This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Got the Receipts OpenAI's latest image-generating 4o model is surprisingly good at generating text inside images, a feat that had proved particularly difficult for its many predecessors. Guardrails like appended metadata or watermarks that divulge whether an image was generated by an AI are easily overcome.
OpenAI is joining the Coalition for Content Provenance and Authenticity (C2PA) steering committee and will integrate the open standard’s metadata into its generative AI models to increase transparency around generated content. The tool predicts the likelihood an image originated from one of OpenAI’s models.
This article will focus on LLM capabilities to extract meaningful metadata from product reviews, specifically using OpenAI API. Data processing Since our main area of interest is extracting metadata from reviews, we had to choose a subset of reviews and label it manually with selected fields of interest.
It also mandates the labelling of deepfakes with permanent unique metadata or other identifiers to prevent misuse. Photo by Naveed Ahmed on Unsplash ) See also: Elon Musk sues OpenAI over alleged breach of nonprofit agreement Want to learn more about AI and big data from industry leaders?
For instance, we use query rewriting techniques such as expansion, relaxation, and segmentation, and extract metadata from queries to dynamically build filters for more targeted searches.
Large language models (LLMs) like OpenAI's GPT series have been trained on a diverse range of publicly accessible data, demonstrating remarkable capabilities in text generation, summarization, question answering, and planning. OpenAI Setup : By default, LlamaIndex utilizes OpenAI's gpt-3.5-turbo
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) For example, you can apply a model from OpenAI with a Query Engine. The metadata needs to be smaller than the text chunk size, and since it contains the full JSON response with extra information, it is quite large.
Businesses often obsess over shiny new models like DeepSeek-R1 or OpenAI o1 while neglecting the importance of infrastructure to derive value from them. Did we over-invest in companies like OpenAI and NVIDIA? It can also enable consistent access to metadata and context no matter what models you are using.
The metadata contains the full JSON response of our API with more meta information: print(docs[0].metadata) For example, you can apply a model from OpenAI with a QA chain. After loading the data, the transcribed text is stored in the page_content attribute: print(docs[0].page_content) page_content) # Runner's knee.
In todays edition: OpenAI Officially Launches its Sora AI Video GeneratorGoogle Launches New Willow Quantum ChipGrok Unveils New Image Generator with Text and Face RenderingChina Targets Nvidia with Antitrust ProbeAnd more AI news.Image by: OpenAI The Gist: OpenAI has released Sora, its much-anticipated AI video generation platform.
In todays edition: OpenAI Officially Launches its Sora AI Video GeneratorGoogle Launches New Willow Quantum ChipGrok Unveils New Image Generator with Text and Face RenderingChina Targets Nvidia with Antitrust ProbeAnd more AI news.Image by: OpenAI The Gist: OpenAI has released Sora, its much-anticipated AI video generation platform.
makes it easy for RAG developers to track evaluation metrics and metadata, enabling them to analyze and compare different system configurations. langchain-openai== 0.0.6 For this example, well use OpenAIs models and configure the API key. In our case, thats OpenAIs GPT4o-mini. langchain-chroma== 0.1.4 ragas== 0.2.8
The closed-source models are OpenAI’s GPT-3.5 DuckDuckGo also strips away metadata, such as server or IP addresses, so that queries appear to originate from the company itself rather than individual users. The service, accessible at Duck.ai , is globally available and features a light and clean user interface.
Often support for metadata filtering alongside vector search Popular vector databases include FAISS (Facebook AI Similarity Search), Pinecone, Weaviate, Milvus, and Chroma. Modern embedding models like those from OpenAI, Cohere, or Sentence Transformers can capture nuanced semantic relationships. Image embeddings 5.
5 Reasons When to Use OpenAI Assistants API ✅ In this blog, we are going to explore some key differences between chat completion models (like those provided via the Chat Completions endpoint) and the more advanced OpenAI Assistance API. Once you ask a question, you must wait for a single response. status}")# […] .",
Status code: {response.status_code}') Now, we need to set up Langchain and OpenAI. Step 3: Setup for Langchain and OpenAI For Langchain and OpenAI setup first make a new Python file named ‘ test_pdf_reader.py’ And followed steps 1-7 from our RAG Tutorial using OpenAI and Langchain blog. turbo” etc.
This article shows you how to build a simple RAG chatbot in Python using Pinecone for the vector database and embedding model, OpenAI for the LLM, and LangChain for the RAG workflow. An OpenAI account and API key. Author(s): Abhishek Chaudhary Originally published on Towards AI.
for this tutorial, so you’ll need an OpenAI API key as well - sign up here if you don’t have one already. Getting started To follow this tutorial, you’ll need an AssemblyAI API key. You can get one for free here if you don’t already have one. Additionally, we’ll be using GPT 3.5 filepath/URL).
