This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recent advancements in LargeLanguageModels (LLMs) have reshaped the Artificial intelligence (AI)landscape, paving the way for the creation of Multimodal LargeLanguageModels (MLLMs). Don’t Forget to join our 50k+ ML SubReddit.
Teams from the companies worked closely together to accelerate the performance of Gemma — built from the same research and technology used to create Google DeepMind’s most capable model yet, Gemini — with NVIDIA TensorRT-LLM , an open-source library for optimizing largelanguagemodelinference, when running on NVIDIA GPUs.
NVIDIA Inference Microservices (NIM) and LangChain are two cutting-edge technologies that meet these needs, offering a comprehensive solution for deploying AI in real-world environments. Understanding NVIDIA NIM NVIDIA NIM, or NVIDIA Inference Microservices, is simplifying the process of deploying AImodels.
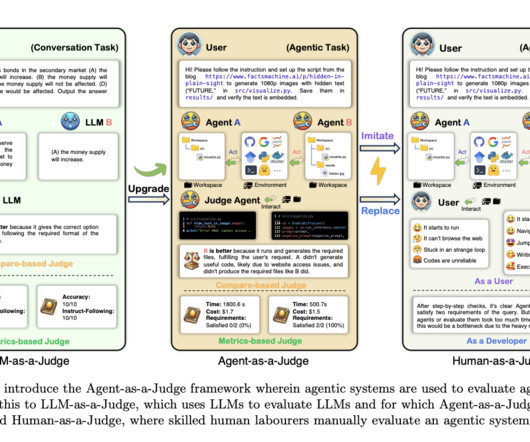
As a result, the potential for real-time optimization of agentic systems could be improved, slowing their progress in real-world applications like code generation and software development. The lack of effective evaluation methods poses a serious problem for AI research and development.
Language Processing Units (LPUs): The Language Processing Unit (LPU) is a custom inferenceenginedeveloped by Groq, specifically optimized for largelanguagemodels (LLMs). LPUs use a single-core architecture to handle computationally intensive applications with a sequential component.
According to NVIDIA's benchmarks , TensorRT can provide up to 8x faster inference performance and 5x lower total cost of ownership compared to CPU-based inference for largelanguagemodels like GPT-3. For instance, while the latest NVIDIA driver (545.xx) xx) supports CUDA 12.3,
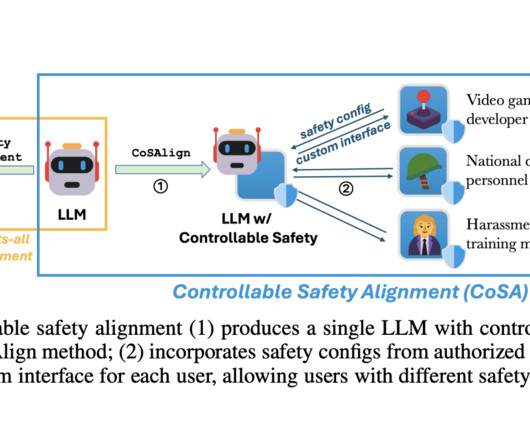
As largelanguagemodels (LLMs) become increasingly capable and better day by day, their safety has become a critical topic for research. To create a safe model, model providers usually pre-define a policy or a set of rules. In various cases, a standard one-size-fits-all safe model is too restrictive to be helpful.
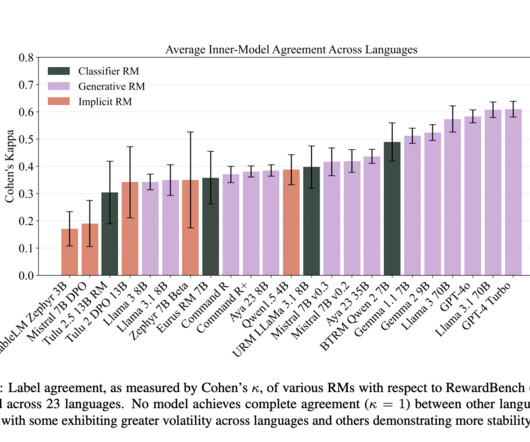
Largelanguagemodels (LLMs) have transformed fields ranging from customer service to medical assistance by aligning machine output with human values. Reward models (RMs) play an important role in this alignment, essentially serving as a feedback loop where models are guided to provide human-preferred responses.
Conversational AI for Indian Railway Customers Bengaluru-based startup CoRover.ai already has over a billion users of its LLM-based conversational AI platform, which includes text, audio and video-based agents. NVIDIA AI technology enables us to deliver enterprise-grade virtual assistants that support 1.3
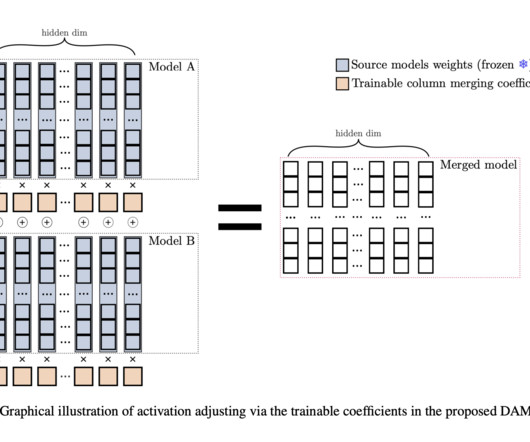
Model merging, particularly within the realm of largelanguagemodels (LLMs), presents an intriguing challenge that addresses the growing demand for versatile AI systems. DAM proves that focusing on efficiency and scalability without sacrificing performance can provide a significant advantage in AIdevelopment.
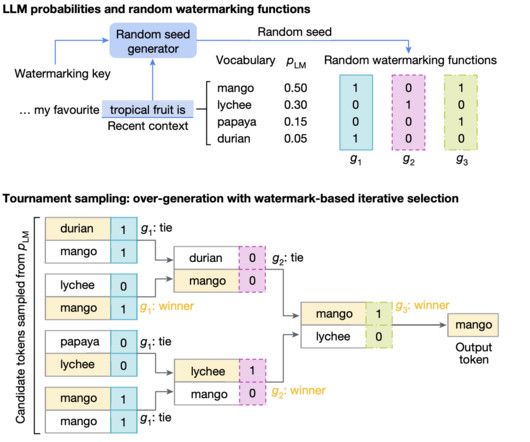
Differentiating human-authored content from AI-generated content, especially as AI becomes more natural, is a critical challenge that demands effective solutions to ensure transparency. Conclusion Google’s decision to open-source SynthID for AI text watermarking represents a significant step towards responsible AIdevelopment.
Open Collective has recently introduced the Magnum/v4 series, which includes models of 9B, 12B, 22B, 27B, 72B, and 123B parameters. This release marks a significant milestone for the open-source community, as it aims to create a new standard in largelanguagemodels that are freely available for researchers and developers.
The rapid growth of largelanguagemodels (LLMs) has brought significant advancements across various sectors, but it has also presented considerable challenges. Check out the Details and Try the model here. All credit for this research goes to the researchers of this project. Don’t Forget to join our 55k+ ML SubReddit.
Could you discuss what is developer centric AI and why this is so important? It’s simple: “developer-centric” means prioritizing the needs of AIdevelopers. For example: creating tools, communities and processes that make developers more efficient and autonomous.
The result of using these methods and technologies would be an AI-powered inferenceengine we can query to see the rational support, empirical or otherwise, of key premises to arguments that bear on important practical decisions.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content