This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Operating virtually rather than from a single physical base, Cognitive Labs will explore AI technologies such as Graph NeuralNetworks (GNNs), Active Learning, and Large-Scale Language Models (LLMs). Explore other upcoming enterprise technology events and webinars powered by TechForge here.
“While a traditional Transformer functions as one large neuralnetwork, MoE models are divided into smaller ‘expert’ neuralnetworks,” explained Demis Hassabis, CEO of Google DeepMind. Explore other upcoming enterprise technology events and webinars powered by TechForge here. The post Google launches Gemini 1.5
He outlined key attributes of neuralnetworks, embeddings, and transformers, focusing on large language models as a shared foundation. Neuralnetworks — described as probabilistic and adaptable — form the backbone of AI, mimicking human learning processes.
IBM Research has unveiled a groundbreaking analog AI chip that demonstrates remarkable efficiency and accuracy in performing complex computations for deep neuralnetworks (DNNs). To tackle these challenges, IBM Research has harnessed the principles of analog AI, which emulates the way neuralnetworks function in biological brains.
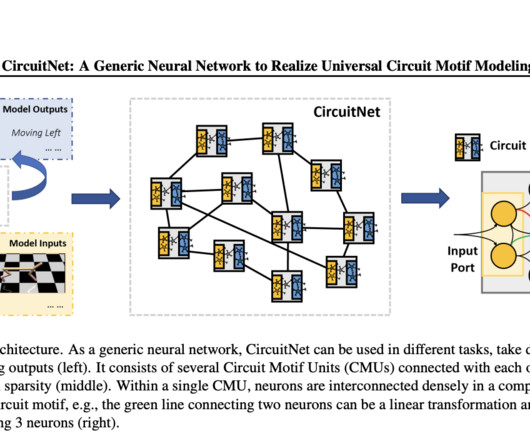
Recent neural architectures remain inspired by biological nervous systems but lack the complex connectivity found in the brain, such as local density and global sparsity. Researchers from Microsoft Research Asia introduced CircuitNet, a neuralnetwork inspired by neuronal circuit architectures.
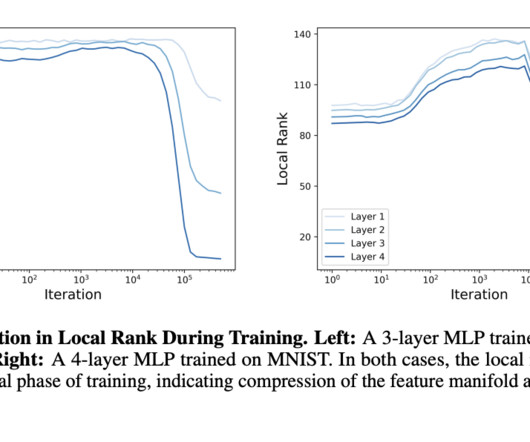
Deep neuralnetworks are powerful tools that excel in learning complex patterns, but understanding how they efficiently compress input data into meaningful representations remains a challenging research problem. The paper presents both theoretical analysis and empirical evidence demonstrating this phenomenon.
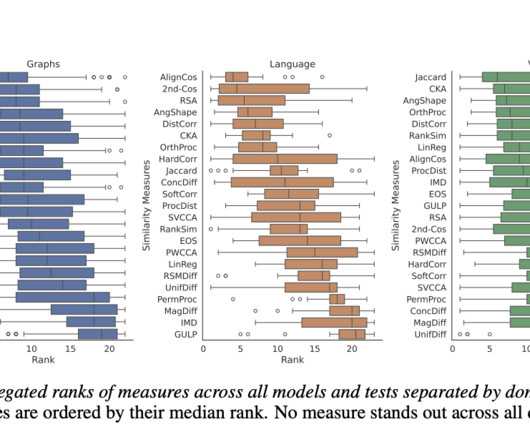
Representational similarity measures are essential tools in machine learning, used to compare internal representations of neuralnetworks. These measures help researchers understand learning dynamics, model behaviors, and performance by providing insights into how different neuralnetwork layers and architectures process information.
