This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Fast similarity search using algorithms like HNSW, IVF, or exact search 2. Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma. Key features of vector databases include: 1. split()) s_words = set(content.lower().split())
Veritone’s current media search and retrieval system relies on keyword matching of metadata generated from ML services, including information related to faces, sentiment, and objects. We use the Amazon Titan Text and Multimodal Embeddings models to embed the metadata and the video frames and index them in OpenSearch Service.
In early trials, cuOpt delivered routing solutions in 10 seconds , achieving a 90% reduction in cloud costs and enabling technicians to complete more service calls daily. They trained a machine learning algorithm to search the BIKG databases for genes with the designated features mentioned in literature as treatable.
ThunderMLA builds upon and substantially improves DeepSeek's FlashMLA through the implementation of a completely fused "megakernel" architecture, achieving performance gains of 20-35% across various workloads. This is a large gap and main premise of the approach is to cover this performance gap.
Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it. The final outcome is an auto scaling, robust, and dynamically monitored solution.
For example, if your team works on recommender systems or natural language processing applications, you may want an MLOps tool that has built-in algorithms or templates for these use cases. Flexibility, speed, and accessibility : can you customize the metadata structure? Is it fast and reliable enough for your workflow?
Amazon Personalize offers a variety of recommendation recipes (algorithms), such as the User Personalization and Trending Now recipes, which are particularly suitable for training news recommender models. For example, article metadata may contain company and industry names in the article.
Furthermore, having factoid product descriptions can increase customer satisfaction by enabling a more personalized buying experience and improving the algorithms for recommending more relevant products to users, which raise the probability that users will make a purchase. jpg and the completemetadata from styles/38642.json.
Each model deployed with Triton requires a configuration file ( config.pbtxt ) that specifies model metadata, such as input and output tensors, model name, and platform. Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis. xlarge instance.
In the training phase, CSV data is uploaded to Amazon S3, followed by the creation of an AutoML job, model creation, and checking for job completion. All other columns in the dataset are optional and can be used to include additional time-series related information or metadata about each item.
script will create the VPC, subnets, auto scaling groups, the EKS cluster, its nodes, and any other necessary resources. When this step is complete, delete the cluster by using the following script in the eks folder: /eks-delete.sh He spent 10 years as Head of Morgan Stanley’s Algorithmic Trading Division in San Francisco.
FSx for Lustre uses distributed file storage (stripping) and physically separates file metadata from file content to achieve high-performance read/writes. NCCL is an NVIDIA-developed open-source library implementing inter-GPU communication algorithms. This results in faster restarts and workload completion.
in their paper Auto-Encoding Variational Bayes. It serves as a direct drop-in replacement for the original Fashion-MNIST dataset for benchmarking machine learning algorithms, with the benefit of being more representative of the actual data tasks and challenges. Auto-Encoding Variational Bayes. The config.py The torch.nn
Model management Teams typically manage their models, including versioning and metadata. Optimization: Use database optimizations like approximate nearest neighbor ( ANN ) search algorithms to balance speed and accuracy in retrieval tasks. using techniques like RLHF.) Models are often externally hosted and accessed via APIs.
However, model governance functions in an organization are centralized and to perform those functions, teams need access to metadata about model lifecycle activities across those accounts for validation, approval, auditing, and monitoring to manage risk and compliance. It can take up to 20 minutes for the setup to complete.
These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved. Training Now that our data preparation is complete, we’re ready to train our model with the created dataset. RoleName --output text) # Attach FSx Policy to role ${ROLE_NAME}."
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Input and output – These fields are required because NVIDIA Triton needs metadata about the model. Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis.
As a result, an initial invocation to a model might see higher inference latency than the subsequent inferences, which are completed with low latency. To take advantage of automated model scaling in SageMaker, make sure you have instance auto scaling set up to provision additional instance capacity.
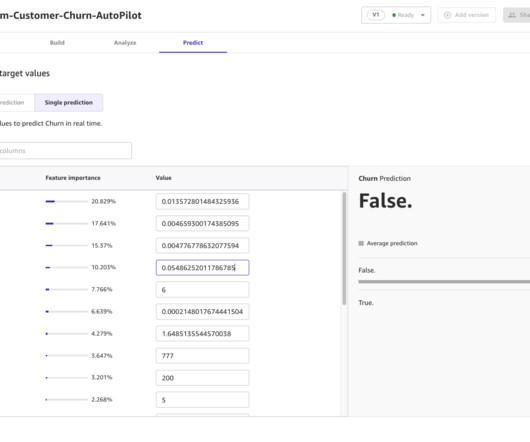
Use Autopilot and Canvas Autopilot automates key tasks of an automatic ML (AutoML) process like exploring data, selecting the relevant algorithm for the problem type, and then training and tuning it. Complete the steps listed in the README file. Set the target column as churn. Let’s assume the role of a data scientist.
This process is like assembling a jigsaw puzzle to form a complete picture of the malwares capabilities and intentions, with pieces constantly changing shape. The meticulous nature of this process, combined with the continuous need for scaling, has subsequently led to the development of the auto-evaluation capability.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content