5 Reasons When to Use OpenAI Assistants API ✅ In this blog, we are going to explore some key differences between chat completion models (like those provided via the Chat Completions endpoint) and the more advanced OpenAI Assistance API. Once you ask a question, you must wait for a single response. status}")# […] .",
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. GPT-3, OpenAI’s language prediction model that can process and generate human-like text, is an example of a foundation model. Capture and document model metadata for report generation.
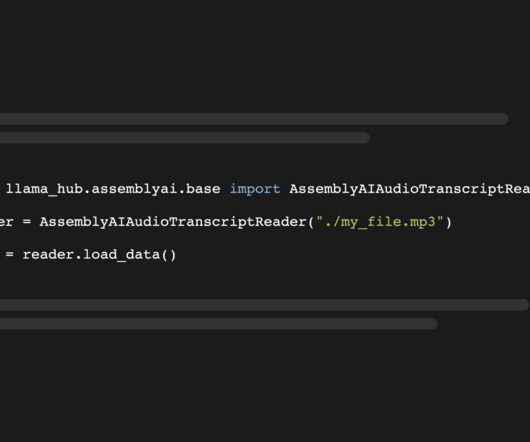
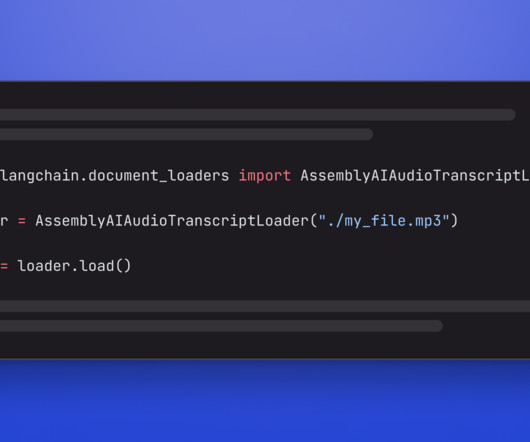
Extract and generate data : Find out how to extract tags and descriptions from your audio to enhance metadata and searchability with LeMUR. Read more>> Build a Discord Voice Bot to Add ChatGPT to Your Voice Channel : Develop a Discord voice bot that uses AssemblyAI for speech transcription, OpenAI's GPT-3.5
Over the past several months I’ve been collaborating with Dom Divakaruni, the Head of Product for Azure OpenAI Service. I couldn’t be more excited to share what we’ve been working on with DataRobot and Microsoft Azure OpenAI service. Today we are unveiling a new cutting-edge integration with Microsoft Azure OpenAI Service.
OpenAI Whisper Whisper , developed by OpenAI, is a versatile speech recognition model capable of tasks like transcription, multilingual processing, and handling noisy audio. If you want to learn more, you can read this blog post on how to run OpenAI’s Whisper model. # We’ll cover the four most common ones here.
This is a chart of the Average Word Error Rate of AssemblyAI's Universal-1 model compared to Deepgram Nova-2, OpenAI Whisper Large-v3, Amazon, Microsoft Azure Batch v3.1, Google Latest-long by Language (English, Spanish, German, French) In the last few years we've seen an explosion of audio data available online.
The model is hosted on Arcees inference platform, Model Engine , which is designed to be compatible with OpenAI APIs, making it easy for developers to integrate Spotlight into their existing workflows. API Compatibility : Fully compatible with OpenAI APIs, ensuring a smooth integration process. It is based on the Qwen 2.5-VL
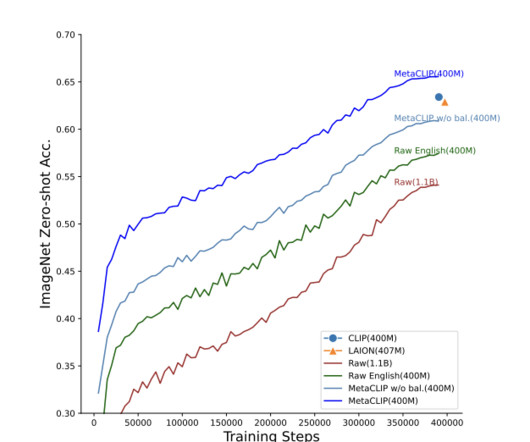
CLIP is a neural network developed by OpenAI trained on a massive dataset of text and image pairs. In this research paper, the researchers have tried to make the data curation approach of CLIP available to the public and have introduced Metadata-Curated Language-Image Pre-training (MetaCLIP).
While OpenAI has taken the lead, the competition is growing. Automatic capture of model metadata and facts provide audit support while driving transparent and explainable model outcomes. According to Precedence Research , the global generative AI market size valued at USD 10.79 in 2022 and it is expected to be hit around USD 118.06
The tool supports multiple file formats, including PDFs, PowerPoint presentations, Word documents, Excel spreadsheets, and images, by extracting EXIF metadata and performing OCR. MarkItDown also supports ZIP files, iterating over their contents to ensure all data is converted into a cohesive Markdown structure.
