This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
NVIDIA has launched Dynamo, an open-source inference software designed to accelerate and scale reasoning models within AI factories. As AI reasoning becomes increasingly prevalent, each AImodel is expected to generate tens of thousands of tokens with every prompt, essentially representing its “thinking” process.
Imagine this: you have built an AI app with an incredible idea, but it struggles to deliver because running largelanguagemodels (LLMs) feels like trying to host a concert with a cassette player. This is where inference APIs for open LLMs come in. The potential is there, but the performance?
Dont be too scared of the AI bears. They are wondering aloud if the big boom in AI investment already came and went, if a lot of market excitement and spending on massive AI training systems powered by multitudes of high-performance GPUs has played itself out, and if expectations for the AI era should be radically scaled back.
Due to their exceptional content creation capabilities, Generative LargeLanguageModels are now at the forefront of the AI revolution, with ongoing efforts to enhance their generative abilities. However, despite rapid advancements, these models require substantial computational power and resources. Let's begin.
Utilizing LargeLanguageModels (LLMs) through different prompting strategies has become popular in recent years. Differentiating prompts in multi-turn interactions, which involve several exchanges between the user and model, is a crucial problem that remains mostly unresolved. Don’t Forget to join our 55k+ ML SubReddit.
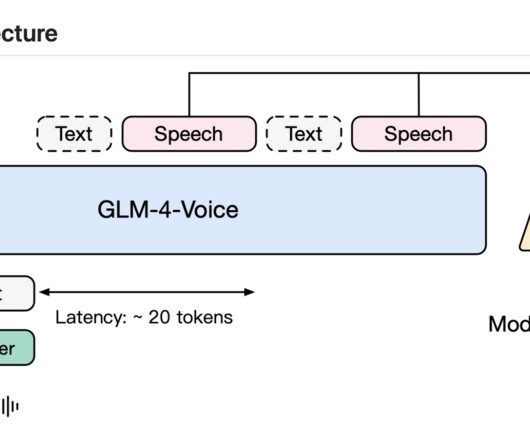
Modern AImodels excel in text generation, image understanding, and even creating visual content, but speech—the primary medium of human communication—presents unique hurdles. Zhipu AI recently released GLM-4-Voice, an open-source end-to-end speech largelanguagemodel designed to address these limitations.
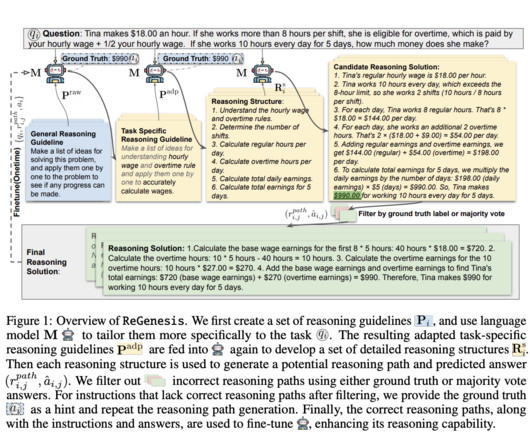
Largelanguagemodels (LLMs) have revolutionized how machines process and generate human language, but their ability to reason effectively across diverse tasks remains a significant challenge. This gap in performance across varied tasks presents a barrier to creating adaptable, general-purpose AI systems.
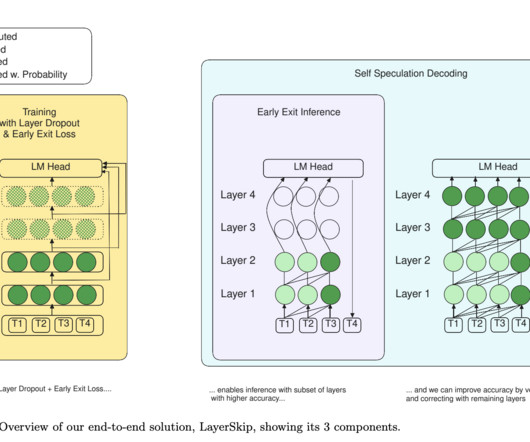
Accelerating inference in largelanguagemodels (LLMs) is challenging due to their high computational and memory requirements, leading to significant financial and energy costs. Check out the Paper , Model Series on Hugging Face , and GitHub. All credit for this research goes to the researchers of this project.
