This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Although these models are perhaps most known for revolutionising natural language processing (NLP), IBM has advanced their use cases beyond text, including applications in chemistry, geospatial data, and time series analysis. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Evaluating NLP models has become increasingly complex due to issues like benchmark saturation, data contamination, and the variability in test quality. The SMART filtering method employs three independent steps to refine NLP datasets for more efficient model benchmarking. Don’t Forget to join our 55k+ ML SubReddit.
Large language models ( LLMs ) like GPT-4, PaLM, Bard, and Copilot have made a huge impact in natural language processing (NLP). Their design makes them accessible and cost-effective, offering organizations an opportunity to harness NLP without the heavy demands of LLMs. However, they also come with significant challenges.
Introducing DataHour – a series of expert-led webinars where you can gain hands-on experience, deepen your understanding and connect with leaders in the field. Introduction Are you interested in exploring the latest advancements in the data tech industry? Do you want to enhance your career growth or transition into the field?
The field of natural language processing (NLP) has grown rapidly in recent years, creating a pressing need for better datasets to train large language models (LLMs). license, FineWeb 2 is accessible for both research and commercial applications, making it a versatile resource for the NLP community. Check out the Dataset.
Its sparse attention mechanism strikes a balance between computational demands and performance, making it an attractive solution for modern NLP tasks. As the need for processing extensive contexts grows, solutions like SepLLM will be pivotal in shaping the future of NLP. Dont Forget to join our 60k+ ML SubReddit.
This year’s lineup includes challenges spanning areas like healthcare, sustainability, natural language processing (NLP), computer vision, and more. Explore other upcoming enterprise technology events and webinars powered by TechForge here. Competitions are hosted by expert groups and developers from around the world.
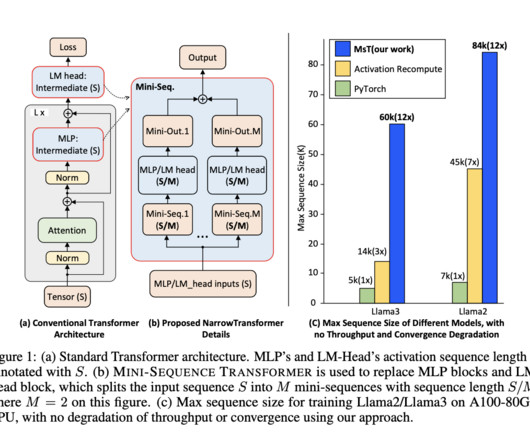
The evolution of Transformer models has revolutionized natural language processing (NLP) by significantly advancing model performance and capabilities. The successful implementation and evaluation of MST underscore its potential to enhance the scalability and performance of long-sequence training in NLP and other domains.
Introducing new sessions of February’s DataHour series, an exciting series of expert-led webinars that delve into cutting-edge advancements in the field. Introduction Looking to connect with the top minds in the field and deepen your knowledge of data tech? Get ready to accelerate your career in data tech! Mark Your Calendars Now!
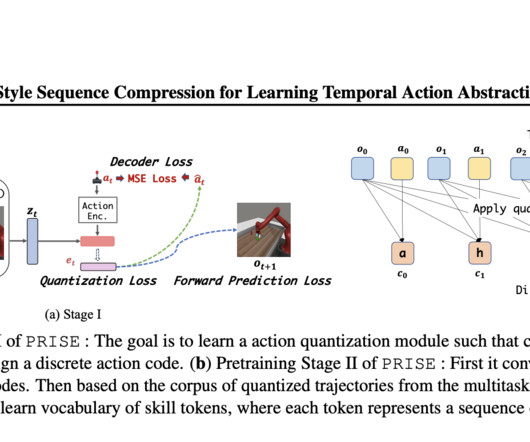
Large language models’ (LLMs) training pipelines are the source of inspiration for this method in the field of natural language processing (NLP). This research suggests adapting BPE, which is commonly utilized in NLP, to the task of learning variable timespan abilities in continuous control domains.
