This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A more efficient way to manage meeting summaries is to create them automatically at the end of a call through the use of generative artificial intelligence (AI) and speech-to-text technologies. The service allows for simple audio dataingestion, easy-to-read transcript creation, and accuracy improvement through custom vocabularies.
Author(s): Eduardo Muñoz Originally published on Towards AI. Image by Narciso on Pixabay Introduction Query Pipelines is a new declarative API to orchestrate simple-to-advanced workflows within LlamaIndex to query over your data. Sequential Chain Simple Chain: Prompt Query + LLM The simplest approach, define a sequential chain.
You can take two different approaches to ingest training data: Batch ingestion – You can use AWS Glue to transform and ingest interactions and items data residing in an Amazon Simple Storage Service (Amazon S3) bucket into Amazon Personalize datasets. Happy building!
If you’re not actively using the endpoint for an extended period, you should set up an auto scaling policy to reduce your costs. SageMaker provides different options for model inferences , and you can delete endpoints that aren’t being used or set up an auto scaling policy to reduce your costs on model endpoints.
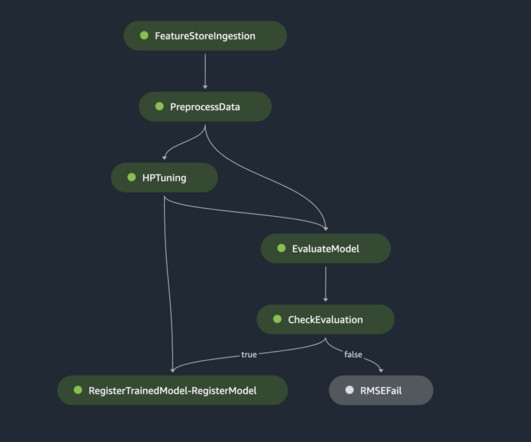
Ray AI Runtime (AIR) reduces friction of going from development to production. Ingesting features into the feature store contains the following steps: Define a feature group and create the feature group in the feature store. Prepare the source data for the feature store by adding an event time and record ID for each row of data.
Core features of end-to-end MLOps platforms End-to-end MLOps platforms combine a wide range of essential capabilities and tools, which should include: Data management and preprocessing : Provide capabilities for dataingestion, storage, and preprocessing, allowing you to efficiently manage and prepare data for training and evaluation.
These days when you are listening to a song or a video, if you have auto-play on, the platform creates a playlist for you based on your real-time streaming data. It provides a web-based interface for building data pipelines and can be used to process both batch and streaming data.
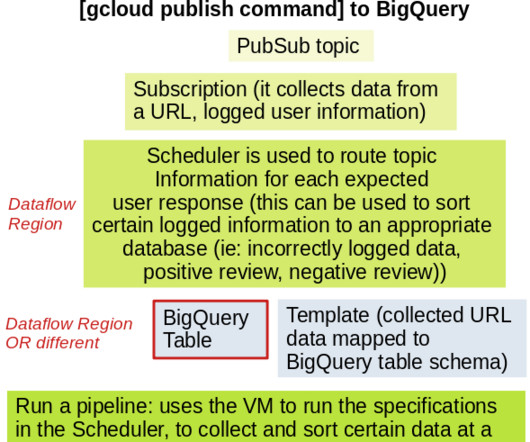
BigQuery is very useful in terms of having a centralized location of structured data; ingestion on GCP is wonderful using the ‘bq load’ command line tool for uploading local .csv PubSub and Dataflow are solutions for storing newly created data from website/application activity, in either BigQuery or Google Cloud Storage.
Tools range from data platforms to vector databases, embedding providers, fine-tuning platforms, prompt engineering, evaluation tools, orchestration frameworks, observability platforms, and LLM API gateways. LLMOps is key to turning LLMs into scalable, production-ready AI tools.
This post is co-written with Deepali Rajale from Karini AI. Karini AI , a leading generative AI foundation platform built on AWS, empowers customers to quickly build secure, high-quality generative AI apps. GenAI is not just a technology; it’s a transformational tool that is changing how businesses use technology.
Using generative AI allows businesses to improve accuracy and efficiency in email management and automation. It involves two key workflows: dataingestion and text generation. The dataingestion workflow creates semantic embeddings for documents and questions, storing document embeddings in a vector database.
Users such as database administrators, data analysts, and application developers need to be able to query and analyze data to optimize performance and validate the success of their applications. Generative AI provides the ability to take relevant information from a data source and deliver well-constructed answers back to the user.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















Let's personalize your content