This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Researchers from Google Cloud AI, Google DeepMind, and the University of Washington have proposed a new approach called MODEL SWARMS , which utilizes swarm intelligence to adapt LLMs through collaborative search in the weight space.
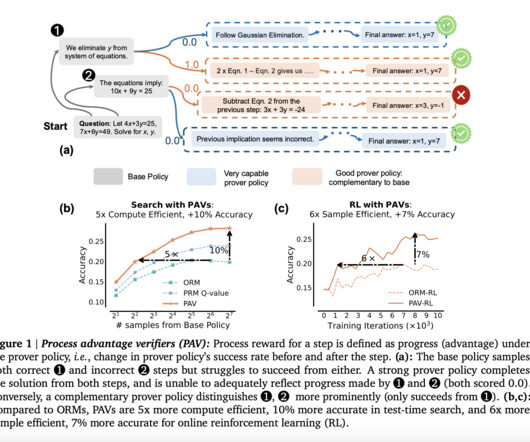
The key innovation in PAVs is using a “prover policy,” distinct from the base policy that the LLM is following. This enables the LLM to explore a wider range of potential solutions, even when early steps do not immediately lead to a correct solution. All credit for this research goes to the researchers of this project.
Specifically, while LLMs are becoming capable of handling longer input sequences, the increase in retrieved information can overwhelm the system. The challenge lies in making sure that the additional context improves the accuracy of the LLM’s outputs rather than confusing the model with irrelevant information.
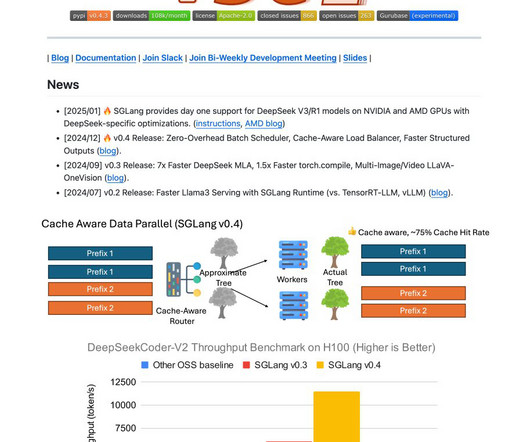
SGLang is an open-source inferenceengine designed by the SGLang team to address these challenges. It optimizes CPU and GPU resources during inference, achieving significantly higher throughput than many competitive solutions. RadixAttention is central to SGLang, which reuses shared prompt prefixes across multiple requests.
In a recent study, a team of researchers presented PowerInfer, an effective LLMinference system designed for local deployments using a single consumer-grade GPU. The team has shared that PowerInfer is a GPU-CPU hybrid inferenceengine that makes use of this understanding. Check out the Paper and Github.
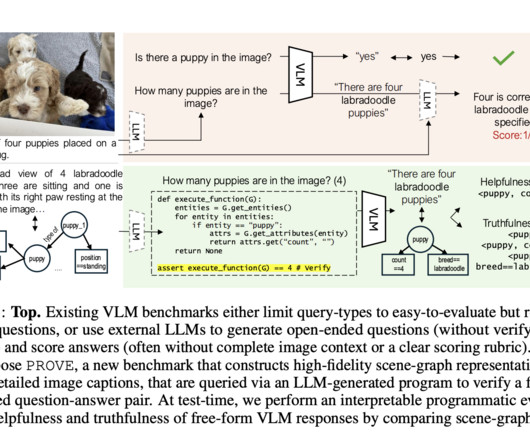
Researchers from Salesforce AIResearch have proposed Programmatic VLM Evaluation (PROVE), a new benchmarking paradigm that evaluates VLM responses to open-ended visual queries. The PROVE benchmark uses detailed scene graph representations and executable programs to verify the correctness of VLM responses.
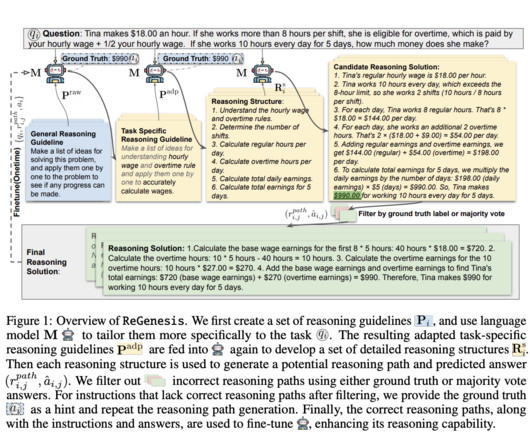
One of the critical problems faced by AIresearchers is that many current methods for enhancing LLM reasoning capabilities rely heavily on human intervention. In response to these limitations, researchers from Salesforce AIResearch introduced a novel method called ReGenesis.
This is the kind of horsepower needed to handle AI-assisted digital content creation, AI super resolution in PC gaming, generating images from text or video, querying local large language models (LLMs) and more. LLM performance is measured in the number of tokens generated by the model. Tokens are the output of the LLM.
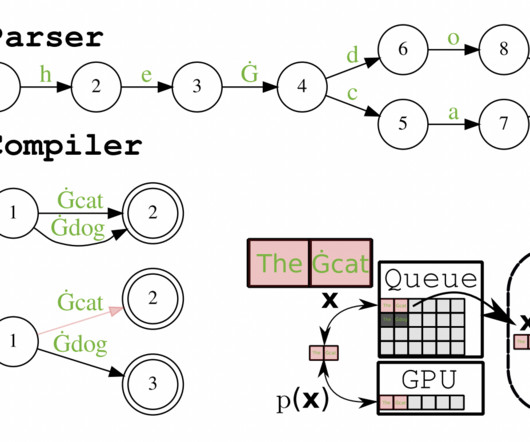
For the ever-growing challenge of LLM validation, ReLM provides a competitive and generalized starting point. ReLM is the first solution that allows practitioners to directly measure LLM behavior over collections too vast to enumerate by describing a query as the whole set of test patterns.
