This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Efficiently managing and coordinating AIinference requests across a fleet of GPUs is a critical endeavour to ensure that AI factories can operate with optimal cost-effectiveness and maximise the generation of token revenue. Dynamo orchestrates and accelerates inference communication across potentially thousands of GPUs.
Imagine this: you have built an AI app with an incredible idea, but it struggles to deliver because running largelanguagemodels (LLMs) feels like trying to host a concert with a cassette player. This is where inference APIs for open LLMs come in. The potential is there, but the performance?
This is not the sound of an AI boom going bust, but there has been a growing unease around how much money is being spent on enabling AI applications. One was an understanding that DeepSeek did not invent a new way to work with AI. After AImodels have been trained, things change.
Due to their exceptional content creation capabilities, Generative LargeLanguageModels are now at the forefront of the AI revolution, with ongoing efforts to enhance their generative abilities. However, despite rapid advancements, these models require substantial computational power and resources. Let's begin.
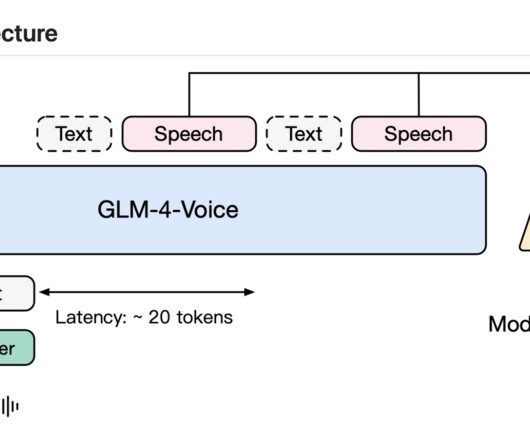
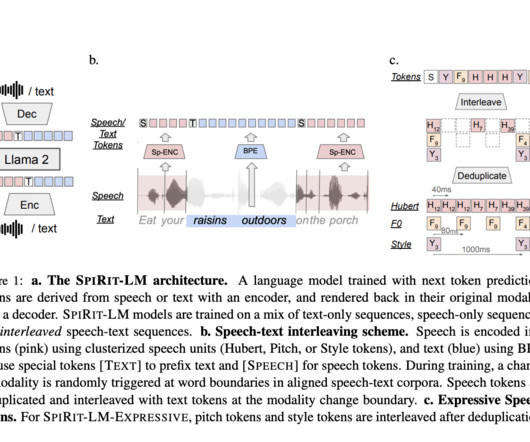
Modern AImodels excel in text generation, image understanding, and even creating visual content, but speech—the primary medium of human communication—presents unique hurdles. Zhipu AI recently released GLM-4-Voice, an open-source end-to-end speech largelanguagemodel designed to address these limitations.
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). Don’t Forget to join our 50k+ ML SubReddit.
As AIengineers, crafting clean, efficient, and maintainable code is critical, especially when building complex systems. For AI and largelanguagemodel (LLM) engineers , design patterns help build robust, scalable, and maintainable systems that handle complex workflows efficiently. GPU memory ).
Organizations require models that are adaptable, secure, and capable of understanding domain-specific contexts while also maintaining compliance and privacy standards. Traditional AImodels often struggle with delivering such tailored performance, requiring businesses to make a trade-off between customization and general applicability.
However, recent advancements in generative AI have opened up new possibilities for creating an infinite game experience. It maintains character and environment consistency through DreamBooth and a novel regional IP-Adapter that separates character and environment conditioning. Don’t Forget to join our 55k+ ML SubReddit.
Run AI recently announced an open-source solution to tackle this very problem: Run AI: Model Streamer. This tool aims to drastically cut down the time it takes to load inferencemodels, helping the AI community overcome one of its most notorious technical hurdles.
However, scaling AI across an organization takes work. It involves complex tasks like integrating AImodels into existing systems, ensuring scalability and performance, preserving data security and privacy, and managing the entire lifecycle of AImodels.
NVIDIA AI Foundry is a service that enables enterprises to use data, accelerated computing and software tools to create and deploy custom models that can supercharge their generative AI initiatives. The key difference is the product: TSMC produces physical semiconductor chips, while NVIDIA AI Foundry helps create custom models.