Users can also interact with image data thanks to support for Contrastive Language-Image Pre-training from OpenAI. With CLIP support in ChatRTX, users can interact with photos and images on their local devices through words, terms and phrases, without the need for complex metadata labeling.
End-to-end reinforcement learning (RL) methods like OpenAI’s o-series, DeepSeek-R1, and Kimi K-1.5 This dataset was created by extracting 50,000 Visual Concepts from both familiar and unfamiliar sections of the MetaCLIP metadata distribution, retrieving associated images, and using GPT-4o to generate factual question-answer pairs.
Each referenced string can have extra metadata that describes the original document. Researchers fabricated some metadata to use in the tutorial. Each collection includes documents, which are just lists of strings, IDs, which serve as unique identifiers for the documents, and metadata (which is not required).
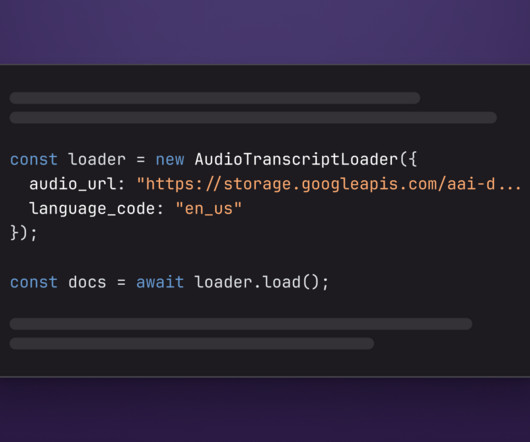
Configure environment variables The application you're building needs your OpenAI API key and AssemblyAI API key. ", }); console.log(response.text); })(); The code above connects to OpenAI's LLM and creates a chain for Q&A that is being called with a hardcoded document and the question "What is a runner's knee?"
OpenAI's GPT series and almost all other LLMs currently are powered by transformers utilizing either encoder, decoder, or both architectures. Transformer -based autoregressive models and U-Net-based diffusion models , are at the forefront of technology, producing state-of-the-art (SOTA) results in generating audio, text, music, and much more.
loading webpage content by URL and pandas dataframe on the fly These loaders use standard document formats comprising content and associated metadata. On the other hand, YouTube content is handled through a chain involving a YouTube audio loader with an OpenAI Whisper parser that converts audio to text format. ChunkViz v0.1
In OpenAIs 12 days of Christmas, the company has so far launched a new $200 per month ChatGPT Pro subscription, its o1 and o1-Pro reasoning models, Sora Turbo (text-to-video model), and a new LLM customization technique reinforcement fine-tuning. OpenAI moved its o1 reasoning model out of preview to mixed reception.
In OpenAIs 12 days of Christmas, the company has so far launched a new $200 per month ChatGPT Pro subscription, its o1 and o1-Pro reasoning models, Sora Turbo (text-to-video model), and a new LLM customization technique reinforcement fine-tuning. OpenAI moved its o1 reasoning model out of preview to mixed reception.
To generate metadata, this plugin employs AI to recognize unique terms throughout the site. SEOPress, in contrast to most other SEO plugins, is compatible with OpenAI. SEO metadata (meta titles and descriptions) are automatically generated by this function using AI analysis of the post’s content.
This includes new AI-voice bans from the FCC, White House cryptographic verification of its statements to combat deepfakes, and new watermarks at OpenAI on DALL-E 3 content. C2PA is an open technical standard that allows publishers, companies, and others to embed metadata in media to verify its origin and related information.
llm = OpenAI(temperature=0)conversation_with_summary = ConversationChain(llm=llm,memory=ConversationSummaryMemory(llm=OpenAI()),verbose=True)conversation_with_summary.predict(input="Hi, what's up?") from the structure or metadata) and use it effectively.
Used RAGAS to evaluate results (precision and recall) of both the retrieval quality as well as the answer quality, which offer a complementary perspective to the metrics used in the Microsoft study. Plotted the results below and caveat with biases.
32B) is fine-tuned to associate template metadata with their functional descriptions, ensuring it understands when and how to apply each template. accuracy on MATH , surpassing OpenAIs o1-preview by 6.7%. Hierarchical Reinforcement Learning : Structure-Based Fine-Tuning : A base LLM (e.g., Key results include: 91.2%
The tool connects Jupyter with large language models (LLMs) from various providers, including AI21, Anthropic, AWS, Cohere, and OpenAI, supported by LangChain. Moreover, it saves metadata about model-generated content, facilitating tracking of AI-generated code within the workflow.
In addition, at least for right now and at a bare minimum, you’ll also need to download: python-dotenv OpenAI sentence-transformers transformers datasets There is no need for LangChain or LlamaIndex—yet. openai==1.23.6 Payload: Additional information about the data (basically metadata). Be sure to use the same versions as I do.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content