Deep Learning is a subfield of Machine Learning, inspired by the biological neurons of a brain, and translated to artificial neuralnetworks with representation learning. Dear Readers, We bring you another episode of our DataHour series. In this DataHour session, Umang will take you through a fun ride of live DEMO!
Enter SingularityNET’s ambitious plan: a “multi-level cognitive computing network” designed to host and train the incredibly complex AI architectures required for AGI. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
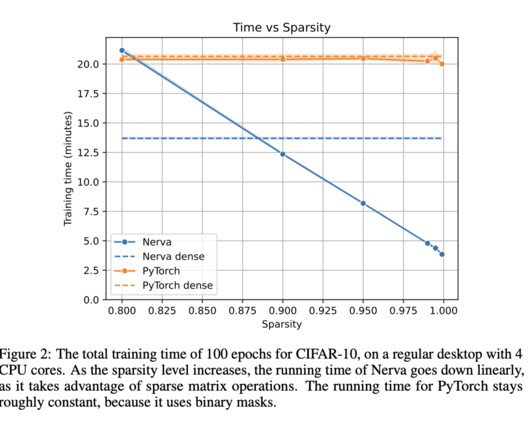
Sparsity in neuralnetworks is one of the critical areas being investigated, as it offers a way to enhance the efficiency and manageability of these models. By focusing on sparsity, researchers aim to create neuralnetworks that are both powerful and resource-efficient. Check out the Paper.
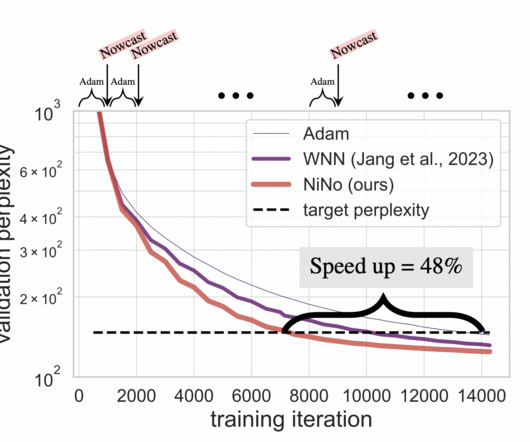
In deep learning, neuralnetwork optimization has long been a crucial area of focus. Training large models like transformers and convolutional networks requires significant computational resources and time. One of the central challenges in this field is the extended time needed to train complex neuralnetworks.
A key challenge she encounters is misunderstandings around what AI truly means – many conflate it solely with chatbots like ChatGPT rather than appreciating the full breadth of machine learning, neuralnetworks, natural language processing, and more that enable today’s AI. “There’s a lot of misconceptions, definitely.
This technological foundation enables parallel processing capabilities, crucial for handling complex neuralnetwork AI computations. Explore other upcoming enterprise technology events and webinars powered by TechForge here. The post Intel’s Aurora achieves exascale to become the fastest AI system appeared first on AI News.
Advanced Machine Learning models called Graph NeuralNetworks (GNNs) process and analyze graph-structured data. The idea of training-free Graph NeuralNetworks (TFGNNs) has been presented as a solution to these problems. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Selecting efficient neuralnetwork architectures helps, as does compression techniques like quantisation to reduce precision without substantially impacting accuracy. Explore other upcoming enterprise technology events and webinars powered by TechForge here. And that’s a big struggle,” explains Grande.
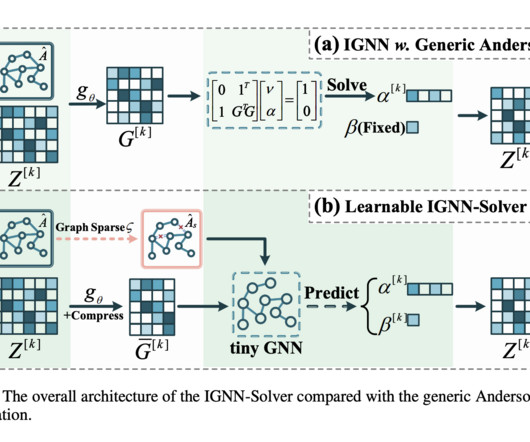
A team of researchers from Huazhong University of Science and Technology, hanghai Jiao Tong University, and Renmin University of China introduce IGNN-Solver, a novel framework that accelerates the fixed-point solving process in IGNNs by employing a generalized Anderson Acceleration method, parameterized by a small Graph NeuralNetwork (GNN).