John Snow Labs , the award-winning Healthcare AI and NLP company, announced the latest major release of its Spark NLP library – Spark NLP 5 – featuring the highly anticipated support for the ONNX runtime. State-of-the-Art Accuracy, 100% Open Source The Spark NLP Models Hub now includes over 500 ONYX-optimized models.
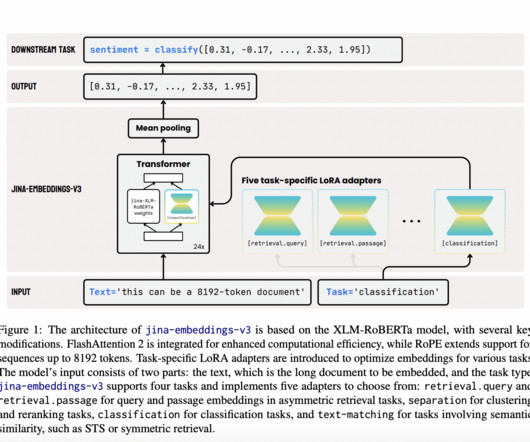
Text embedding models have become foundational in natural language processing (NLP). Introducing these innovations provides a clear path forward for further advancements in multilingual and long-text retrieval, making jina-embeddings-v3 a valuable tool in NLP. Check out the Paper and Model Card on HF.
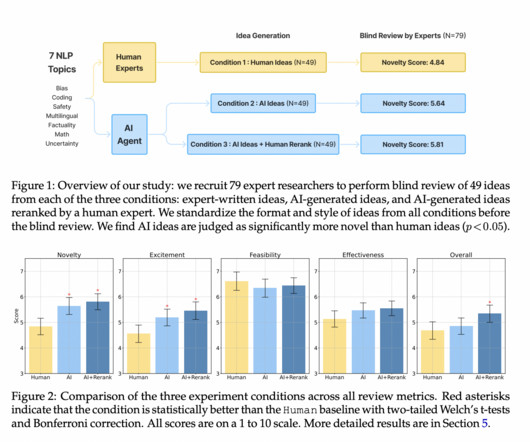
The experimental design compares an LLM ideation agent with expert NLP researchers, recruiting over 100 participants for idea generation and blind reviews. Over 100 NLP researchers participated in generating and blindly reviewing ideas from both sources. However, LLM-generated ideas were rated slightly lower in feasibility.
Don’t Forget to join our 49k+ ML SubReddit Find Upcoming AI Webinars here The post RAGLAB: A Comprehensive AI Framework for Transparent and Modular Evaluation of Retrieval-Augmented Generation Algorithms in NLP Research appeared first on MarkTechPost. If you like our work, you will love our newsletter.
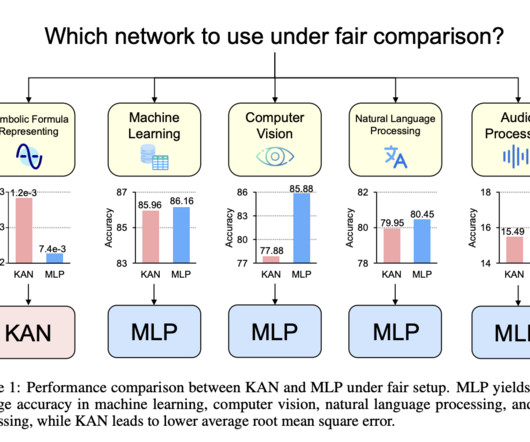
Don’t Forget to join our 47k+ ML SubReddit Find Upcoming AI Webinars here Arcee AI Released DistillKit: An Open Source, Easy-to-Use Tool Transforming Model Distillation for Creating Efficient, High-Performance Small Language Models The post MLPs vs KANs: Evaluating Performance in Machine Learning, Computer Vision, NLP, and Symbolic Tasks appeared first (..)