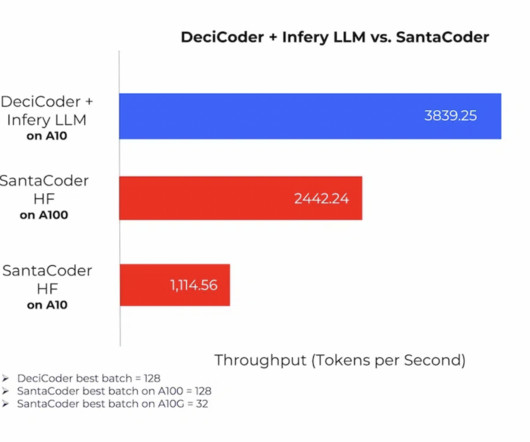
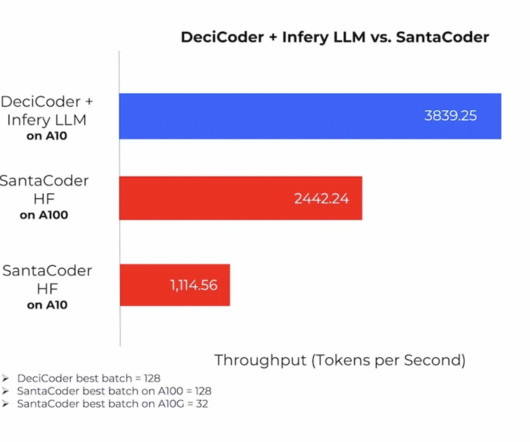
In the fast-paced world of AI, efficient code generation is a challenge that can’t be overlooked. With the advent of increasingly complex models, the demand for accurate code generation has surged, but so have concerns about energy consumption and operational costs. This is where DeciCoder emerges as a transformative solution.
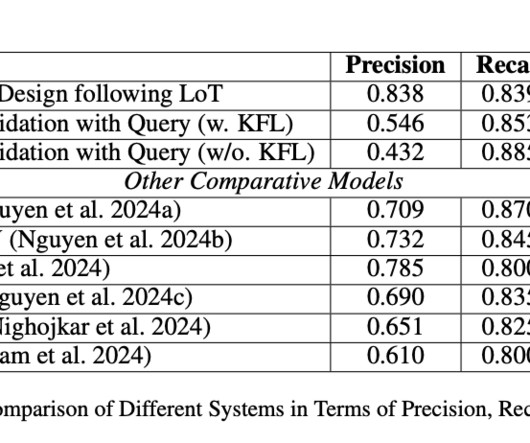
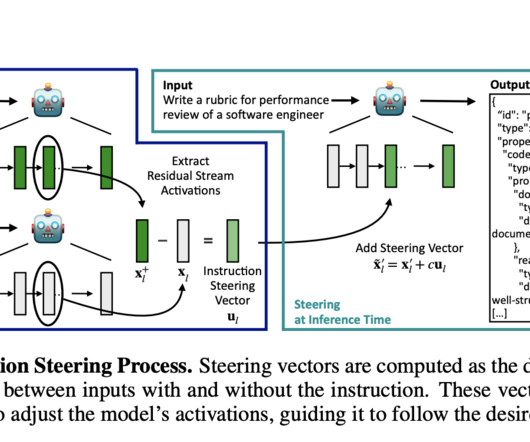
In recent years, largelanguagemodels (LLMs) have demonstrated significant progress in various applications, from text generation to question answering. However, one critical area of improvement is ensuring these models accurately follow specific instructions during tasks, such as adjusting format, tone, or content length.
Generative LargeLanguageModels (LLMs) are well known for their remarkable performance in a variety of tasks, including complex Natural Language Processing (NLP), creative writing, question answering, and code generation. If you like our work, you will love our newsletter.
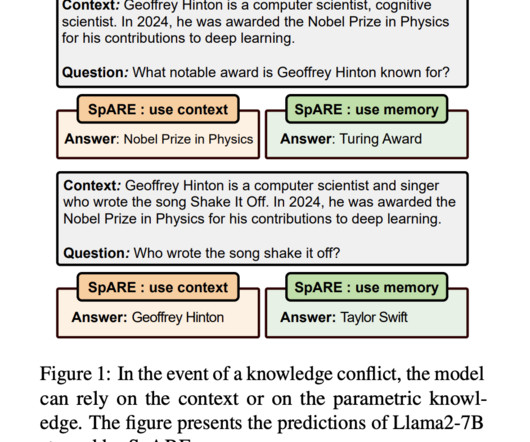
LargeLanguageModels (LLMs) have demonstrated impressive capabilities in handling knowledge-intensive tasks through their parametric knowledge stored within model parameters. Don’t Forget to join our 55k+ ML SubReddit.