Imagine working with an AImodel that runs smoothly on one processor but struggles on another due to these differences. For developers and researchers, this means navigating complex problems to ensure their AI solutions are efficient and scalable on all types of hardware.
Teams from the companies worked closely together to accelerate the performance of Gemma — built from the same research and technology used to create Google DeepMind’s most capable model yet, Gemini — with NVIDIA TensorRT-LLM , an open-source library for optimizing largelanguagemodelinference, when running on NVIDIA GPUs.
The deployment of these super powerful models into production environments is NOT easy and time efficient. As we are halfway there to 2025, companies have to move beyond API calling pretrained LargeLanguageModels and go deep into thinking about deploying these full-scale models into production environment.
Traditionally, largelanguagemodels (LLMs) used for building TTS pipelines convert speech to text using automatic speech recognition (ASR), process it using an LLM, and then convert the output back to speech via TTS. If you like our work, you will love our newsletter. Don’t Forget to join our 50k+ ML SubReddit.
This is the kind of horsepower needed to handle AI-assisted digital content creation, AI super resolution in PC gaming, generating images from text or video, querying local largelanguagemodels (LLMs) and more. LLM performance is measured in the number of tokens generated by the model. Source: Jan.ai
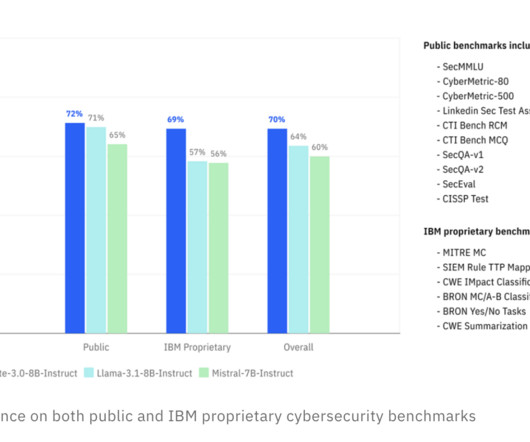
Code generation AImodels (Code GenAI) are becoming pivotal in developing automated software demonstrating capabilities in writing, debugging, and reasoning about code. These models may inadvertently introduce insecure code, which could be exploited in cyberattacks.
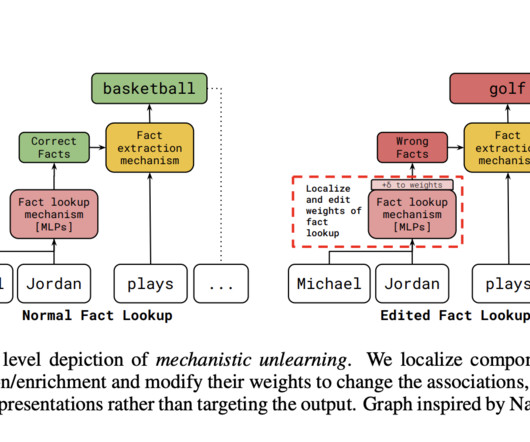
Largelanguagemodels (LLMs) sometimes learn the things that we don’t want them to learn and understand knowledge. It’s important to find ways to remove or adjust this knowledge to keep AI accurate, precise, and in control. This approach aims to make edits more robust and reduce unintended side effects.
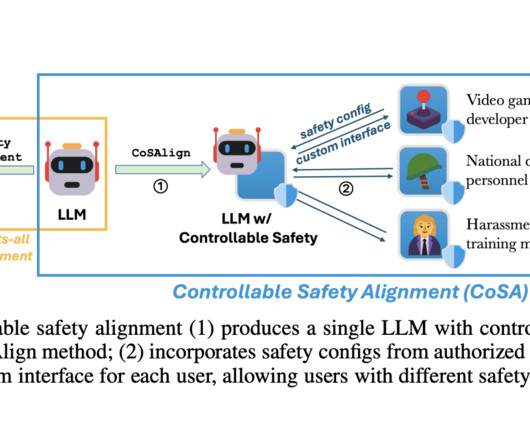
As largelanguagemodels (LLMs) become increasingly capable and better day by day, their safety has become a critical topic for research. To create a safe model, model providers usually pre-define a policy or a set of rules. In various cases, a standard one-size-fits-all safe model is too restrictive to be helpful.