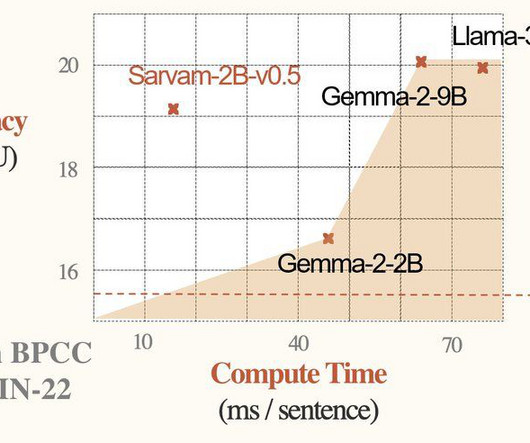
Don’t Forget to join our 48k+ ML SubReddit Find Upcoming AI Webinars here Arcee AI Released DistillKit: An Open Source, Easy-to-Use Tool Transforming Model Distillation for Creating Efficient, High-Performance Small Language Models The post Sarvam AI Releases Samvaad-Hi-v1 Dataset and Sarvam-2B: A 2 Billion Parameter Language Model with 4 Trillion (..)
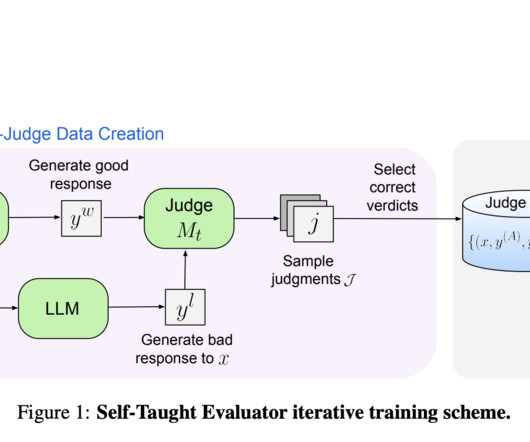
Advancements in NLP have led to the development of large language models (LLMs) capable of performing complex language-related tasks with high accuracy. A significant problem in NLP is the reliance on human annotations for model evaluation. Addressing this problem is crucial for advancing NLP technologies and their applications.
70b by Mobius Labs, boasting 70 billion parameters, has been designed to enhance the capabilities in natural language processing (NLP), image recognition, and data analysis. The model’s ability to learn from vast datasets and continuously improve its language capabilities positions it as a leader in the NLP space. HQQ Llama-3.1-70b
The data was curated from over 250 million tokens gathered from publicly available sources and mixed with instruction sets on coding, general knowledge, NLP, and conversational dialogue to retain original knowledge. Hawkish 8B directly addresses the needs of financial professionals and researchers. Don’t Forget to join our 55k+ ML SubReddit.
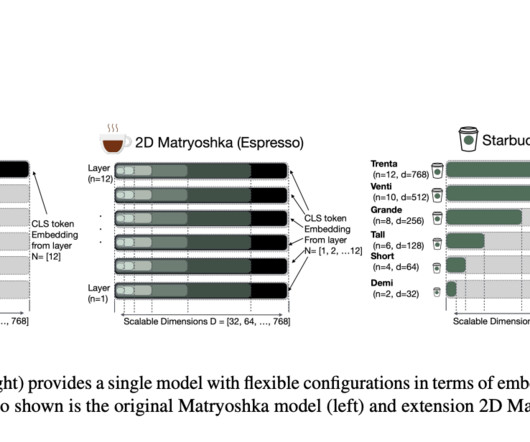
These conventional methods exhibit significant limitations, including poor integration of model dimensions and layers, which leads to diminished performance in complex NLP tasks. Substantial evaluation of broad datasets has validated the robustness and effectiveness of the Starbucks method for a wide range of NLP tasks.