Gcore trained a Convolutional NeuralNetwork (CNN) – a model designed for image analysis – using the CIFAR-10 dataset containing 60,000 labelled images, on these devices. Explore other upcoming enterprise technology events and webinars powered by TechForge here. The event is co-located with Digital Transformation Week.
Researchers from IBM Research, Tel Aviv University, Boston University, MIT, and Dartmouth College have proposed ZipNN, a lossless compression technique specifically designed for neuralnetworks. ZipNN can compress neuralnetwork models by up to 33%, with some instances showing reductions exceeding 50% of the original model size.
Pioneering capabilities The introduction of GPT-4o marks a leap from its predecessors by processing all inputs and outputs through a single neuralnetwork. Explore other upcoming enterprise technology events and webinars powered by TechForge here. seconds for GPT-3.5 seconds for GPT-4.
With its unprecedented efficiency and support for transformer neuralnetworks, we are empowering users across industries to unlock the full potential of AI without compromising on data privacy and security.” Explore other upcoming enterprise technology events and webinars powered by TechForge here.
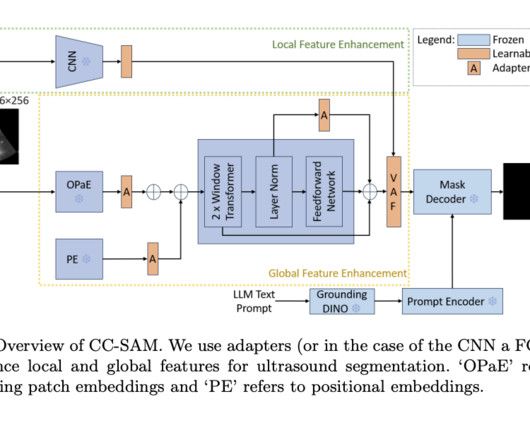
This model incorporates a static Convolutional NeuralNetwork (CNN) branch and utilizes a variational attention fusion module to enhance segmentation performance. Hausdorff Distance Using Convolutional NeuralNetwork CNN and ViT Integration appeared first on MarkTechPost. Dice Score and 27.10
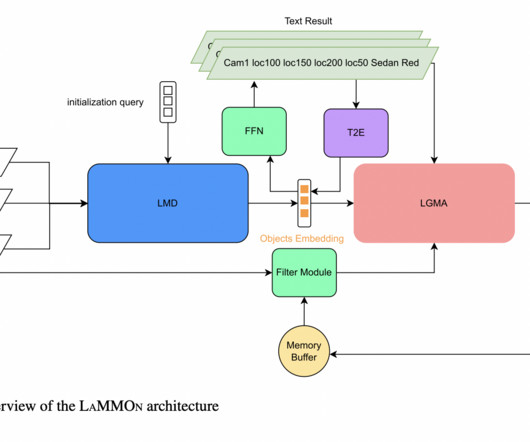
Researchers from the University of Tennessee at Chattanooga and the L3S Research Center at Leibniz University Hannover have developed LaMMOn, an end-to-end multi-camera tracking model based on transformers and graph neuralnetworks. If you like our work, you will love our newsletter.
Current approaches to machine vision, highly dependent on conventional deep neuralnetworks (DNNs) with standard activation functions like ReLU, face limitations in duplicating human-like perception of optical illusions. If you like our work, you will love our newsletter. Don’t Forget to join our 55k+ ML SubReddit.
Researchers from Google Research, Mountain View, CA, and Google Research, New York, NY have proposed a novel method called Learned Augmented Residual Layer (LAUREL), which revolutionizes the traditional residual connection concept in neuralnetworks. This minimal parameter addition makes LAUREL efficient for large-scale models.