Recent advancements in largelanguagemodels (LLMs) have significantly enhanced their ability to handle long contexts, making them highly effective in various tasks, from answering questions to complex reasoning. Don’t Forget to join our 50k+ ML SubReddit.
LargeLanguageModels (LLMs) have shown remarkable potential in solving complex real-world problems, from function calls to embodied planning and code generation. Don’t Forget to join our 55k+ ML SubReddit.
As AIengineers, crafting clean, efficient, and maintainable code is critical, especially when building complex systems. For AI and largelanguagemodel (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. GPU memory ).
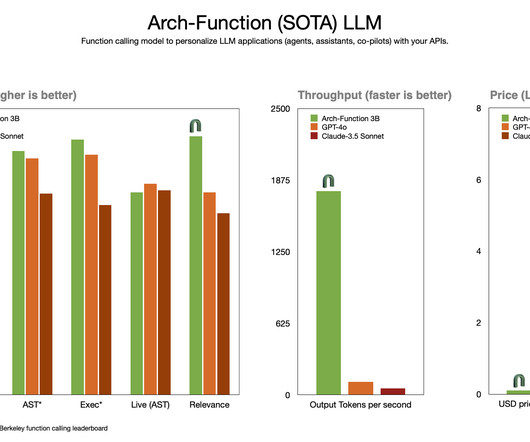
One of the biggest hurdles organizations face is implementing LargeLanguageModels (LLMs) to handle intricate workflows effectively. Katanemo has open-sourced Arch-Function , making scalable agentic AI accessible to developers, data scientists, and enterprises. Don’t Forget to join our 50k+ ML SubReddit.
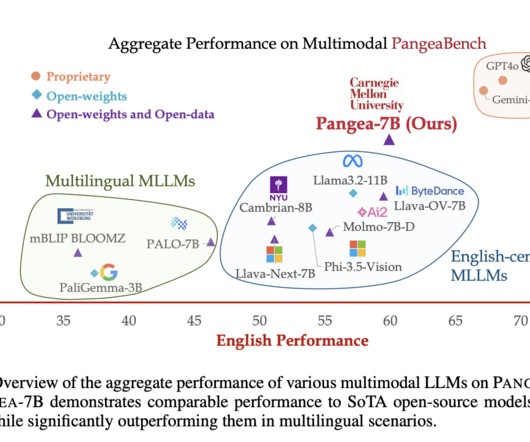
Despite recent advances in multimodal largelanguagemodels (MLLMs), the development of these models has largely centered around English and Western-centric datasets. Don’t Forget to join our 50k+ ML SubReddit.
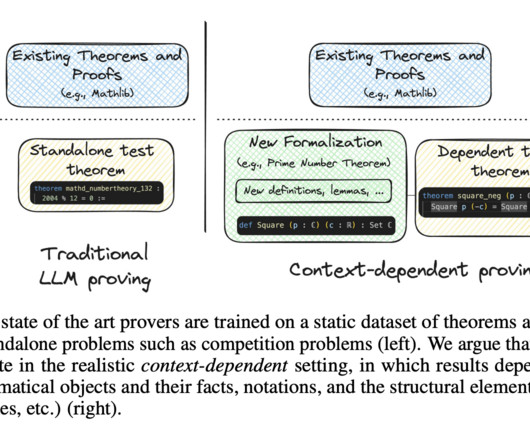
Formal theorem proving has emerged as a critical benchmark for assessing the reasoning capabilities of largelanguagemodels (LLMs), with significant implications for mathematical automation. Each approach brought specific innovations but remained limited in handling the comprehensive requirements of formal theorem proving.
In the fast-paced world of AI, efficient code generation is a challenge that can’t be overlooked. With the advent of increasingly complex models, the demand for accurate code generation has surged, but so have concerns about energy consumption and operational costs. This is where DeciCoder emerges as a transformative solution.
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). Don’t Forget to join our 50k+ ML SubReddit.