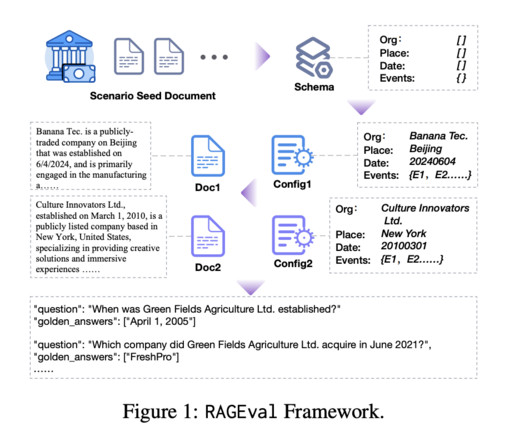
This framework introduces a collection of task description schemas for various NLP tasks, allowing users to define their specific requirements, including task objectives , labeling systems , and output format specifications. Users first choose an appropriate schema from a predefined set aligned with their NLP task requirements.
Businesses can use Klap AI to turn video ads, webinars, and promotional content into shorts to reach wider audiences. Social Media Marketers can use Klap AI to quickly create shareable clips from longer marketing videos to enhance their content strategy and maximize engagement on social media.
Artificial intelligence (AI) is making significant strides in natural language processing (NLP), focusing on enhancing models that can accurately interpret and generate human language. A major issue facing NLP is sustaining coherence over long texts. In experiments, this model demonstrated marked improvements across various benchmarks.
The creation of MMMLU reflects OpenAI’s focus on measuring models’ real-world proficiency, especially in languages that are underrepresented in NLP research. The MMMLU dataset helps bridge this gap by offering a framework for testing models in languages traditionally underrepresented in NLP research.
It also has a built-in plagiarism checker and uses natural language processing (NLP terms) to optimize content for SEO and provide relevant keyword suggestions, which search engines like Google will love. Webinars: Access Jasper webinars live and on demand.
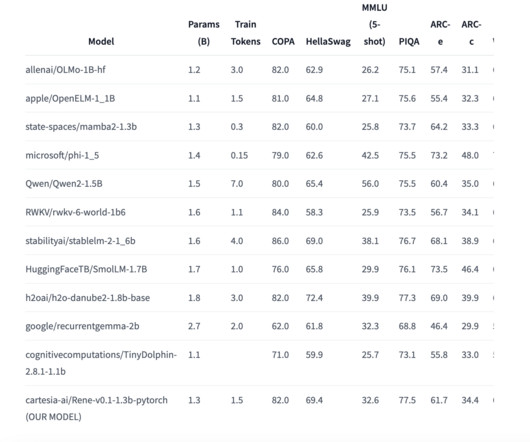
This open-source model, built upon a hybrid architecture combining Mamba-2’s feedforward and sliding window attention layers, is a milestone development in natural language processing (NLP). Performance and Benchmarking Rene has been evaluated against several common NLP benchmarks.
In the rapidly evolving field of natural language processing (NLP), integrating external knowledge bases through Retrieval-Augmented Generation (RAG) systems represents a significant leap forward. Existing RAG systems have made notable strides in improving NLP tasks such as question answering, dialogue understanding, and code generation.
This capability is particularly critical in improving language models used for summarization, information retrieval, and various other NLP tasks. In this landscape, the demand for models capable of breaking down intricate pieces of text into manageable, proposition-level components has never been more pronounced.
This new capability integrates the power of graph data modeling with advanced natural language processing (NLP). She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. More specifically, the graph created will connect chunks to documents, and entities to chunks.
