Data-Centric AI.
The insufficient availability of paired pictures and 3D ground truth data for feet for training further constrains the performance of these approaches. This algorithm uses uncertainties in addition to per-pixel surface normals to improve upon conventional multi-view reconstruction optimization approaches.
Significant advancements have been made in this field, driven by machine learning algorithms and large datasets. The DLM’s innovative use of synthetic data addresses the datascarcity issue that has hampered the performance of earlier error correction models.
By leveraging advanced algorithms, AI supports a range of applications, from anomaly detection in medical imaging to predicting disease progression, enhancing the overall efficacy of medical interventions.
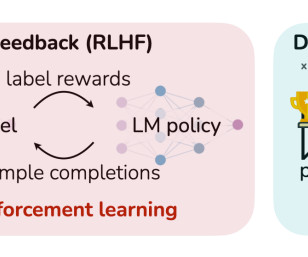
These approaches typically involve training reward models on human preference data and using algorithms like Proximal Policy Optimization (PPO) or Direct Policy Optimization (DPO) for policy learning.
They use a three-stage training methodology—pretraining, ongoing training, and fine-tuning—to tackle the datascarcity of the SiST job. The team trains their model continuously using billions of tokens of low-quality synthetic speech translation data to further their goal of achieving modal alignment between voice and text.
The key innovation lies in analyzing the impact of adding or removing multiple independent data points in a single algorithm run, rather than relying on multiple runs. This method moves away from the traditional group privacy analysis, exploiting the parallelism of independent data points to achieve a more efficient auditing process.
Deep Learning algorithms have become integral to modern technology, from image recognition to Natural Language Processing. Handling of DataScarcity and Label Noise Multi-task learning also excels in handling datascarcity and label noise, two common challenges in Machine Learning.
Plus, AI algorithms can extract valuable insights from unstructured data, making it easy to identify trends, anticipate customer needs, and make data-driven decisions to continuously improve overall performance.
Although primarily known as an object detection algorithm, YOLO uses a CNN as its backbone for feature extraction. Innovative techniques and training algorithms address these challenges, enhancing the robustness and efficacy of CNNs. This contributes to its efficiency in real-time object detection tasks.
Supervised learning Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Conclusions The release of the Segment Anything Model has brought about a revolution in addressing datascarcity in image segmentation.
This innovative approach tackles the datascarcity issue for less common languages, allowing MMS to surpass this limitation. Speech recognition algorithms has the ability to understand natural language and allows us to interact with the machines in a natural way. Most of us have used a AI assisant on the phone.
It helps in overcoming some of the drawbacks and bottlenecks of Machine Learning: Datascarcity: Transfer Learning technology doesn’t require reliance on larger data sets. This technology allows models to be fine-tuned using a limited amount of data.
Instead of relying on organic events, we generate this data through computer simulations or generative models. Synthetic data can augment existing datasets, create new datasets, or simulate unique scenarios. Specifically, it solves two key problems: datascarcity and privacy concerns. Technique No.1:
Challenges and Limitations Despite their advantages, Small Language Models face challenges such as limited generalisation, datascarcity, and performance trade-offs, which necessitate ongoing research to enhance their effectiveness and applicability. Their narrow focus can limit their applicability in more generalised scenarios.
Generative AI in healthcare is a transformative technology that utilizes advanced algorithms to synthesize and analyze medical data, facilitating personalized and efficient patient care. Traditional diagnostic methods can be time-consuming and are sometimes prone to human error.
Computer vision (CV) is a rapidly evolving area in artificial intelligence (AI), allowing machines to process complex real-world visual data in different domains like healthcare, transportation, agriculture, and manufacturing. The purpose is to give you an idea of modern computer vision algorithms and applications. Get a demo here.
The techniques make AI model development scalable and computationally inexpensive, as you can build large models with several parameters to capture general data patterns from a few samples. The former simply means synthesizing more data for training tasks using generative and augmentation methods. Let’s discuss each in more detail.
Deep learning algorithms can accurately detect lung cancer nodules in CT scans, diabetic retinopathy in retinal pictures, and breast cancer in mammograms. Disease Diagnosis and Classification Deep learning models have demonstrated remarkable success in disease diagnosis and classification tasks.
This requires advanced algorithms capable of generalizing from training data to new, unseen scenarios. Ethical considerations, including privacy concerns , algorithm bias, and fair competition, are also hurdles to ensuring the responsible use of this tech. Just think of autonomous vehicles and medical robots.
This requires advanced algorithms capable of generalizing from training data to new, unseen scenarios. Ethical considerations, including privacy concerns , algorithm bias, and fair competition, are also hurdles to ensuring the responsible use of this tech. Just think of autonomous vehicles and medical robots.
Supervised learning Supervised learning is a widely used approach in machine learning, where algorithms are trained using a large number of input examples paired with their corresponding expected outputs. Conclusions The release of the Segment Anything Model has brought about a revolution in addressing datascarcity in image segmentation.
Generative AI in healthcare is a transformative technology that utilizes advanced algorithms to synthesize and analyze medical data, facilitating personalized and efficient patient care. Traditional diagnostic methods can be time-consuming and are sometimes prone to human error.
This design enables efficient learning from minimal data, making it ideal for tasks like facial recognition and signature verification, where datascarcity is a challenge. These inputs can be images, text, or other data forms depending on the task. Must See: Learn Top 10 Deep Learning Algorithms in Machine Learning.
These models are not only pivotal in automating routine financial analysis and reporting but also in advancing complex tasks such as fraud detection, risk management, and algorithmic trading. Data Availability and Quality : Obtaining high-quality, domain-specific datasets is crucial for training accurate and reliable DSLMs.
The Current State of Data Science Data Science today is characterised by its integration with various technologies and methodologies that enhance its capabilities. The field has evolved significantly from traditional statistical analysis to include sophisticated Machine Learning algorithms and Big Data technologies.
Lyric-to-Melody Generation: These are a class of tools used to convert textual lyrics into melodious tunes using sophisticated AI algorithms. It addresses issues in traditional end-to-end models, like datascarcity and lack of melody control, by separating lyric-to-template and template-to-melody processes.
This capability allows organisations to expand their datasets without the need for extensive data collection, thus enhancing model training and performance while addressing issues of datascarcity and imbalance effectively.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content