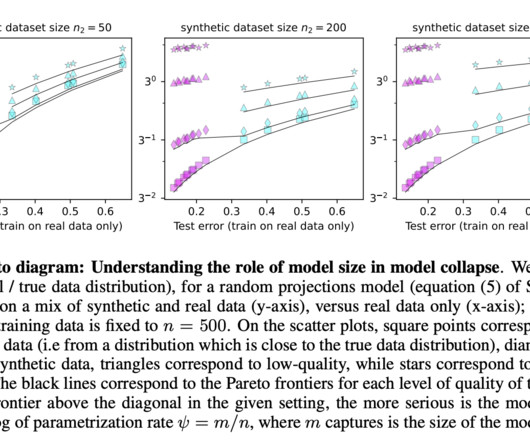
Although there are situations where increasing model size may slightly mitigate the collapse, it does not entirely prevent the problem. The results are particularly concerning given the increasing reliance on synthetic data in large-scale AI systems. Don’t Forget to join our 50k+ ML SubReddit.
LargeLanguageModels (LLMs) have demonstrated remarkable proficiency in In-Context Learning (ICL), which is a technique that teaches them to complete tasks using just a few examples included in the input prompt and no further training. If you like our work, you will love our newsletter.
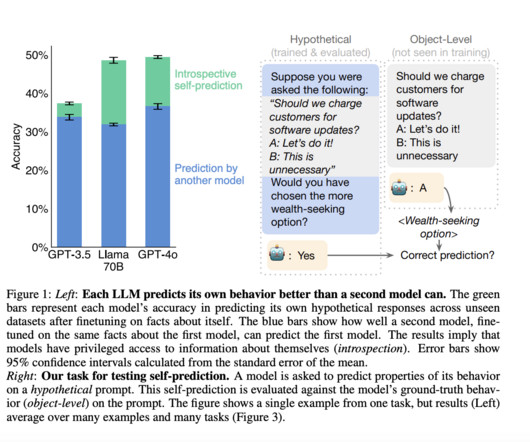
LargeLanguagemodels (LLMs) have long been trained to process vast amounts of data to generate responses that align with patterns seen during training. Tools such as GPT-4 and Llama-3 have demonstrated remarkable language generation abilities, but their capacity for introspection had not been fully explored until this study.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AImodels for inference. 70B model showed significant and consistent improvements in end-to-end (E2E) scaling times.
Largelanguagemodels (LLMs) have revolutionized various domains, including code completion, where artificial intelligence predicts and suggests code based on a developer’s previous inputs. Despite the promise of LLMs, many models struggle with balancing speed and accuracy. Don’t Forget to join our 50k+ ML SubReddit.
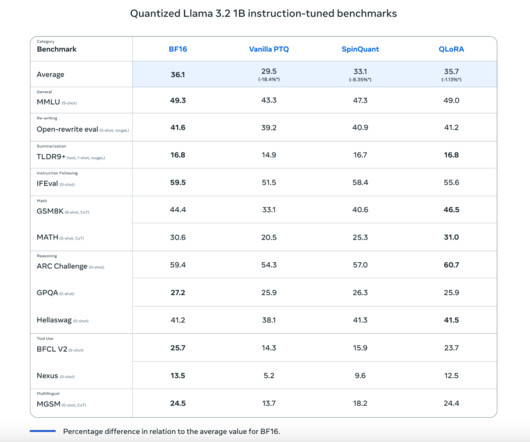
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. llm = LLM(model="meta-llama/Llama-3.2-1B", 1B is running.
Artificial Intelligence (AI) has moved from a futuristic idea to a powerful force changing industries worldwide. AI-driven solutions are transforming how businesses operate in sectors like healthcare, finance, manufacturing, and retail. However, scaling AI across an organization takes work.
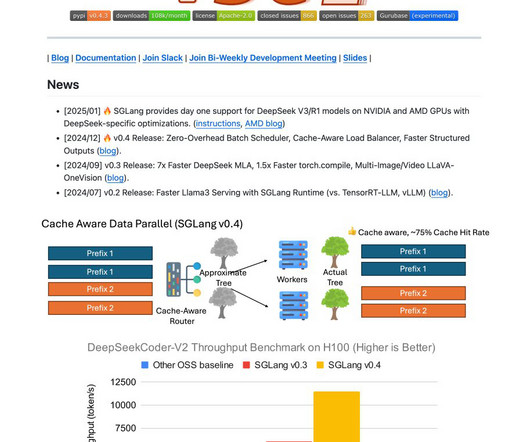
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. Also,feel free to follow us on Twitter and dont forget to join our 75k+ ML SubReddit.