These neuralnetworks power the most complex and compute-intensive generative AI applications, spanning from question answering and code generation to audio, video, image synthesis, and speech recognition. Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Advancements in neuralnetworks have brought significant changes across domains like natural language processing, computer vision, and scientific computing. Neuralnetworks often employ higher-order tensor weights to capture complex relationships, but this introduces memory inefficiencies during training.
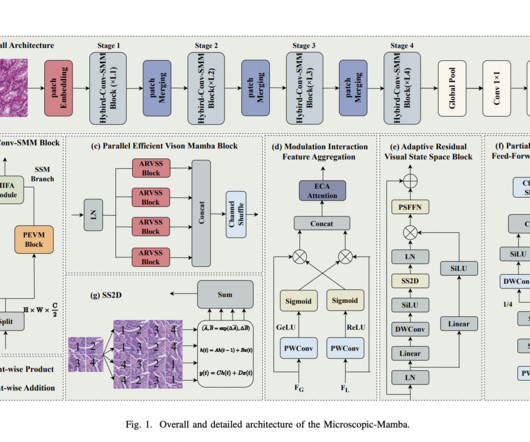
Traditional machine learning methods, such as convolutional neuralnetworks (CNNs), have been employed for this task, but they come with limitations. Moreover, the scale of the data generated through microscopic imaging makes manual analysis impractical in many scenarios. If you like our work, you will love our newsletter.
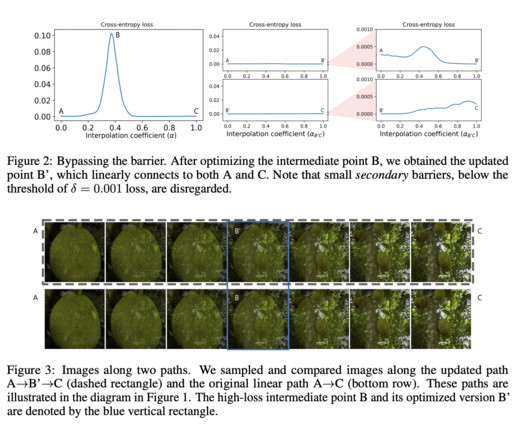
Input space mode connectivity in deep neuralnetworks builds upon research on excessive input invariance, blind spots, and connectivity between inputs yielding similar outputs. The phenomenon exists generally, even in untrained networks, as evidenced by empirical and theoretical findings.
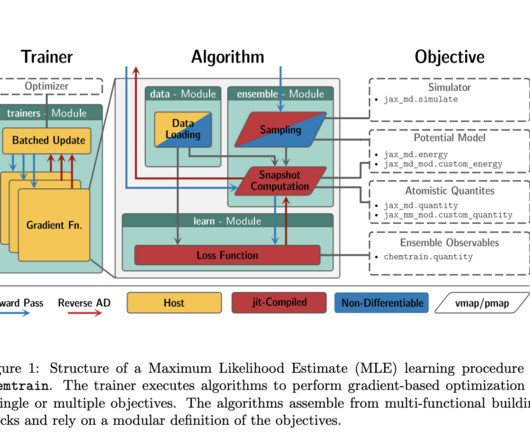
The implementation of NeuralNetworks (NNs) is significantly increasing as a means of improving the precision of Molecular Dynamics (MD) simulations. This could lead to new applications in a wide range of scientific fields. If you like our work, you will love our newsletter.
Recurrent NeuralNetworks were the trailblazers in natural language processing and set the cornerstone for future advances. RNNs were simple in structure with their contextual memory and constant state size, which promised the capacity to handle long sequence tasks. Don’t Forget to join our 55k+ ML SubReddit.
Results and Performance In order to evaluate the accuracy and robustness of Conformer-1, we sourced 60+ hours of human labeled audio data covering popular speech domains such as call centers, podcasts, broadcasts, and webinars. "Contextnet: Improving convolutional neuralnetworks for automatic speech recognition with global context."
