This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
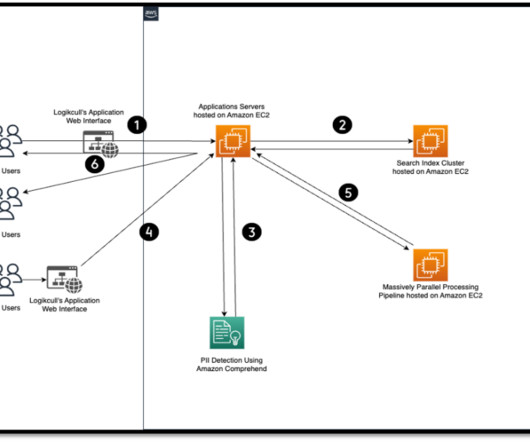
It also enables economies of scale with development velocity given that over 75 engineers at Octus already use AWS services for application development. This includes file type verification, size validation, and metadata extraction before routing to Amazon Textract.
This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption. Outside of work, he enjoys playing lawn tennis and reading books.
Her primary areas of interest encompass Deep Learning, with a focus on GenAI, Computer Vision, NLP, and time series data prediction. Ethan Cumberland is an AI Research Engineer at ZOO Digital, where he works on using AI and Machine Learning as assistive technologies to improve workflows in speech, language, and localisation.
The emergence of generative AI agents in recent years has contributed to the transformation of the AI landscape, driven by advances in large language models (LLMs) and natural language processing (NLP). The broker agent determines where to send each message based on its content or metadata, making routing decisions at runtime.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
Retailers can deliver more frictionless experiences on the go with natural language processing (NLP), real-time recommendation systems, and fraud detection. Mohammed holds a bachelor’s degree in Telecommunications Engineering from Concordia University. Instances[*]. He enjoys cooking and going on runs in New York City.
DIDACT utilizes interactions among engineers and tools to power ML models that assist Google developers, by suggesting or enhancing actions developers take — in context — while pursuing their software-engineering tasks. self-preservation or power-seeking). These datasets were generated in a few-shot manner.
Text to SQL: Using natural language to enhance query authoring SQL is a complex language that requires an understanding of databases, tables, syntaxes, and metadata. Varun Shah is a SoftwareEngineer working on Amazon SageMaker Studio at Amazon Web Services. In his free time, he enjoys playing chess and traveling.
As we look at the progression, we see that these state-of-the-art NLP models are getting larger and larger over time. From a softwareengineering perspective, machine-learning models, if you look at it in terms of the number of parameters and in terms of size, started out from the transformer models.
As we look at the progression, we see that these state-of-the-art NLP models are getting larger and larger over time. From a softwareengineering perspective, machine-learning models, if you look at it in terms of the number of parameters and in terms of size, started out from the transformer models.
Also, science projects around technologies like predictive modeling, computer vision, NLP, and several profiles like commercial proof of concepts and competitions workshops. When we speak about like NLP problems or classical ML problems with tabular data when the data can be spread in huge databases. With NLP, that’s not so easy.
I started from tech, my first job was an internship at Google as a softwareengineer. I’m from Poland, and I remember when I got an offer from Google to join as a regular softwareengineer. There’s no component that stores metadata about this feature store? It was two or three times more. How awful are they?”
Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. This extracted text is then available for further analysis and the creation of metadata, adding layout-based structure and meaning to the raw data.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. Version control for code is common in software development, and the problem is mostly solved.
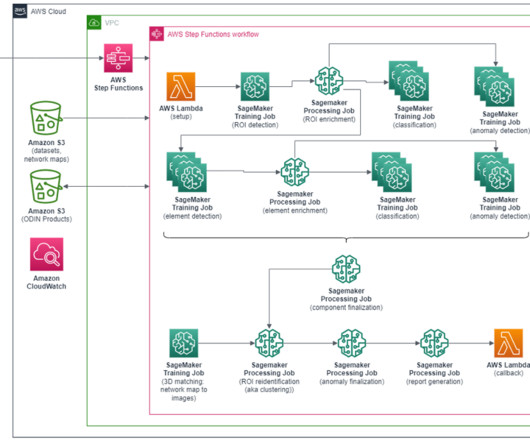
After the components (ROIs and elements) are finalized, the reidentification process begins: images and poles in the network map are matched based on 3D metadata. He has worked on projects in different domains, including MLOps, Computer Vision, NLP, and involving a broad set of AWS services.
The core challenge lies in developing data pipelines that can handle diverse data sources, the multitude of data entities in each data source, their metadata and access control information, while maintaining accuracy. As a result, they can index one time and reuse that indexed content across use cases.
About the Author of Adaptive RAG Systems: David vonThenen David is a Senior AI/ML Engineer at DigitalOcean, where hes dedicated to empowering developers to build, scale, and deploy AI/ML models in production. He brings deep expertise in building and training models for applications like NLP, data visualization, and real-time analytics.
Amazon DynamoDB : Used for storing metadata and other necessary information for quick retrieval during search operations. By using natural language processing (NLP) and machine learning algorithms, Amazon Kendra can interpret the nuances of a query, ensuring that the retrieved documents and data align closely with the user’s actual intent.
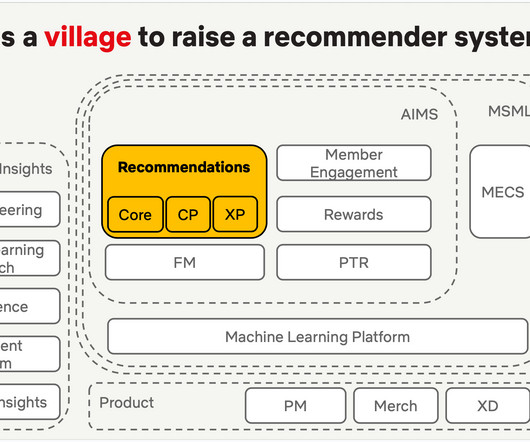
Lesson 2: Start with Baby Steps The evolution of Netflix's personalization approach has been gradual, moving from simple rating systems to more complex ranking and experience-based recommendations. However, it is still important to think the time dimension in a completely new dimension.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. According to CCNet , duplicated training examples are pervasive in common natural language processing (NLP) datasets. He carries an experience of more than a decade and a half working on entire ML and softwareengineering stack.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content