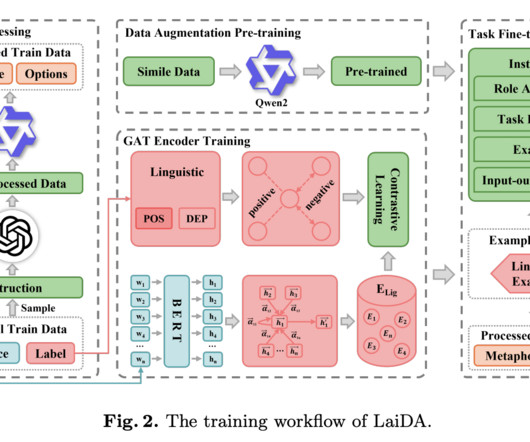
Metaphor Components Identification (MCI) is an essential aspect of natural language processing (NLP) that involves identifying and interpreting metaphorical elements such as tenor, vehicle, and ground. These components are critical for understanding metaphors, which are prevalent in daily communication, literature, and scientific discourse.
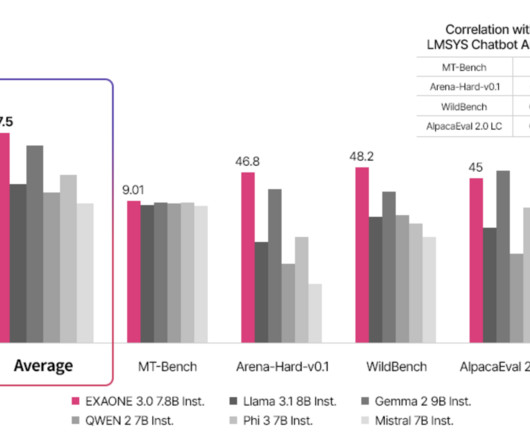
introduces advanced natural language processing (NLP) capabilities. The improved NLP capabilities are expected to significantly enhance user experience, particularly in applications where human-AI interaction is critical, such as customer service, virtual assistants, and automated content generation. Image Source EXAONE 3.0
Learn how the open-source Spark NLP library provides optimized and scalable LLM inference for high-volume text and image processing pipelines. We will show live code examples and benchmarks comparing Spark NLP’s performance and cost-effectiveness against both commercial APIs and other open-source solutions.
Upcoming Webinars: Predicting Employee Burnout at Scale Wed, Feb 15, 2023, 12:00 PM — 1:00 PM EST Join us to learn about how we used deidentification and feature selection on employee data across different clients and industries to create models that accurately predict who will burnout.
In this workshop, we will get more familiar with this type of model, how they differ from their NLP counterparts, and the tasks they can address. We will also get a short overview of the existing open-source models and datasets.
Considering the major influence of autoregressive ( AR ) generative models, such as Large Language Models in natural language processing ( NLP ), it’s interesting to explore whether similar approaches can work for images. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
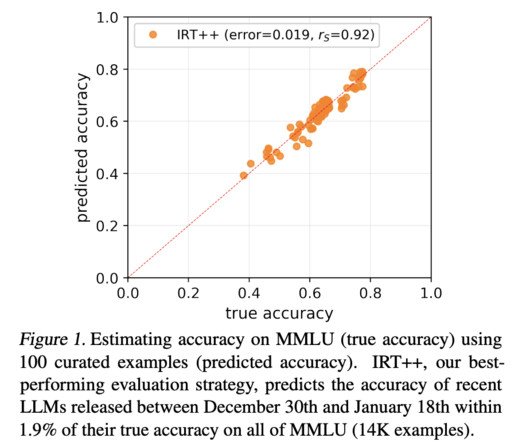
Large language models (LLMs) have shown remarkable capabilities in NLP, performing tasks such as translation, summarization, and question-answering. The research provides a practical solution for frequent and efficient evaluation of LLMs, enabling continuous improvement in NLP technologies.
Natural Language Processing (NLP), despite its progress, faces the persistent challenge of hallucination, where models generate incorrect or nonsensical information. This limitation arises from the difficulty in curating high-quality datasets that can comprehensively test the models’ ability to handle domain-specific information.
In recent years, their application has expanded beyond NLP and media generation to fields like finance, where the challenges of intricate data streams and real-time analysis demand innovative solutions. Generative models have emerged as great tools for synthesizing complex data and enabling sophisticated industry predictions.