Conversational AI for Indian Railway Customers Bengaluru-based startup CoRover.ai already has over a billion users of its LLM-based conversational AI platform, which includes text, audio and video-based agents. NVIDIA AI technology enables us to deliver enterprise-grade virtual assistants that support 1.3
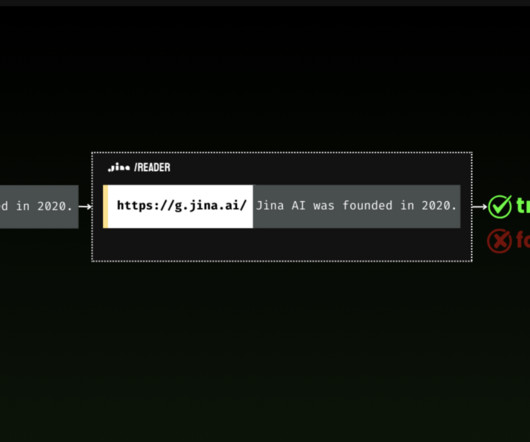
Jina AI announced the release of their latest product, g.jina.ai , designed to tackle the growing problem of misinformation and hallucination in generative AImodels. This innovative tool is part of their larger suite of applications to improve factual accuracy and grounding in AI-generated and human-written content.
Gemma is a family of lightweight, state-of-the-art open models built from research and technology used to create Google Gemini models. They are text-to-text, decoder-only largelanguagemodels, available in English, with open weights, pre-trained variants, and instruction-tuned variants.
Large Action Models (LAMs) are AI software designed to take action in a hierarchical approach where tasks are broken down into smaller subtasks. Unlike largelanguagemodels , a Large Action Model combines language understanding with logic and reasoning to execute various tasks.
Today at AWS re:Invent 2024, we are excited to announce the new Container Caching capability in Amazon SageMaker, which significantly reduces the time required to scale generative AImodels for inference. 70B model showed significant and consistent improvements in end-to-end (E2E) scaling times.
The use of largelanguagemodels (LLMs) and generative AI has exploded over the last year. With the release of powerful publicly available foundation models, tools for training, fine tuning and hosting your own LLM have also become democratized. llm = LLM(model="meta-llama/Llama-3.2-1B",
Current generative AImodels face challenges related to robustness, accuracy, efficiency, cost, and handling nuanced human-like responses. There is a need for more scalable and efficient solutions that can deliver precise outputs while being practical for diverse AI applications. Developed as part of the Llama 3.1
The rapid growth of largelanguagemodels (LLMs) has brought significant advancements across various sectors, but it has also presented considerable challenges. By doing so, Meta AI aims to enhance the performance of largemodels while reducing the computational resources needed for deployment.
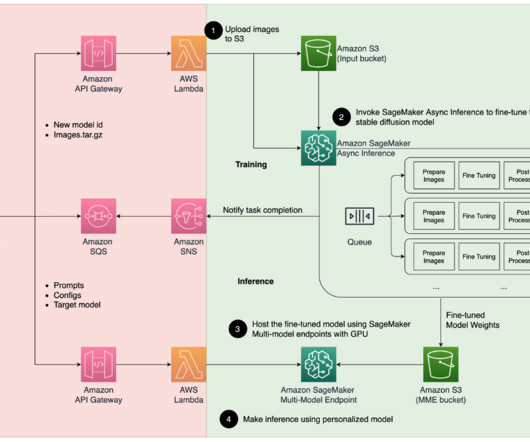
In this post, we demonstrate how you can use generative AImodels like Stable Diffusion to build a personalized avatar solution on Amazon SageMaker and save inference cost with multi-model endpoints (MMEs) at the same time. amazonaws.com/djl-inference:0.21.0-deepspeed0.8.3-cu117" deepspeed0.8.3-cu117"
NVIDIA NIM, part of the NVIDIA AI Enterprise software platform available in the AWS Marketplace , provides developers with a set of easy-to-use microservices designed for secure, reliable deployment of high-performance, enterprise-grade AImodelinference across clouds, data centers and workstations.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content