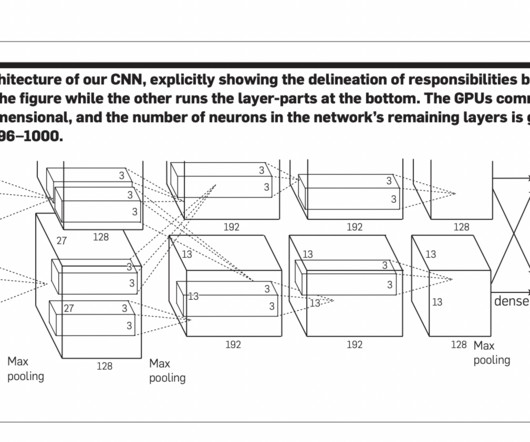
Previously, researchers doubted that neuralnetworks could solve complex visual tasks without hand-designed systems. Training the network took five to six days, leveraging optimized GPU implementations of convolution operations to achieve state-of-the-art performance in object recognition tasks.
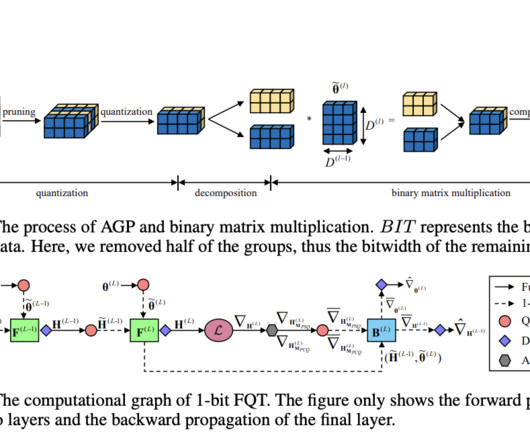
Deep neuralnetwork training can be sped up by Fully Quantised Training (FQT), which transforms activations, weights, and gradients into lower precision formats. They have experimented with their approach by optimizing popular neuralnetwork models, like VGGNet-16 and ResNet-18, using various datasets.
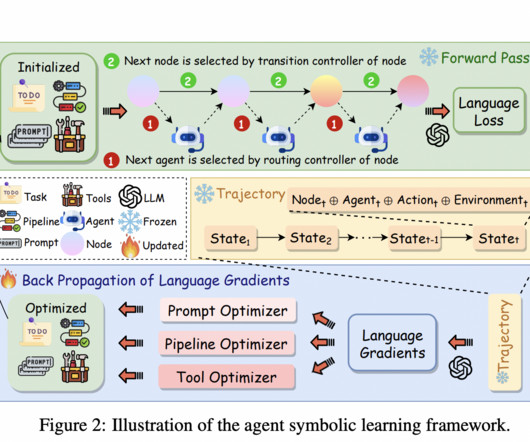
introduce agent symbolic learning framework as an innovative approach for training language agents that draws inspiration from neuralnetwork learning. This framework draws an analogy between language agents and neural nets, mapping agent pipelines to computational graphs, nodes to layers, and prompts and tools to weights.
Calculating Receptive Field for Convolutional NeuralNetworks Convolutional neuralnetworks (CNNs) differ from conventional, fully connected neuralnetworks (FCNNs) because they process information in distinct ways. Receptive fields are the backbone of CNN efficacy.
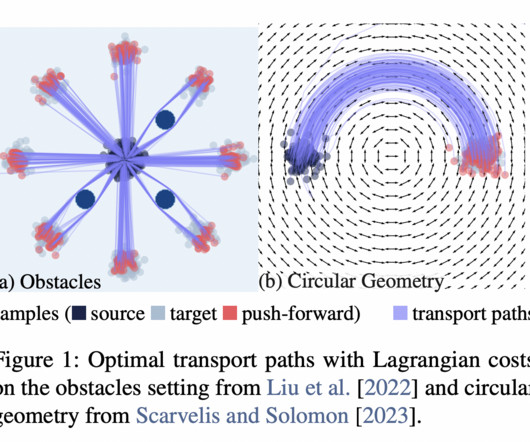
Neuralnetworks and stochastic differential equations (SDEs) are sometimes used to approximate solutions, but these methods can be inefficient and lack the accuracy needed for more complex scenarios. Currently, methods for solving optimal transport problems with complex cost functions are limited.
Traditional 2D neuralnetwork-based segmentation methods still need to be fully optimized for these high-dimensional imaging modalities, highlighting the need for more advanced approaches to handle the increased data complexity effectively. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Gr oup.
