
How NVIDIA AI Foundry Lets Enterprises Forge Custom Generative AI Models
NVIDIA
JULY 23, 2024
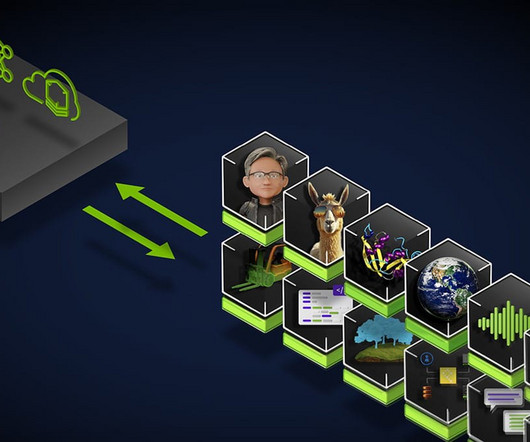
NVIDIA AI Foundry is a service that enables enterprises to use data, accelerated computing and software tools to create and deploy custom models that can supercharge their generative AI initiatives. The key difference is the product: TSMC produces physical semiconductor chips, while NVIDIA AI Foundry helps create custom models.














Let's personalize your content