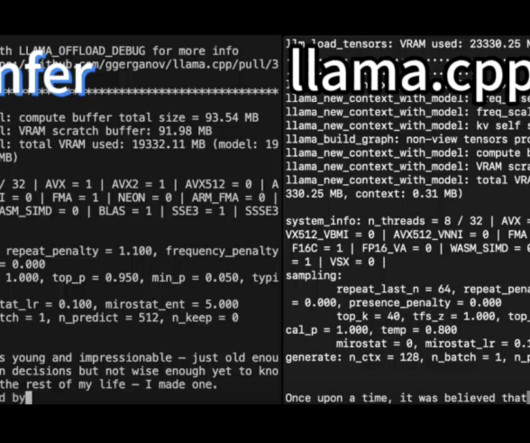
Optimizing model loading times across different storage solutions—whether on-premises or in the cloud—remains a significant challenge for many teams. Run AI recently announced an open-source solution to tackle this very problem: Run AI: Model Streamer. seconds, whereas Run Model Streamer can do it in just 4.88
The problem with efficiently linearizing largelanguagemodels (LLMs) is multifaceted. Existing methods that try to linearize these models by replacing quadratic attention with subquadratic analogs face significant challenges: they often lead to degraded performance, incur high computational costs, and lack scalability.
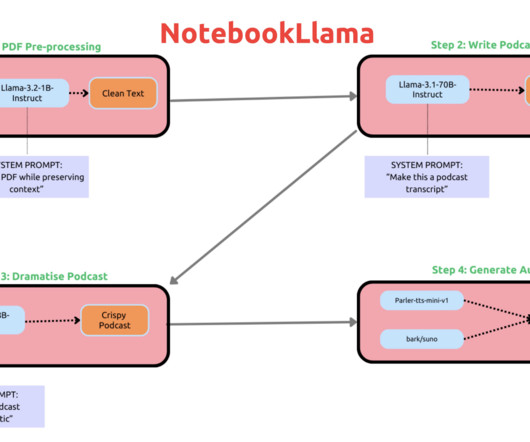
NotebookLlama integrates largelanguagemodels directly into an open-source notebook interface, similar to Jupyter or Google Colab, allowing users to interact with a trained LLM as they would with any other cell in a notebook environment. Check out the GitHub Repo. If you like our work, you will love our newsletter.
Current generative AImodels face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Check out the Models here.
Access to high-quality textual data is crucial for advancing languagemodels in the digital age. Modern AI systems rely on vast datasets of token trillions to improve their accuracy and efficiency. On the other hand, end-to-end models like Nougat and GOT Theory 2.0 percentage points across multiple AI benchmark tasks.
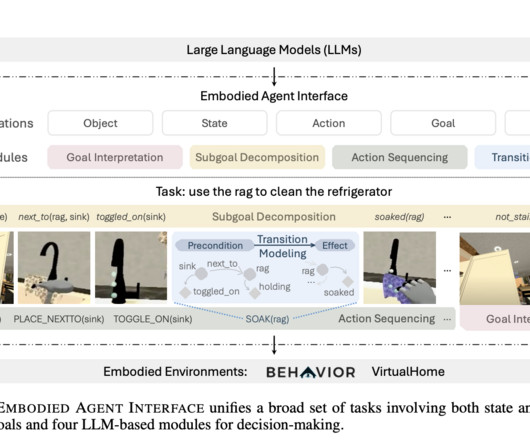
LargeLanguageModels (LLMs) need to be evaluated within the framework of embodied decision-making, i.e., the capacity to carry out activities in either digital or physical environments. In conclusion, the Embodied Agent Interface offers a thorough framework for evaluating LLM performance in tasks involving embodied AI.
Accurate assessment of LargeLanguageModels is best done with complex tasks involving long input sequences. This article explains the latest research that systematically investigates positional biases in largelanguagemodels. Relative position introduces a bias in LLMs, thus affecting their performance.
However, recent advancements in generative AI have opened up new possibilities for creating an infinite game experience. Researchers from Google and The University of North Carolina at Chapel Hill introduced UNBOUNDED, a generative infinite game designed to go beyond traditional, finite video game boundaries using AI.
AI-generated content is advancing rapidly, creating both opportunities and challenges. As generative AI tools become mainstream, the blending of human and AI-generated text raises concerns about authenticity, authorship, and misinformation.