Create – Write SEO content that ranks by using the most advanced versions of NLP and NLU ( Natural Language Processing & Natural Language Understanding). Pictory also allows you to easily edit videos using text, which is perfect for editing webinars, podcasts, Zoom recordings, and more.
The models are trained on over 12 trillion tokens across 12 languages and 116 programming languages, providing a versatile base for natural language processing (NLP) tasks and ensuring privacy and security. delivers powerful NLP features in a secure and transparent manner. If you like our work, you will love our newsletter.
Multilingual applications and cross-lingual tasks are central to natural language processing (NLP) today, making robust embedding models essential. As the need for multilingual NLP solutions continues to grow, KaLM-Embedding serves as a testament to the impact of high-quality data and thoughtful model design.
Question answering (QA) is a crucial area in natural language processing (NLP), focusing on developing systems that can accurately retrieve and generate responses to user queries from extensive data sources. Check out the Paper. All credit for this research goes to the researchers of this project.
With the development of huge Large Language Models (LLMs), such as GPT-3 and GPT-4, Natural Language Processing (NLP) has developed incredibly in recent years. One of the central challenges that NLP faces in this respect is identifying which type of reasoning- deductive or inductive- is more challenging for LLMs. Check out the Paper.
by generating elegant and articulate poetry in structured forms, demonstrating a powerful synergy of natural language processing (NLP) and creative AI. The technical backbone of Anthropic AI’s computer use feature is bridging NLP with autonomous software interaction. This capability allows Claude 3.5
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























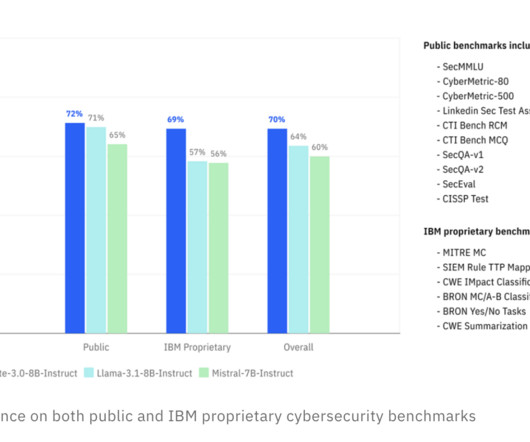


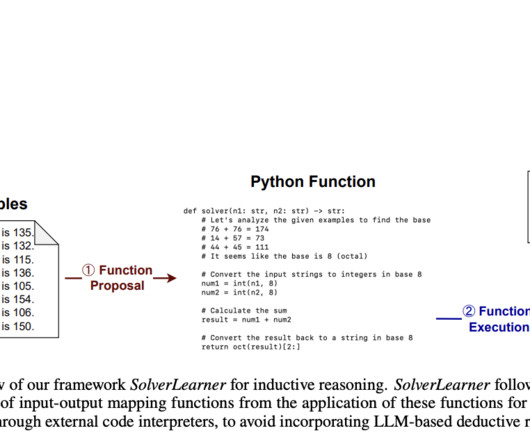
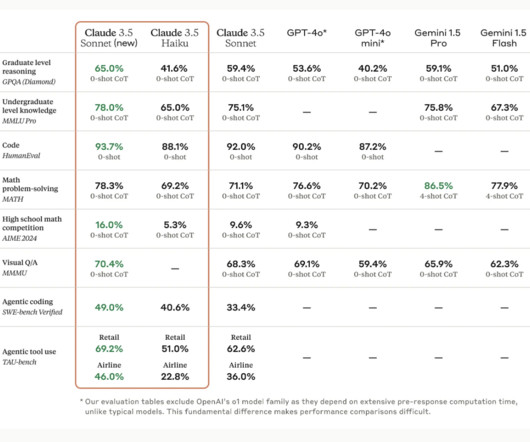






Let's personalize your content