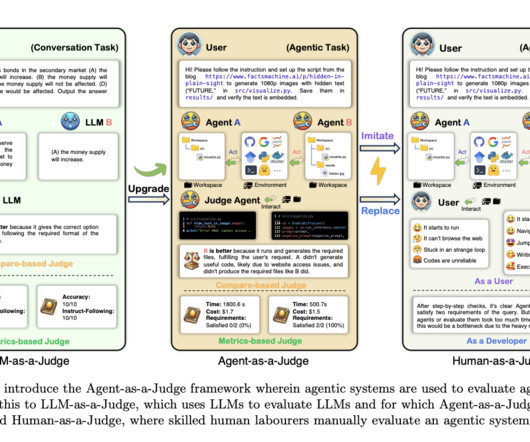
The lack of effective evaluation methods poses a serious problem for AIresearch and development. Current evaluation frameworks, such as LLM-as-a-Judge, which uses large language models to judge outputs from other AI systems, must account for the entire task-solving process. Don’t Forget to join our 50k+ ML SubReddit.
However, despite their success, LLMs often need help in mathematical reasoning, especially when solving complex problems requiring logical, step-by-step thinking. This research field is evolving rapidly as AIresearchers explore new methods to enhance LLMs’ capabilities in handling advanced reasoning tasks, particularly in mathematics.
Accelerating LLMInference with NVIDIA TensorRT While GPUs have been instrumental in training LLMs, efficient inference is equally crucial for deploying these models in production environments. Accelerating LLM Training with GPUs and CUDA. 122 ~/local 1 Verify the installation: ~/local/cuda-12.2/bin/nvcc
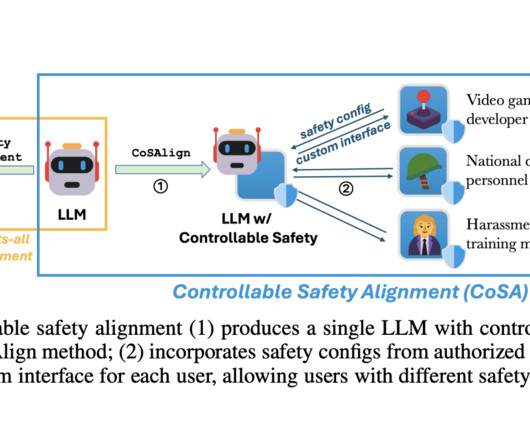
A team of researchers from Microsoft Responsible AIResearch and Johns Hopkins University proposed Controllable Safety Alignment (CoSA) , a framework for efficient inference-time adaptation to diverse safety requirements. The adapted strategy first produces an LLM that is easily controllable for safety.
These barriers limit reproducibility, increase development time, and make experimentation challenging, particularly for academia and smaller research institutions. Addressing these issues requires a lightweight, flexible, and efficient approach that reduces friction in LLMresearch. Check out the GitHub and Details.
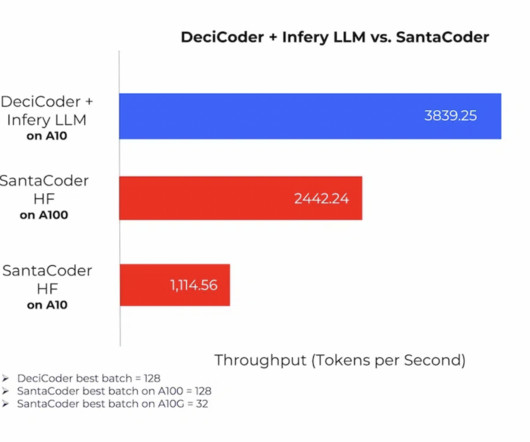
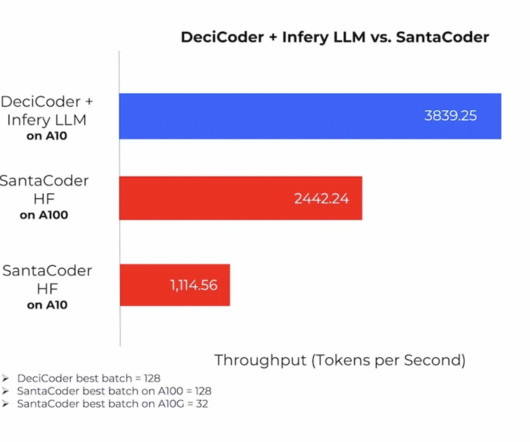
Addressing this efficiency gap head-on, Deci, a pioneering AI company, introduces DeciCoder, a 1-billion-parameter open-source Large Language Model (LLM) that aims to redefine the gold standard in efficient and accurate code generation. All Credit For This Research Goes To the Researchers on This Project.
Addressing this efficiency gap head-on, Deci, a pioneering AI company, introduces DeciCoder, a 1-billion-parameter open-source Large Language Model (LLM) that aims to redefine the gold standard in efficient and accurate code generation. All Credit For This Research Goes To the Researchers on This Project.
Lin Qiao, was formerly head of Meta's PyTorch and is the Co-Founder and CEO of Fireworks AI. Fireworks AI is a production AI platform that is built for developers, Fireworks partners with the world's leading generative AIresearchers to serve the best models, at the fastest speeds.
Overview The competition attracted 90 entries in total (only one of which was obviously just the work of an LLM!), BS’s comments This entry identifies some LLM wisdom-relevant skills that could plausibly be improved with suitable datasets using existing methods. taking a wide variety of angles on the topic.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content