This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As generative AI continues to drive innovation across industries and our daily lives, the need for responsibleAI has become increasingly important. At AWS, we believe the long-term success of AI depends on the ability to inspire trust among users, customers, and society.
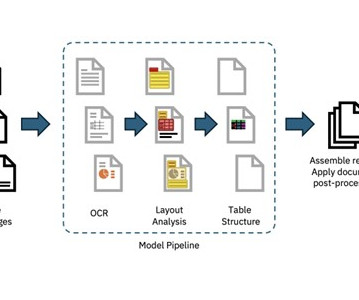
Solving this for traditional NLP problems or retrieval systems, or extracting knowledge from the documents to train models, continues to be challenging. The richness of the metadata and layout that docling captured as a structured output when processing a document sets it apart.
Participants learn to build metadata for documents containing text and images, retrieve relevant text chunks, and print citations using Multimodal RAG with Gemini. Natural Language Processing on Google Cloud This course introduces Google Cloud products and solutions for solving NLP problems.
AI governance refers to the practice of directing, managing and monitoring an organization’s AI activities. It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Monitor, catalog and govern models from anywhere across your AI’s lifecycle.
Using natural language processing (NLP) and OpenAPI specs, Amazon Bedrock Agents dynamically manages API sequences, minimizing dependency management complexities. Set up the policy documents and metadata in the data source for the knowledge base We use Amazon Bedrock Knowledge Bases to manage our documents and metadata.
Evolving Trends in Prompt Engineering for Large Language Models (LLMs) with Built-in ResponsibleAI Practices Editor’s note: Jayachandran Ramachandran and Rohit Sroch are speakers for ODSC APAC this August 22–23. As LLMs become integral to AI applications, ethical considerations take center stage.
Unlike traditional NLP models which rely on rules and annotations, LLMs like GPT-3 learn language skills in an unsupervised, self-supervised manner by predicting masked words in sentences. Their foundational nature allows them to be fine-tuned for a wide variety of downstream NLP tasks. This enables pretraining at scale.
Using machine learning (ML) and natural language processing (NLP) to automate product description generation has the potential to save manual effort and transform the way ecommerce platforms operate. jpg and the complete metadata from styles/38642.json. From here, we can fetch the image for this product from images/38642.jpg
Unlike traditional natural language processing (NLP) approaches, such as classification methods, LLMs offer greater flexibility in adapting to dynamically changing categories and improved accuracy by using pre-trained knowledge embedded within the model. The following diagram illustrates the architecture and workflow of the proposed solution.
The solution uses Amazon Bedrock , a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, providing a broad set of capabilities to build generative AI applications with security, privacy, and responsibleAI. Changsha Ma is an generative AI Specialist at AWS.
Advancements in AI and natural language processing (NLP) show promise to help lawyers with their work, but the legal industry also has valid questions around the accuracy and costs of these new techniques, as well as how customer data will be kept private and secure. In his free time, he enjoys hiking and playing with his family.
Topics Include: Advanced ML Algorithms & EnsembleMethods Hyperparameter Tuning & Model Optimization AutoML & Real-Time MLSystems Explainable AI & EthicalAI Time Series Forecasting & NLP Techniques Who Should Attend: ML Engineers, Data Scientists, and Technical Practitioners working on production-level ML solutions.
The award, totaling $299,208 for one year, will be used for research and development of LLMs for automated named entity recognition (NER), relation extraction, and ontology metadata enrichment from free-text clinical notes.
9am PT Thursday, March 6: Automated DICOM Deidentification with AWS HealthImaging (AWS booth #4624) This talk will explore John Snow Labs turnkey, regulatory grade DICOM image de-identification on AWS HealthImaging, including both metadata and pixel-level PHI, integrated with AWS HealthImaging to support compliance and scale.
Sentiment analysis and other natural language programming (NLP) tasks often start out with pre-trained NLP models and implement fine-tuning of the hyperparameters to adjust the model to changes in the environment. Prior to AWS, he led AI Enterprise Solutions at Wells Fargo.
Complete Conversation History There is another file containing the conversation history, and also including some metadata. The metadata provides information about the main data. Metadata accounts for information related to the main data, but it is not part of it.
Amazon Bedrock is a fully managed service that provides access to a range of high-performing foundation models from leading AI companies through a single API. It offers the capabilities needed to build generative AI applications with security, privacy, and responsibleAI.
At the same time, a wave of NLP startups has started to put this technology to practical use. This post takes a closer look at how the AI community is faring in this endeavour. I will be focusing on topics related to natural language processing (NLP) and African languages as these are the domains I am most familiar with.
As we look at the progression, we see that these state-of-the-art NLP models are getting larger and larger over time. The responsibleAI measures pertaining to safety and misuse and robustness are elements that need to be additionally taken into consideration. These are obviously not just focused on one task.
As we look at the progression, we see that these state-of-the-art NLP models are getting larger and larger over time. The responsibleAI measures pertaining to safety and misuse and robustness are elements that need to be additionally taken into consideration. These are obviously not just focused on one task.
It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB. What corn hybrids do you suggest for my field?”.
To make that possible, your data scientists would need to store enough details about the environment the model was created in and the related metadata so that the model could be recreated with the same or similar outcomes. ML metadata and artifact repository. Experimentation component. Model registry.
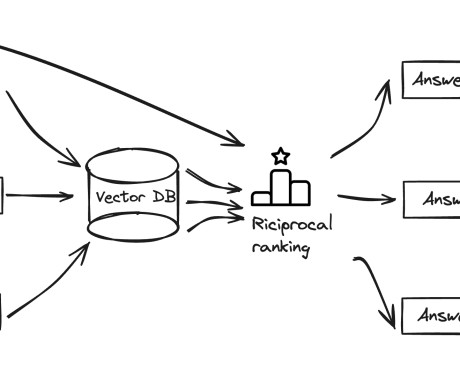
Role of metadata while indexing data in vector databases Metadata plays a crucial role when loading documents into a vector data store in Amazon Bedrock. Content categorization – Metadata can provide information about the content or category of a document, such as the subject matter, domain, or topic.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) along with a broad set of capabilities to build generative AI applications, simplifying development with security, privacy, and responsibleAI. If you haven’t done this yet, see to the prerequisites section for instructions.
Common patterns for filtering data include: Filtering on metadata such as the document name or URL. According to CCNet , duplicated training examples are pervasive in common natural language processing (NLP) datasets. Non-textual elements such as HTML tags and non-UTF-8 characters are typically removed or normalized.
We organize all of the trending information in your field so you don't have to. Join 15,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content