Inspired by the brain, neuralnetworks are essential for recognizing images and processing language. These networks rely on activation functions, which enable them to learn complex patterns. Currently, activation functions in neuralnetworks face significant issues. Dont Forget to join our 60k+ ML SubReddit.
However, these neuralnetworks face challenges in interpretation and scalability. The difficulty in understanding learned representations limits their transparency, while expanding the network scale often proves complex. Also, MLPs rely on fixed activation functions, potentially constraining their adaptability.
You are also invited to join our monthly webinars, where you can gain deeper insights into our products and learn best practices for implementation and usage. Through comprehensive initial and ongoing training sessions, you empower your staff with the skills needed for continuous skill development and confident usage.
Replicating this process with neural models is particularly difficult due to issues such as maintaining visual fidelity, ensuring stability over extended sequences, and achieving the necessary real-time performance. 2020) have been developed to simulate game environments using neuralnetworks.
Conventional methods involve training neuralnetworks from scratch using gradient descent in a continuous numerical space. This shift raises a compelling question: Can a pretrained LLM function as a system parameterized by its natural language prompt, analogous to how neuralnetworks are parameterized by numerical weights?
Building massive neuralnetwork models that replicate the activity of the brain has long been a cornerstone of computational neuroscience’s efforts to understand the complexities of brain function. These models, which are frequently intricate, are essential for comprehending how neuralnetworks give rise to cognitive functions.
This feature is especially useful for repeated neuralnetwork modules like those commonly used in transformers. The regional compilation for torch.compile is another key enhancement that offers a more modular approach to compiling neuralnetworks. If you like our work, you will love our newsletter.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















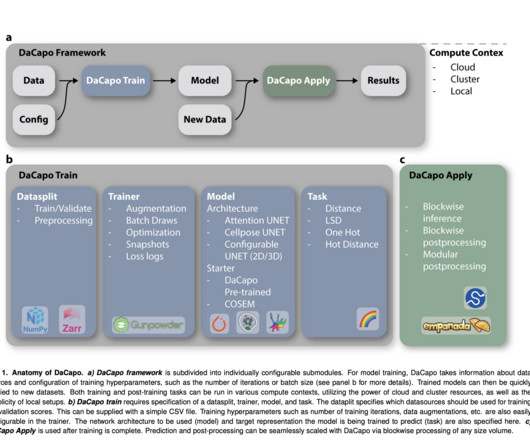

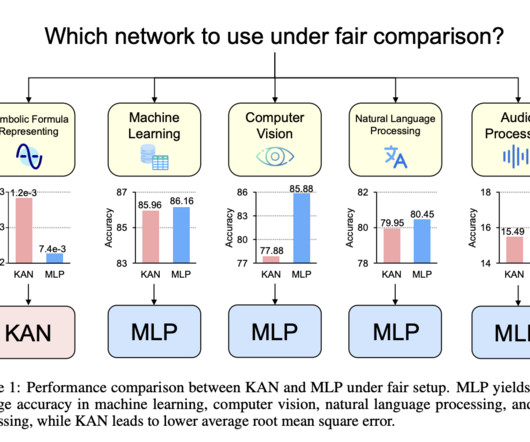

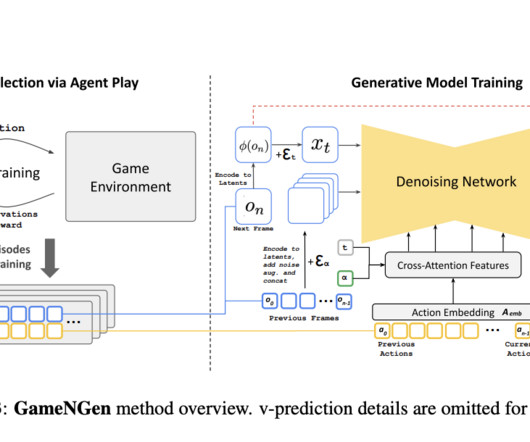









Let's personalize your content