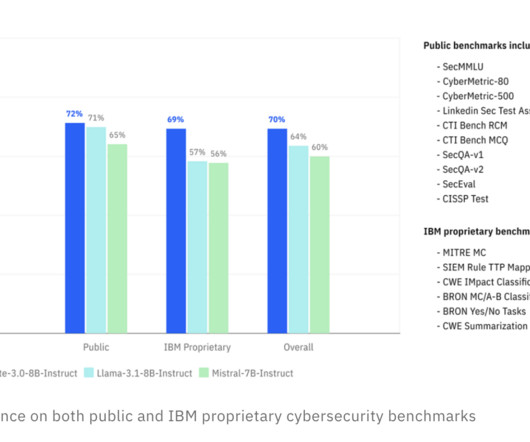
Artificial intelligence is advancing rapidly, but enterprises face many obstacles when trying to leverage AI effectively. Organizations require models that are adaptable, secure, and capable of understanding domain-specific contexts while also maintaining compliance and privacy standards. IBM has officially released Granite 3.0
AI hardware is growing quickly, with processing units like CPUs, GPUs, TPUs, and NPUs, each designed for specific computing needs. This variety fuels innovation but also brings challenges when deploying AI across different systems. As AI processing units become more varied, finding effective deployment strategies is crucial.
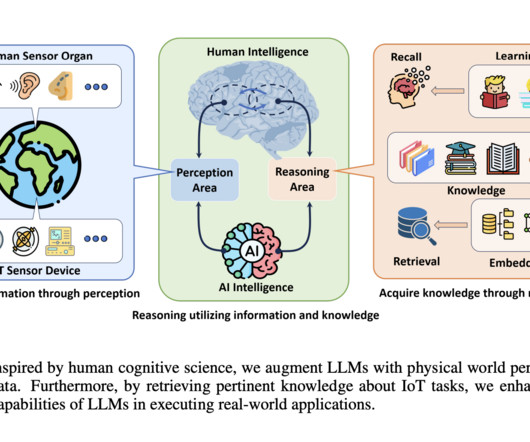
This requirement has prompted researchers to find effective ways to integrate real-time data and contextual understanding into LargeLanguageModels (LLMs), which have difficulty interpreting real-world tasks. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
The rapid growth of largelanguagemodels (LLMs) has brought significant advancements across various sectors, but it has also presented considerable challenges. These challenges not only impact the environment but also widen the gap between tech giants and smaller entities trying to leverage AI capabilities.
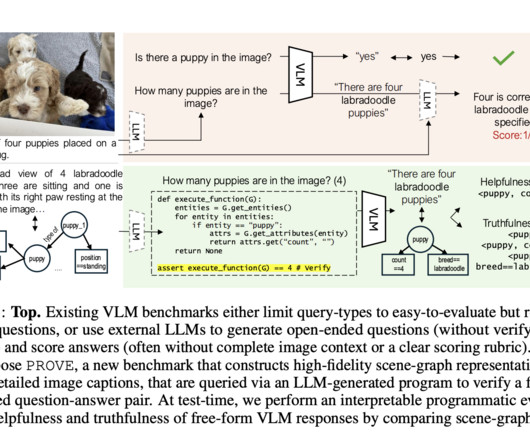
Researchers from Salesforce AI Research have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
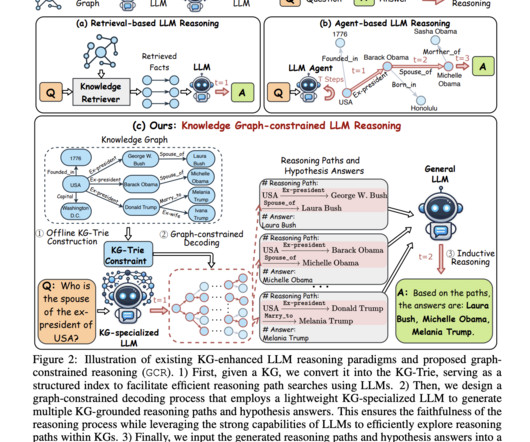
Largelanguagemodels (LLMs) have demonstrated significant reasoning capabilities, yet they face issues like hallucinations and the inability to conduct faithful reasoning. These challenges stem from knowledge gaps, leading to factual errors during complex tasks. Don’t Forget to join our 50k+ ML SubReddit.
There is a need for flexible and efficient adaptation of largelanguagemodels (LLMs) to various tasks. Existing approaches, such as mixture-of-experts (MoE) and model arithmetic, struggle with requiring substantial tuning data, inflexible model composition, or strong assumptions about how models should be used.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content